







本篇对应全书第二章,讲的是感知机。感知机(perceptron)是二类分类的线性分类模型,对应于输入空间(特征空间)中将数据进行线性划分的分离超平面,属于判别模型。感知机1957年由Rosenblatt提出,是神经网络与支持向量机的基础。
1、理论讲解
1.1、感知机模型
假设输入空间(特征空间)是
⊆Rn
X
⊆
R
n
,输出空间是
={1,−1}
Y
=
{
1
,
−
1
}
。输入
x∈
x
∈
X
表示实例的特征向量,对应于输入空间(特征空间)的点;输出
y∈
y
∈
Y
表示实例的类别。由输入空间到输出空间的如下函数
称为感知机。其中, w w 和为感知机模型参数, w∈Rn w ∈ R n 叫作权值向量(weight vector), b∈R b ∈ R 叫作偏置(bias),sign是符号函数,即
感知机模型的假设空间是定义在特征空间中的所有线性分类模型(linear classification model)或线性分类器(linear model),即函数集合 {f|f(x)=wx+b} { f | f ( x ) = w x + b } 。
感知机有如下几何解释:线性方程
对应于特征空间 Rn R n 中的一个超平面S,其中w是超平面的法向量,b是超平面的截距。这个超平面将特征空间划分为两个部分,位于两部分的点(特征向量)分别被分为正、负两类。因此,超平面S称为分离超平面(seperating hyperplane),如图所示
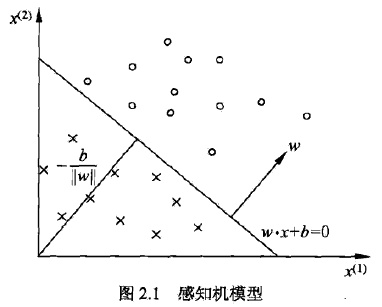
1.2、感知机学习策略
为了确定感知机模型参数w,b,需要定义(经验)损失函数并将损失函数极小化。这里选择的损失函数是所有误分类点到超平面S的总距离,假设超平面S的误分类点集合为M,那么所有误分类点到超平面S的总距离为
不考虑 1||w|| 1 | | w | | ,就得到感知机学习的损失函数
至于为什么不考虑 1||w|| 1 | | w | | ,作者没有给出进一步的解释,读者不妨阅读 参考文章1和 参考文章2。
感知机学习的策略是在假设空间中选取使损失函数最小的模型参数w,b,即感知机模型。
1.3、感知机学习算法
感知机学习算法是对以下最优化问题的算法
其中,M为误分类点的集合。
感知机学习算法是误分类驱动的,具体采用 随机梯度下降法(stochastic gradient descent)。假设误分类点集合M是固定的,那么损失函数 L(w,b) L ( w , b ) 的梯度由
给出。
1.3.1、感知机学习算法的原始形式
输入:训练数据集
T={(x1,y1),(x2,y2),…,(xN,yN)}
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
N
,
y
N
)
}
,其中
xi∈=Rn
x
i
∈
X
=
R
n
,
yi∈={−1,+1}
y
i
∈
Y
=
{
−
1
,
+
1
}
,
i=1,2,…,N
i
=
1
,
2
,
…
,
N
;学习率
η(0<η≤1)
η
(
0
<
η
≤
1
)
;
输出:w,b;感知机模型
f(x)=sign(wx+b)
f
(
x
)
=
s
i
g
n
(
w
x
+
b
)
。
(1)选取初值
w0,b0
w
0
,
b
0
(2)在训练集中选取数据
(xi,yi)
(
x
i
,
y
i
)
(3)如果
yi(wxi+b)≤0
y
i
(
w
x
i
+
b
)
≤
0
(4)转至(2),直至训练集中没有误分类点
这种学习算法直观上有如下解释:当一个实例点被误分类,即位于分离超平面的错误一侧时,则调整w,b的值,使分离超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直至超平面越过该分类点使其被正确分类。
感知机学习算法由于采用不同的初值或选取不同的误分类点,解可以不同。
1.3.2、感知机学习算法的对偶形式
输入:训练数据集
T={(x1,y1),(x2,y2),…,(xN,yN)}
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
N
,
y
N
)
}
,其中
xi∈=Rn
x
i
∈
X
=
R
n
,
yi∈={−1,+1}
y
i
∈
Y
=
{
−
1
,
+
1
}
,
i=1,2,…,N
i
=
1
,
2
,
…
,
N
;学习率
η(0<η≤1)
η
(
0
<
η
≤
1
)
;
输出:
α,b
α
,
b
;感知机模型
f(x)=sign(∑Nj=1αjyjxjx+b)
f
(
x
)
=
s
i
g
n
(
∑
j
=
1
N
α
j
y
j
x
j
x
+
b
)
。
其中,
α=(α1,α2,…,αN)
α
=
(
α
1
,
α
2
,
…
,
α
N
)
.
(1)
α←0,b←0
α
←
0
,
b
←
0
(2)在训练集中选取数据
(xi,yi)
(
x
i
,
y
i
)
(3)如果
yi(∑Nj=1αjyjxjxi+b)≤0
y
i
(
∑
j
=
1
N
α
j
y
j
x
j
x
i
+
b
)
≤
0
(4)转至(2)直到没有误分类数据
对偶形式中训练实例仅以内积的形式出现,为了方便,可以预先将训练集中实例间的内积计算出来并以矩阵形式存储,这个矩阵就是所谓的Gram矩阵(Gram matrix)
1.3.3、总结
当训练数据集线性可分时,感知机学习算法是收敛的;否则,感知机学习算法不收敛,迭代结果会发生震荡。
2、代码实现
2.1、手工实现
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from random import shuffle
from sklearn.model_selection import train_test_split
class Perceptron:
def __init__(self, X_train, y_train, lr = 0.1):
self.X_train = X_train
self.y_train = y_train
self.w = np.zeros(self.X_train.shape[1])
self.b = 0
self.lr = lr
def fit(self):
iter_flag = True
while iter_flag:
train_set = zip(self.X_train, self.y_train)
shuffle(train_set)
for X_i, y_i in train_set:
if y_i * (np.dot(self.w, X_i) + self.b) <= 0:
self.w += self.lr * np.dot(X_i, y_i)
self.b += self.lr * y_i
break
else:
iter_flag = False
print "Perceptron OK!"
def predict(self, X_test):
label_list = []
for X in X_test:
label = np.sign(np.dot(self.w, X) + self.b)
label = label if label else -1
label_list.append(label)
return np.array(label_list)
def score(self, X_test, y_test):
total_num = len(X_test)
pre = (self.predict(X_test) == y_test).sum()
score = pre/total_num
return score
if __name__ == "__main__":
iris = load_iris()
X = iris.data[:100, :2]
y = iris.target[:100]
y[y == 0] = -1
xlabel = iris.feature_names[0]
ylabel = iris.feature_names[1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
X_0 = X_train[y_train == -1]
X_1 = X_train[y_train == 1]
plt.figure("perceptron-mine")
plt.scatter(X_0[:, 0], X_0[:, 1], label = '-1')
plt.scatter(X_1[:, 0], X_1[:, 1], label = '1')
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.legend()
clf = Perceptron(X, y)
clf.fit()
score = clf.score(X_test, y_test)
print "score : %s" % score
y_pre = clf.predict(X_test)
X_test_pre_0 = X_test[y_pre == -1]
X_test_pre_1 = X_test[y_pre == 1]
plt.scatter(X_test_pre_0[:, 0], X_test_pre_0[:, 1], color = 'r', label = 'pre -1')
plt.scatter(X_test_pre_1[:, 0], X_test_pre_1[:, 1], color = 'k', label = 'pre 1')
plt.legend()
X_simul = np.arange(4, 8)
y_simul = -(clf.w[0] * X_simul + clf.b)/clf.w[1]
plt.plot(X_simul, y_simul, color = 'g', label = 'model')
plt.legend()
plt.show()
2.2、sklearn实现
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
from sklearn.model_selection import train_test_split
if __name__ == "__main__":
iris = load_iris()
X = iris.data[:100, :2]
y = iris.target[:100]
y[y == 0] = -1
xlabel = iris.feature_names[0]
ylabel = iris.feature_names[1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
X_0 = X_train[y_train == -1]
X_1 = X_train[y_train == 1]
plt.figure("perceptron-sklearn")
plt.scatter(X_0[:, 0], X_0[:, 1], label = '-1')
plt.scatter(X_1[:, 0], X_1[:, 1], label = '1')
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.legend()
clf = Perceptron(max_iter = 1000)
clf.fit(X, y)
score = clf.score(X_test, y_test)
print "score : %s" % score
y_pre = clf.predict(X_test)
X_test_pre_0 = X_test[y_pre == -1]
X_test_pre_1 = X_test[y_pre == 1]
plt.scatter(X_test_pre_0[:, 0], X_test_pre_0[:, 1], color = 'r', label = 'pre -1')
plt.scatter(X_test_pre_1[:, 0], X_test_pre_1[:, 1], color = 'k', label = 'pre 1')
plt.legend()
X_simul = np.arange(4, 8)
y_simul = -(clf.coef_[0, 0] * X_simul + clf.intercept_)/clf.coef_[0, 1]
plt.plot(X_simul, y_simul, color = 'g', label = 'model')
plt.legend()
plt.show()
代码已上传至github:https://github.com/xiongzwfire/statistical-learning-method
参考文献
[1] http://blog.csdn.net/lyg1112/article/details/52572405
[2] https://github.com/wzyonggege/statistical-learning-method
以上为本文的全部参考文献,对原作者表示感谢。














 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









