







cogroup:对两个RDD中的KV元素,每个RDD中相同key中的元素分别聚合成一个集合。与reduceByKey不同的是针对两个RDD中相同的key的元素进行合并。
测试例子1
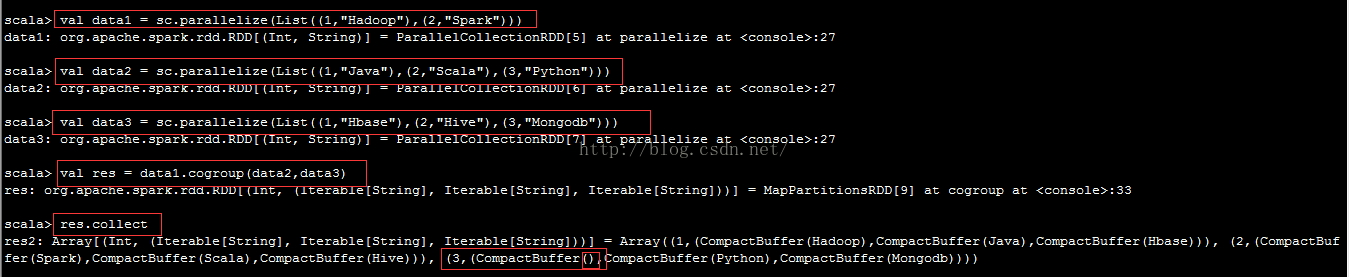
将多个RDD中同一个Key对应的Value组合到一起。
data1中不存在Key为3的元素(自然就不存在Value了),在组合的过程中将data1对应的位置设置为CompactBuffer()了,而不是去掉了。
测试例子2
<span style="font-size:18px;">val DBName=Array(
Tuple2(1,"Spark"),
Tuple2(2,"Hadoop"),
Tuple2(3,"Kylin"),
Tuple2(4,"Flink")
)
val numType=Array(
Tuple2(1,"String"),
Tuple2(2,"int"),
Tuple2(3,"byte"),
Tuple2(4,"bollean"),
Tuple2(5,"float"),
Tuple2(1,"34"),
Tuple2(1,"45"),
Tuple2(2,"47"),
Tuple2(3,"75"),
Tuple2(4,"95"),
Tuple2(5,"16"),
Tuple2(1,"85")
)
val names=sc.parallelize(DBName)
val types=sc.parallelize(numType)
val nameAndType=names.cogroup(types) //基于key进行join 结果并没有顺序
nameAndType.collect.foreach(println)</span>
输出结果:
<span style="font-size:18px;">(4,(CompactBuffer(Flink),CompactBuffer(bollean, 95)))
(1,(CompactBuffer(Spark),CompactBuffer(String, 34, 45, 85)))
(3,(CompactBuffer(Kylin),CompactBuffer(byte, 75)))
(5,(CompactBuffer(),CompactBuffer(float, 16)))
(2,(CompactBuffer(Hadoop),CompactBuffer(int, 47)))</span>














 2896
2896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









