









ID3决策树主要是用来进行分类,它的主要做法还是比较简单的,但是基于是递归的建树,所以写起代码来不是那么好写,它的做法大概是:
对于初始样本,选择一个最优的feature(怎么样算是最优,下面会解释),将一个点根据这个feature的不同取值,分成不同的分支,也就是说feature取几个值,就有几个分支,然后递归它的每一个分支,直到达到某些条件则停止递归。
这里要说明的是2点,
1 怎么选择最优的属性
这涉及到信息论的知识,我们可以把分类过程看做熵减少的过程,对于初始的样本有一个熵,然后按照不同的分支分类后,也会得到一个熵,我们要求的就是使得熵减少最多的这个feature。至于如何计算熵,有:
其中k表示类的个数。
而用分类前的熵减去按照分支分类后的熵总和,有:
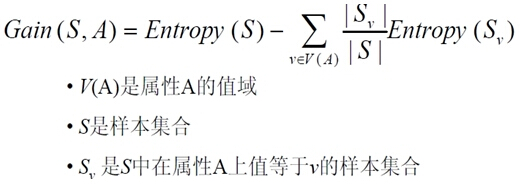
通俗的说,就是枚举某个属性A的所有值,根据这个值分成很多个子集,然后熵的和就是每一个子集熵乘以所占比重的和。
2 怎么判断停止递归
一种比较直观的办法,当前节点的样本类别都是相同的时候,可以不用递归,但是很多情况下,这样的做法会造成过拟合。还有就是当这个点的样本个数小于某个阀值,或者所有的属性都被分过了,其实停止递归也涉及到决策树的剪枝问题。
ID3决策树有两个局限性,第一就是使用的是熵增益,这个值有时候不能很好表示熵改变的情况,比如从3变到1,从1000变到998都是变化了2,但是明显是第一种情况变化的更多。第二个局限性是,ID3不能够没办法处理拥有连续值的feature,而C4.5能够较好的解决这两个问题。
C4.5和ID3建树的思想基本一致,只是用增益率代替了增益来衡量最优feature。
首先C4.5计算增益率的公式是:

其实个人对于这个增益率的理解还是和公式有一些的不同,个人觉得如果单从这个“率”来说,分母应该就是Gain(S,A)这个式子的减号后的那部分或者直接是Entropy(S),但是根据C4.5的定义不是按照每个类将这个点上的样本分开来计算,而是按照这个feature的不同取值将这个点上的样本分开来计算。
其次对于连续值的情况,假如所有的样本总共出现了n个值,C4.5所采用的办法就是,取这n个数间的n-1个间隔,对于每个间隔为分界点计算一次增益率(可以发现这样一定只是产生2个分支),求出最好的分界。

这幅图较好的解释了这个做法,将temperature排序后,我只需要划红线的界,因为界的两侧属于不同的类别,这在一定程度上能减小计算。
本文讲的太过粗浅,决策树比较重要的剪枝理论,有待研究学习下。















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









