







前几天一朋友托我做一个小功能,因为工作量不大,而且这种功能我之前做过,所以就答应了。我先大概交代一下业务场景:朋友需要一些数据做数据挖掘的测试数据,然后他跟我说了一些网站的数据他比较感兴趣,让我写个小程序获取这些数据。下面我谈谈我在完成这个小功能上面的一些思考和实践:
第一阶段:完成功能:
| 先琢磨网站URL的组成规则,把自己的查询条件跟网站URL的参数对应上。然后写一个main方法,使用java里面的URL对象请求到数据。 |
第二阶段:使用多线程提高性能:
| 一个线程循环请求网络资源,然后再解析获取到的数据效率比较低。最先想到的办法就是使用多线程同时去请求。 |
第三阶段:根据功能不同解耦
仔细分析这个业务,其实主要分成两部分:网络请求、CPU解析。但是在以上的解决方案中,每个线程都承担了两种不同的职责,其主要缺点我觉得有如下几种:
1、因为网络请求和数据解析耦合,不便于扩展其中任何一个功能。
2、因为这两个业务需要的硬件资源不同,分开处理便于高效实用硬件资源。
分析了利弊之后,下面是我的整体思路:
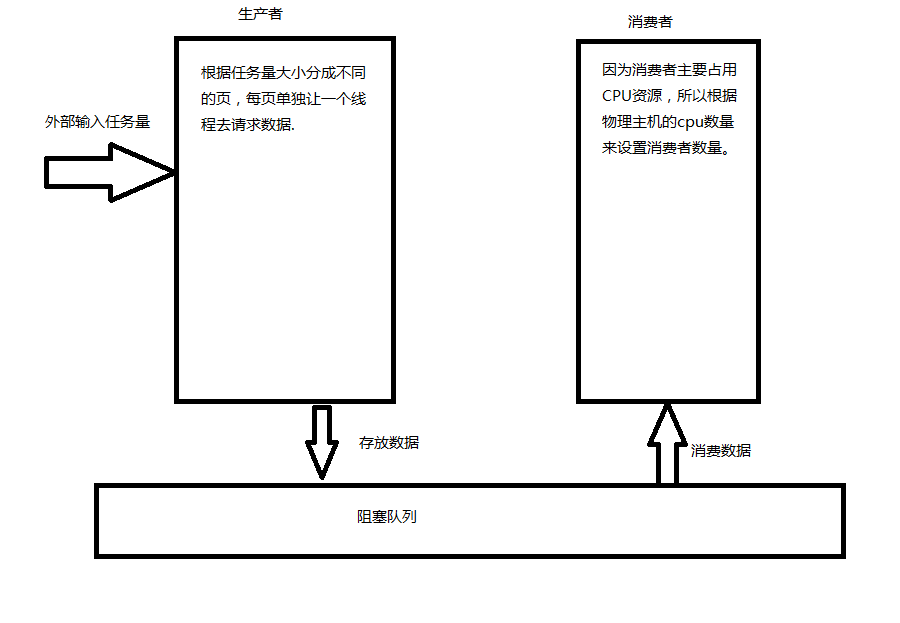
因为网络请求主要消耗IO,所以这里可以适当多增加一些生产者。对于消费者,为了避免频繁的线程切换,这里把消费者数量设置跟物理主机CPU数据相同便可。
经过这么一番思考优化,对于1000条数据量性能提升了20多倍。在这个实践过程中,思考的过程每一步都让我兴奋。其实这个过程就跟平时大家干活一样,就拿卸货来说吧。有人得从车上把货物卸下来,有人就得及时把卸下来的货物运到目的地。















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









