







详细过程见:
http://blog.csdn.net/u013405574/article/details/50903987
#include "iostream"
#include "vector"
#include "string.h"
#include "time.h"
#include "stdlib.h"
#include "stdio.h"
using namespace std;
#define N 6
double Q[N][N]; //状态-动作值函数
double gamma = 0.8; //折算因子
int finalState = 5; //最终状态
int epoches = N; //训练次数
//回报
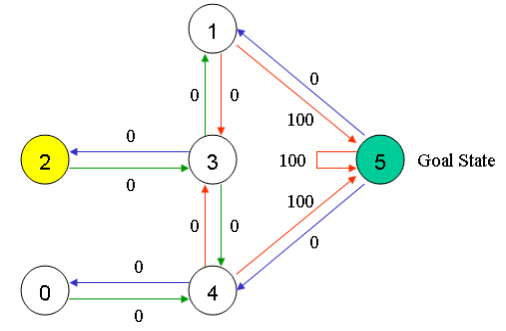
double R[N][N] =
{
{-1, -1, -1, -1, 0, -1},
{-1, -1, -1, 0, -1, 100},
{-1, -1, -1, 0, -1, -1},
{-1, 0, 0, -1, 0, -1},
{ 0, -1, -1, 0, -1, 100},
{-1, 0, -1, -1, 0, 100}
};
void RL()
{
//初始化Q矩阵为0
memset(Q, 0, sizeof(Q));
int i, j;
for(i=0; i<N; i++)
if(R[finalState][i] >= 0)
Q[finalState][i] = R[finalState][i];
int epoch = 0;
while(epoch++ < epoches) //训练次数
{
int nowState = rand() % N; //随机选择一个初始状态
int step = 0;
while(step++ < N) //如果没有走完
{
vector<int> nextAction;
for(i=0; i<N; i++)
{
if(R[nowState][i] >= 0) //下一个可能的动作
{
nextAction.push_back(i);
}
}
int ns = nextAction[ rand() % nextAction.size() ]; //随机选择到达下一个状态的动作
double nextQmax = Q[ns][0];
for(i=1; i<N; i++) //搜寻下一个状态的最大Q值
{
if(Q[ns][i] > nextQmax)
{
nextQmax = Q[ns][i];
}
}
//最为核心的地方:
//Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q[nowState][ns] = R[nowState][ns] + gamma * nextQmax;
nowState = ns; //更新当前状态
}
//为了使Q值不要太大
if(epoch % 10 == 0)
{
double min = 10000;
for(i=0; i<N; i++)
{
for(j=0; j<N; j++)
if(Q[i][j] < min && Q[i][j] > 0)
min = Q[i][j];
}
for(i=0; i<N; i++)
{
for(j=0; j<N; j++)
Q[i][j] /= min;
}
}
}
}
void printSolution(int startState)
{
while(startState < finalState)
{
cout << startState << "-->";
double maxQnext = -1;
int nextAction = 0;
for(int i=0; i<N; i++)
{
if(R[startState][i] >= 0) //如果下一个状态可达
{
if(Q[startState][i] > maxQnext)
{
maxQnext = Q[startState][i];
nextAction = i;
}
}
}
//cout << nextAction;
startState = nextAction;
}
cout << finalState << endl;
}
int main()
{
srand(time(NULL));
RL();
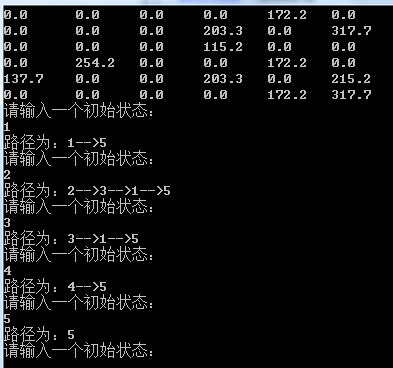
for(int i=0; i<N; i++)
{
for(int j=0; j<N; j++)
printf("%.1f\t ", Q[i][j]);
cout << endl;
}
while(1)
{
cout << "请输入一个初始状态:" << endl;
int startState;
cin >> startState;
cout << "路径为:";
printSolution(startState);
}
return 0;
}
参考
[1] http://blog.csdn.net/u013405574/article/details/50903987
[2] http://www.cnblogs.com/Leo_wl/p/5852010.html















 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









