







 本文深入探讨了Seq2Seq模型及其在自然语言处理任务中的应用,详细讲解了Encoder-Decoder架构,尤其是四层LSTM结构如何提高模型性能。同时,文章介绍了不同Seq2Seq模式,并重点解析了Attention机制的引入过程及其实现步骤,强调其在处理序列到序列任务中的关键作用。
本文深入探讨了Seq2Seq模型及其在自然语言处理任务中的应用,详细讲解了Encoder-Decoder架构,尤其是四层LSTM结构如何提高模型性能。同时,文章介绍了不同Seq2Seq模式,并重点解析了Attention机制的引入过程及其实现步骤,强调其在处理序列到序列任务中的关键作用。
NLP(2) | 中文分词分词的概念分词方法分类CRFHMM分词
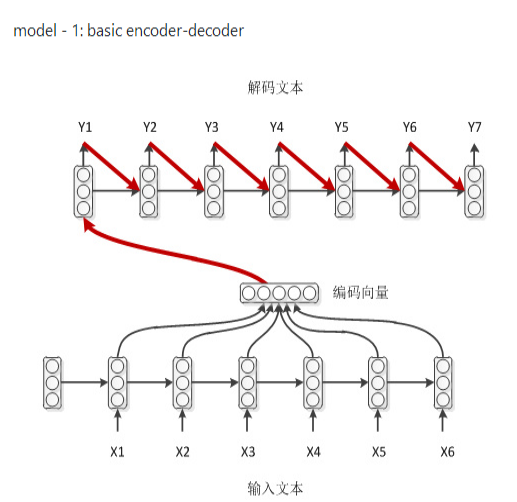
- 什么是Seq2Seq网络? 在Seq2Seq模型中采用了这种 Encoder-Decoder架构,其中 Encoder 是一个RNNCell(RNN ,GRU,LSTM 等) 结构,四层的LSTM结构使得能够提取足够多的特征,使得decode的模型变好
- 几种Seq2Seq模式
1.学霸模式
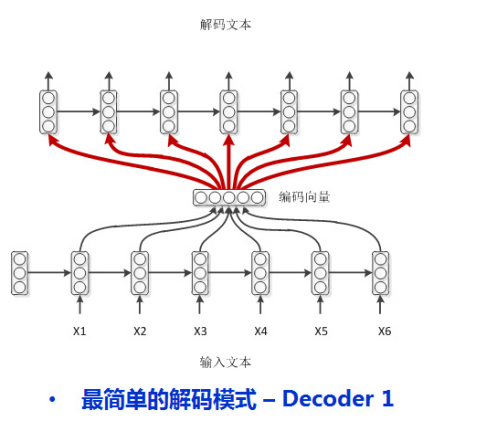
2.普通作弊
3.学弱作弊
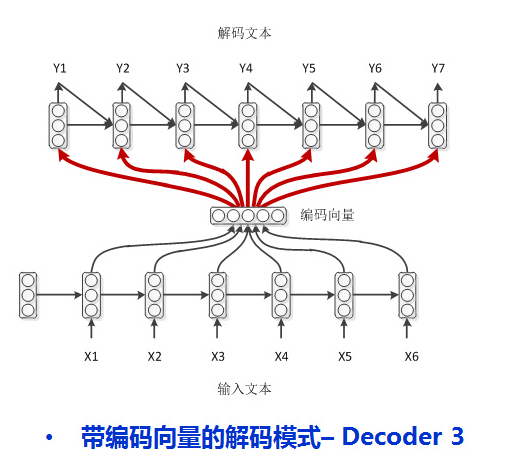
普通作弊的基础上,回顾上一刻的答案
4.学渣作弊(attention机制)
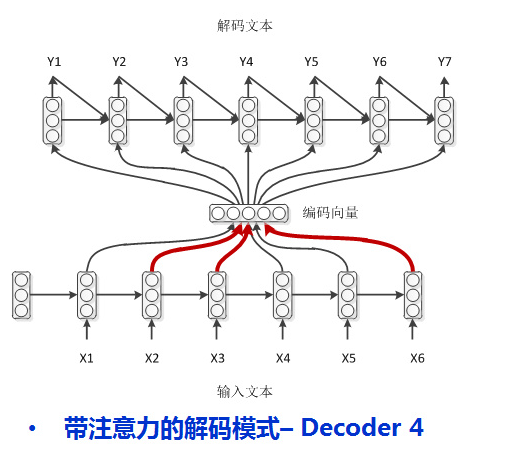
上课的时候划重点
- 应用场景 只要是序列到序列都可以用
- attention机制是怎么引入的?
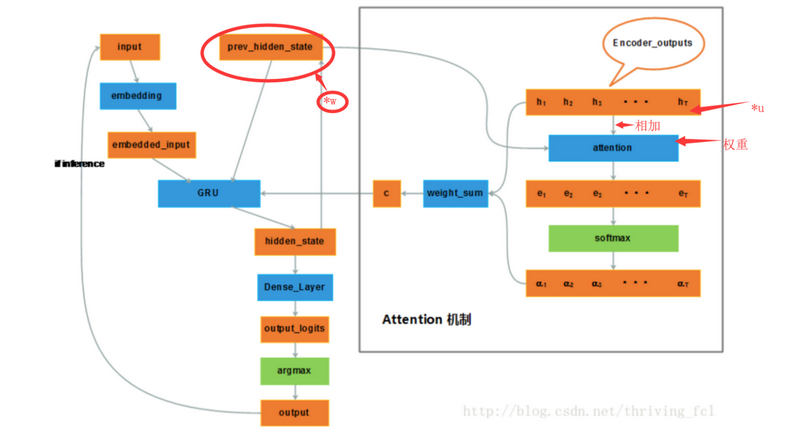
第一步
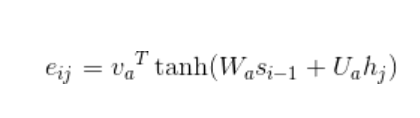
第二步:
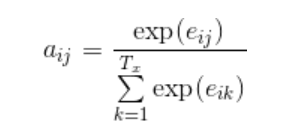
第三步:
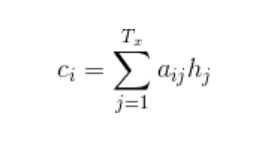
seqtoseq损失函数
损失函数为交叉熵损失函数,一般情况下,深度学习最后用softmax最为分类器一般都会选择用交叉熵损失函数
参考
https://cloud.tencent.com/developer/article/1163104

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









