







IKAnalyzer词典扩充
最近工作使用到lucene,需要对中文分词,分词器是IKAnalyzer,自带的词典包含了27万词条,能满足一般的分词要求,但是如果应用到特定的专业领域,还需要扩展专业词库,以达到更好的分词效果:
IKAnalyzer分词API
IKAnalyzer analyzer=new IKAnalyzer(true);
TokenStream ts=null;
try{
ts=analyzer.tokenStream("title", "星际屌丝,品牌,产量,商业销量,工商库存,累计,上年同期,同比,合计,中华,利群,芙蓉王,黄鹤楼,苏烟,娇子,玉溪,贵烟,云烟,白沙,黄山,南京,黄金叶,真龙,双喜·红双喜,七匹狼,金圣,红河");
CharTermAttribute cta=ts.addAttribute(CharTermAttribute.class);
ts.reset();
int count=0;
while (ts.incrementToken()) {
count++;
System.out.println("term: " + cta.toString());
}
System.out.println("total:"+count);
}catch(Exception e){
e.printStackTrace();
}finally{
if(ts!=null)
try{
ts.close();
}catch(Exception e){
e.printStackTrace();
}
if(analyzer!=null){
try{
analyzer.close();
}catch(Exception e){
e.printStackTrace();
}
}
}首先IKAnalyzer analyzer=new IKAnalyzer(true);构造一个IKAnalyzer对象,构造器参数为true说明使用智能分词,默认为最细粒度切分,下面是两种模式的分词效果:
1.智能分词
term: 屌
term: 丝
term: 品牌
term: 产量
term: 商业
term: 销量
term: 工商
term: 库存
term: 累计
term: 上年
term: 同期
term: 同比
term: 合计
term: 中华
term: 利
term: 群
term: 芙蓉王
term: 黄鹤楼
term: 苏
term: 烟
term: 娇
term: 子
term: 玉溪
term: 贵
term: 烟
term: 云烟
term: 白沙
term: 黄山
term: 南京
term: 黄
term: 金叶
term: 真
term: 龙
term: 双喜
term: 红双喜
term: 七匹
term: 狼
term: 金
term: 圣
term: 红河
total:41
2.最细粒度切分
term: 星际
term: 屌
term: 丝
term: 品牌
term: 产量
term: 商业
term: 销量
term: 工商
term: 库存
term: 累计
term: 上年
term: 同期
term: 同比
term: 合计
term: 中华
term: 利
term: 群
term: 芙蓉王
term: 芙蓉
term: 王
term: 黄鹤楼
term: 黄鹤
term: 楼
term: 苏
term: 烟
term: 娇
term: 子
term: 玉溪
term: 贵
term: 烟
term: 云烟
term: 白沙
term: 黄山
term: 南京
term: 黄金
term: 金叶
term: 真
term: 龙
term: 双喜
term: 红双喜
term: 双喜
term: 七
term: 匹
term: 狼
term: 金
term: 圣
term: 红河
total:47
IKAnalyzer.tokenStream(fieldName,text)返回TokenStream对象,Token指分词后的词元,TokenStream对象中包含了text的分词结果,fieldName指文档的域名,一片文档包含多个域,如title,abstract,content等等,这里任意指定即可。
TokenStream.incrementToken()的功能相当于迭代器,用来遍历每个词元。
CharTermAttribute是具体的词元对象,每次调用incrementToken()方法后,该对象所持有的词元会更新。
词库扩展
通过上面的输出结果可以看出,如果使用IKAnalyzer自带的词典,两种分词模式的效果都不理想,所以要扩展词库。扩展词库一共有两种方法,一种方法是添加词典文件,另一种是通过IKAnalyzer自带的API实现动态扩展。
通过配置文件扩展词典
下面的内容来自IKAnalyzer自带的文档,说的比较清楚:
IK 分词器还支持通过配置 IKAnalyzer.cfg.xml 文件来扩充您的与有词典以及停止词典(过滤词典)。
1. 部署 IKAnalyzer.cfg.xml
IKAnalyzer.cfg.xml 部 署 在 代 码 根 目 彔 下 ( 对 亍 web 项 目 , 通 常 是WEB-INF/classes 目彔)同 hibernate、log4j 等配置文件相同。
2. 词典文件的编辑与部署
分词器的词典文件格式是无 BOM 的 UTF-8 编码的中文文本文件,文件扩展名不限。词典中,每个中文词汇独立占一行,使用\r\n 的 DOS 方式换行。(注,如果您不了解什么是无 BOM 的 UTF-8 格式, 请保证您的词典使用 UTF-8 存储,并在文件的头部添加一空行)。您可以参考分词器源码 org.wltea.analyzer.dic 包下的.dic 文件。
词典文件应部署在 Java 的资源路径下,即 ClassLoader 能够加载的路径中。(推荐同 IKAnalyzer.cfg.xml 放在一起)
3. IKAnalyzer.cfg.xml 文件的配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">/mydict.dic;
/com/mycompany/dic/mydict2.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">/ext_stopword.dic</entry>
</properties> 在配置文件中,用户可一次配置多个词典文件。文件名使用“;”号分隔。文件路径为相对 java 包的起始根路径。
注意:配置文件和字典文件都放在java包的根目录,上述配置文件的字典路径应该去掉开头的”/”,否则扩展无法生效。
将卷烟品牌填入扩展词典文件后,下面是扩展词典后的分词结果:
term: 星际
term: 屌丝
term: 品牌
term: 产量
term: 商业
term: 销量
term: 工商
term: 库存
term: 累计
term: 上年
term: 同期
term: 同比
term: 合计
term: 中华
term: 利群
term: 芙蓉王
term: 黄鹤楼
term: 苏烟
term: 娇子
term: 玉溪
term: 贵烟
term: 云烟
term: 白沙
term: 黄山
term: 南京
term: 黄金叶
term: 真龙
term: 双喜
term: 红双喜
term: 七匹狼
term: 金圣
term: 红河
total:32
可以看到卷烟品牌被正确识别。
通过API扩展词典
IK 分词器支持使用 API 编程模型扩充您的词典和停止词典。如果您的个性化词典是存储与数据库中,这个方式应该对您适用。API 如下:
类 org.wltea.analyzer.dic.Dictionary
说明: IK 分词器的词典对象。它负责中文词汇的加载,内存管理和匹配检索。
public static Dictionary initial(Configuration cfg)
说明:初始化字典实例。字典采用单例模式,一旦初始化,实例就固定.
PS:注意该方法只能调用一次。
参数 1:Configuration cfg , 词典路径配置
返回值:Dictionary IK 词典单例
public static Dictionary getSingleton()
说明:获取初始化完毕的字典单例
返回值:Dictionary IK 词典单例
public void addWords(Collection<String> words)
说明:加载用户扩展的词汇列表到 IK 的主词典中,增加分词器的可识别词语。
参数 1:Collection<String> words , 扩展的词汇列表
返回值:无
public void disableWords(Collection<String> words)
说明:屏蔽词典中的词元
参数 1:Collection<String> words, 待删除的词列表
返回值:无
上述内容同样来自官方文档。这里注意:这套API对字典的扩充只是运行时的,只会对内存中的字典对象进行扩充,不会影响到磁盘上的词典文件,这点在文档中没有特别说明。
下面定义一个类实现词典扩展,向字典添加”星际屌丝“:
public class DicUtil {
public static void extendDic(){
Configuration cfg=DefaultConfig.getInstance();
System.out.println(cfg.getMainDictionary());
Dictionary.initial(cfg);
Dictionary dic=Dictionary.getSingleton();
HashSet<String> set=new HashSet<>();
set.add("星际屌丝");
dic.addWords(set);
}
}
下面调用extendDic()后再次分词:
DicUtil.extendDic();//扩充词典
IKAnalyzer analyzer=new IKAnalyzer(true);
TokenStream ts=null;
try{
ts=analyzer.tokenStream("title", "星际屌丝,品牌,产量,商业销量,工商库存,累计,上年同期,同比,合计,中华,利群,芙蓉王,黄鹤楼,苏烟,娇子,玉溪,贵烟,云烟,白沙,黄山,南京,黄金叶,真龙,双喜·红双喜,七匹狼,金圣,红河");
CharTermAttribute cta=ts.addAttribute(CharTermAttribute.class);
ts.reset();
int count=0;
while (ts.incrementToken()) {
count++;
System.out.println("term: " + cta.toString());
}
System.out.println("total:"+count);
}catch(Exception e){
e.printStackTrace();
}finally{
if(ts!=null)
try{
ts.close();
}catch(Exception e){
e.printStackTrace();
}
if(analyzer!=null){
try{
analyzer.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
}下面是输出结果:
term: 星际屌丝
term: 品牌
term: 产量
term: 商业
term: 销量
term: 工商
term: 库存
term: 累计
term: 上年
term: 同期
term: 同比
term: 合计
term: 中华
term: 利群
term: 芙蓉王
term: 黄鹤楼
term: 苏烟
term: 娇子
term: 玉溪
term: 贵烟
term: 云烟
term: 白沙
term: 黄山
term: 南京
term: 黄金叶
term: 真龙
term: 双喜
term: 红双喜
term: 七匹狼
term: 金圣
term: 红河
total:31
可以看到,”星际屌丝“作为一个独立的词元被切分出来。Dictionary作为一个单实例也即静态变量对全局产生影响。
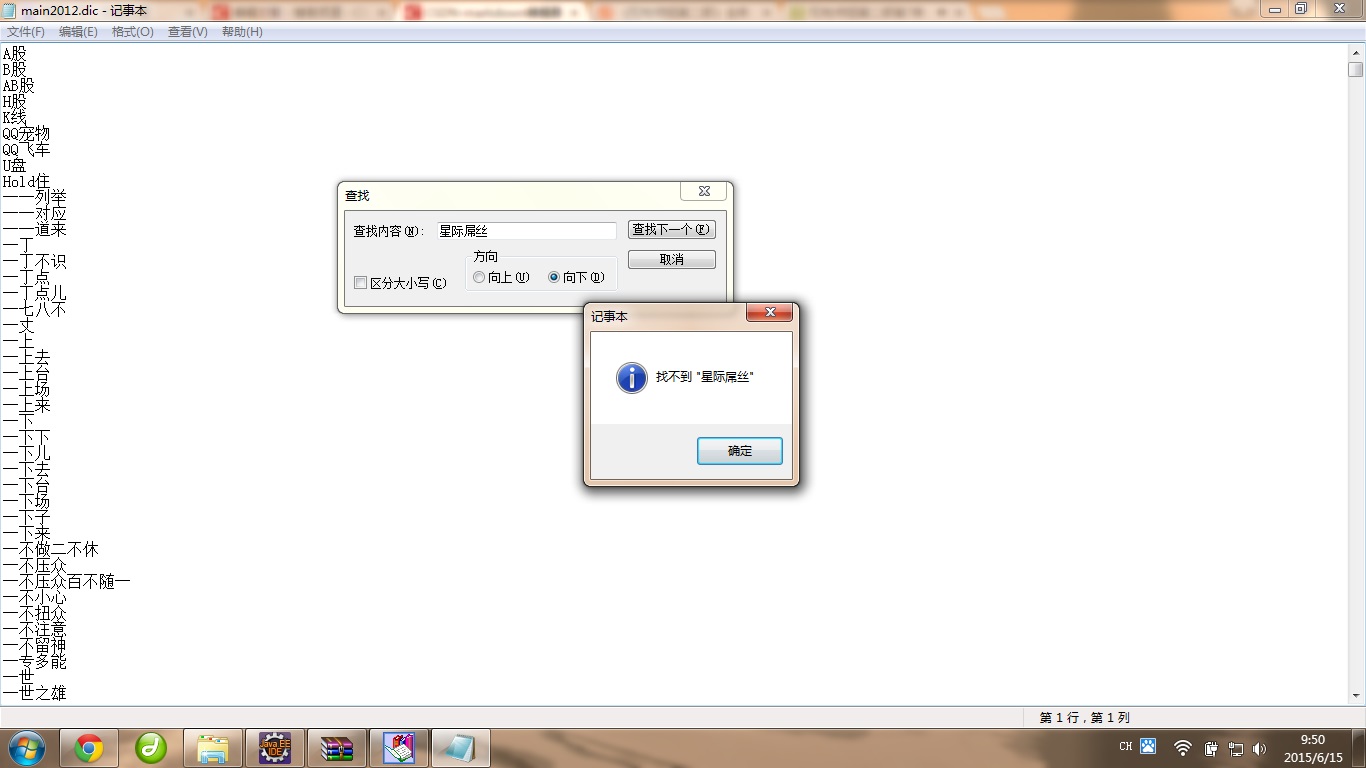
但是我们打开主词典文件,查找”星际屌丝“不会找到,因为这套API是面向内存扩充词典,不会改变磁盘文件。

















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









