







最近重新装了系统,需要对spark与pyspark重新配置下。于是写了这篇文章,希望对从事这个行业的人员能有所帮助:
01_windows10配置spark与pyspark
02_jupyterLab_windows设置pyspark
03_jupyternotebook_windows设置pyspark
1.准备阶段
准备以下版本的安装包,不同的版本号之间会发生兼容性问题,如果采用版本以下不一致,建议看完本文再动手,有些本人已经踩过坑,会在下文提示。
1.Anaconda3-2021.11-Windows-x86_64
2.jdk-8u40-windows-x64
3.hadoop-3.2.2.tar.gz
4.scala-2.12.15
5.spark-3.1.3-bin-hadoop3.2.tgz
6.winutils来源于hadoop-3.2.2或者hadoop-3.2.1
整理安装包放在文章《windows10配置spark与pyspark》安装包01 与 文章《windows10配置spark与pyspark》安装包02
2.Anaconda3 安装
2.1 用户选择
这里选择为所有用户安装

2.2 安装路径
不要放在C盘,接下来几个文件的安装需要一定的空间,多数人的电脑C盘不够大
我安装在H盘,建立一个文件架子

2.3 环境变量和版本号

这里两个地方都打√,上边是添加环境变量,这样就省去了添加环境变量的麻烦;下边是让anaconda设置为Python3。勾选完,我们点install安装吧。
2.4 测试
安装我完,我们测试一下安装结果,找到运行,输入cmd.

3.Java 安装
3.1安装内容和路径
a.安装内容选择 开发者具
b.推荐修改java 安装路径,点击下图中的更爱…选择自定义的安装路径,若无需修改,next即可。
 我的安装路径如下:
我的安装路径如下:

3.2 配置环境变量
计算机→系统属性→相关设置→⾼级系统设置→⾼级→环境变量,在系统变量中配置。




找到上面环境变量路径后添加JAVA_HOME路径

添加path路径


3.3 测试
cmd 命令行窗口输入 java
 cmd 命令行窗口输入 java -version
cmd 命令行窗口输入 java -version

cmd 命令行窗口输入 javac

4.scala 安装
4.1 选型与路径修改
选择第一个,安装路径建议修改:

我的安装路径如下:

4.2 环境变量配置
参考java环境变量配置:
SCALA_HOME配置

path配置

5.hadoop配置
5.1 文件加压缩和位置放置
对hadoop-3.2.2.tar.gz进行两次解压缩,第一次解压后有文件hadoop-3.2.2.tar,再次解压缩后如下图:
注意:hadoop-3.2.2解压后放在盘的根目录下,如下如文件夹hadoop-3.2.2与H盘之间没有经过文件夹

5.2 Hadoop环境变量配置
step01.HADOOP_HOME配置

step02.path配置

6.SPARK配置
6.1 文件加压缩和位置放置
对spark-3.1.3-bin-hadoop3.2.tgz进行解压缩,再次解压缩后如下图:
注意:对spark-3.1.3-bin-hadoop3.2解压后放在盘的根目录下,如下如文件夹对spark-3.1.3-bin-hadoop3.2与H盘之间没有经过文件夹

6.2 SPARK环境变量配置
step01.SPARK_HOME配置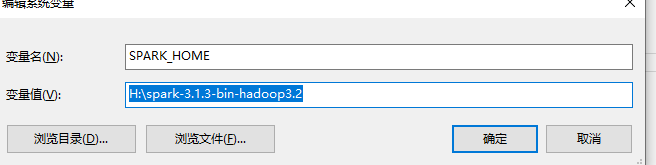
step02.path配置

7.pyspark 配置
1.安装pyspark
cmd 命令行输入以下:
pip install pyspark - i https://pypi.tuna.tsinghua.edu.cn/simple
2.替换pyspark
将spark-3.1.3-bin-hadoop3.2\python下的pyspark拷贝到
Anaconda3\Lib\site-packages,替换Anaconda3\Lib\site-packages的pyspark

本人先将Anaconda3\Lib\site-packages的pyspark重名为pyspark01,然后拷贝spark-3.1.3-bin-hadoop3.2\python下的pysparkpyspark

8.配置winutils
将winutils.exe 拷贝到 hadoop-3.2.2\bin目录下:

9.检验配置结果
9.1 检验pyspark
cmd 命令行窗口 输入pyspark

9.2 检验spark
cmd 命令行窗口输入spark-shell



















 1263
1263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











