







一.【前言】
最近在用spark作练习因此需要安装pyspark,摸索了一阵子在win10、win7下都已安装成功,所以写点东西下来,给还在摸索的小伙伴一点帮助。
二.【工具准备】
1,jdk1.8
2,spark-2.2.0-bin-dadoop2.7
3,hadoop-2.7.1.tar
4,winutils
具体如下:
1. Java: JDK 8u121 with NetBeans 8.2,你也可以下载单独的JDK 8u121,不带有IDE NetBeans 8.2
http://www.oracle.com/technetwork/java/javase/downloads/jdk-netbeans-jsp-142931.html

2.spark: spark-2.2.0-bin-hadoop2.7
https://spark.apache.org/downloads.html

3.winutils.exe: 用于改变文件或文件夹读写权限的工具,本文下载的是针对Hadoop-2.7.4的64位的winutils.exe
https://github.com/steveloughran/winutils/tree/master/hadoop-2.6.4/bin

4.hadoop-2.7.1可到官网自行下载,或是从下文中分享文件中获得
三.【安装及系统环境变量设置】
jdk的安装就不说了。
Hadoop和Spark解压就可以,但是注意的是要确保解压的路径中不包含空格!
然后是配置环境变量
环境变量设置截图


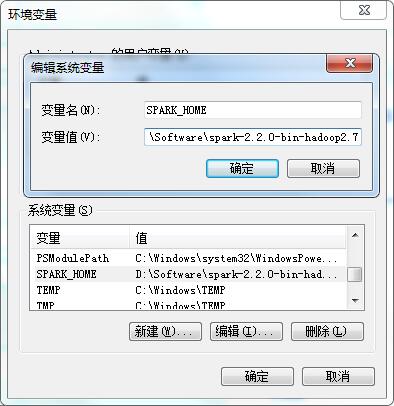


注意: 编辑系统变量PATH的值,将java,hadoop的相关bin路径添加进去,spark添加到它的主目录就够了,注意是添加,不要删除原有的其他应用的路径值!!!每个路径之间用英文半角的引号(;)分开
四.【将pyspark文件放到python文件夹下、使用winutils.exe修改权限】
1,将spark所在目录下(比如我的是D:\Software\spark-2.2.0-bin-hadoop2.7\python)的pyspark文件夹拷贝到python文件夹下(我的是D:\Program Files\python3.5.3\Lib\site-packages)
具体目录要看大家自己安装的时候是放在哪的!
2,安装py4j库
一般的在cmd命令行下 pip install py4j 就可以。若是没有将pip路径添加到path中,就将路径切换到python的Scripts中,然后再 pip install py4j 来安装库。
3,修改权限
将winutils.exe文件放到Hadoop的bin目录下(我的是D:\Software\hadoop-2.7.3\bin),然后以管理员的身份打开cmd,然后通过cd命令进入到Hadoop的bin目录下,然后执行以下命令:
winutils.exe chmod 777 c:\tmp\Hive

注意:1,cmd一定要在管理员模式下!cmd一定要在管理员模式下!cmd一定要在管理员模式下!
2,‘C:\tmp\hive’,一般按照上面步骤进行了之后会自动创建的,一般是在Hadoop的安装目录下出现。但是若没有也不用担心,自己在c盘下创建一个也行。
关闭命令行窗口,重新打开命令行窗口,输入命令:pyspark

出现上面的窗口且不报错,那么恭喜你安装成功了!


















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











