







1.前言
1.当特征太多时,无论线性回归还是逻辑回归计算的负荷都会非常大。
2.使用非线性的多项式往往能够帮我们建立更好的分类模型。然而特征组合数量却非常惊人,例如:2500个特征,仅两两组合就有2500^2/2(近300万个)。普通逻辑回归不能有效处理这么多特征。
这时候我们需要神经网络。
2.神经网络简介(可直接参考:https://blog.csdn.net/illikang/article/details/82019945)
神经网络是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术。在大脑中,神经网络是大量神经元相互连接并通过电脉冲来交流的一个网络。下面是一组神经元的示意图:

神经网络模型也建立在很多神经元之上,这些神经元也叫做激活单元。
输入——树突(Dendrite)
处理单元——神经核(Nucleus)
输出——轴突(Axon)
下图为一个三层神经网络:

Layer1:输入层——输入单元
Layer2:隐含层/中间层——隐含单元 /中间单元
Layer3:输出层——输出单元:代表第j层的第i个激活单元。
:代表从第j层映射到第j+1层时的权重的矩阵,行数为第j+1层的单元数量,列数为第j层单元数加一。
上图所示模型中,激活单元和输出分别表示为:
 (1)
(1)
这里只是计算一个样本/一个训练实例的情况。而我们需要用所有样本来进行神经网络模型的训练。
像(1)式,每一层的a都是由上一层的所有x和x对应的权值决定的。每一层的输出变量都是下一层的输入变量。我们把这种从左到右的算法称为前向传播算法。我们可以把 看成更为高级的特征看成更为高级的特征值,也就是 𝑥0,𝑥1,𝑥2,𝑥3的进化体,的进化体,并且它们是由 𝑥与决定的,因为是梯度下降所以 𝑎是变化的,并且得越来厉害,所以这些更高级的特征值远比仅将 𝑥次方厉害,也能更好的预测新数据。 这就是神经网络相比于逻辑回归和线性的优势。
3.多类分类
当我们要训练一个神经网络来识别路人、汽车、摩托车和卡车,在输出层我们应该有四个值。例如第一个值为1或0用于预测是否是行人,第二个值用于判断是否是汽车...下面是该神经网络的可能结构示例:

神经网络算法的输出结果为下面四种可能情形之一:

4.代价函数
神经网络的分类分为二分类和多分类两种情况。

L:神经网络总层数:第
层的单元数
逻辑回归中我们的代价函数为:
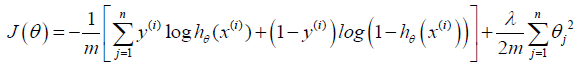 (2)
(2)
神经网络中,我们的是一个维度为K的向量,代价函数为:
 (3)
(3)
对于每一个样本,我们会给出K个预测结果,然后在K个预测中选择可能性最高的一个,将其与y中实际数据进行比较。
5.求最优解
和逻辑回归一样,还是使用梯度下降方法来求解代价函数最优解。用梯度下降方法主要就是求代价函数的偏导数。
先不考虑正则项,且只有一个样本,一个隐含层时:
(4)
对求偏导得:
(5)
但神经网络往往都有多个隐含层,如何对多个隐含层求偏导呢?
- 前向传播算法
前面我们计算神经网路的预测结果时采用了前向传播方法,我们从第一层开始正向一层一层进行计算,直到最后一层。假设我们只有一个训练实例,我们的神经网络是一个四层神经网络。其中
(类别数),
(最后一层单元数),
:


即:
(6)
带入代价函数:
(7)
- 后向传播算法
仔细看看其实这些式子是有关系的:
令, 则:
令
则:
令
我们把看成
层的误差,然后由后一层误差算出前一层的误差,第一层是输入变量不存在误差,偏导数也是由后往前计算。这种方法我们称其为后向传播算法。
- 如果直接用前向算法计算偏导数,则会存在很多重复的计算。
先算再算
再算
,可以看到很多都重复计算了。
- 总结神经网络求最优解步骤
step1:随机初始化参数;
step2:通过前向算法计算出每一层的激活单元;
step3:计算最后一层的误差,利用该误差运用反向传播法计算直至第二层的所有误差
step4:计算偏导数;
step5:计算梯度(注意:计算时偏置项参数不参与正则化);
step6:更新参数;
step7:不断迭代step2-6更新参数直至达到收敛条件。
6.随机初始化参数
逻辑回归中,参数都初始化为0,但这种方法对于神经网络行不通。如果我们令所有的初始参数都为0,这意味着我们的第二层的多有激活单元都会有一样的值,同理,全部初始化为同一个不为0的数结果也一样。我们通常初始化参数为正负之间的随机值。其中
的取值通常为:
、
分别表示该对应的上下层的单元数。
7.梯度检验
当我们对一个复杂的模型使用梯度下降时,可能会存在一些不容易察觉的错误,意味着,虽然代价看上去在不断减小,但最终的结果并不是最优解,为解决这样的问题,我们可以采取一种叫梯度的数值检验的方法。在一个特定的,我们计算出
、
,
是个很小的值,通常取0.001

在处的偏导数近似为:
依次计算出所有的偏导数,然后和通过反向算法计算出的偏导数比较,正常情况两者差异甚小。
8.代码实现(python)















 6812
6812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









