







二值可微分搜索(BATS)
本文为三星发表在 ECCV 2020 的基于二值网络搜索的 NAS 工作(BATS),论文题目:BATS: Binary ArchitecTure Search。通过结合神经网络架构搜索,大大缩小了二值模型与实值之间的精度差距,并在CIFAR 和 ImageNet 数据集上的实验和分析证明了所提出的方法的有效性。
- 论文链接:BATS: Binary ArchitecTure Search
- 源码链接(即将开源):https://github.com/1adrianb/binary-nas
摘要
本文提出了二进制架构搜索(BATS),这是一个通过神经架构搜索(NAS)大幅缩小二进制神经网络与其实值对应的精度差距的框架。实验表明,直接将NAS 应用于二进制领域的结果非常糟糕。为了缓解这种情况,本文描述了将 NAS 成功应用于二进制领域的 3 个关键要素:
- (1) 引入并设计了一个新的面向二进制的搜索空间。
- (2) 提出了一个新的控制和稳定搜索拓扑结构的机制。
- (3) 提出并验证了一系列新的二进制网络搜索策略,以实现更快的收敛和更低的搜索时间。
实验重新结果证明了所提出的方法的有效性和直接在二进制空间中搜索的必要性。并且,在CIFAR10、CIFAR100 和 ImageNet 数据集上设计了 SOTA 的二元神经网络架构。
方法
搜索空间重定义
标准 DARTS 搜索空间的问题
标准 DARTS 搜索空间下搜索得到的网络结构二值化训练是无法收敛的,原因如下:
- 深度可分离卷积(SepConv)二值化难。首先,实数深度可分离卷积本身就是普通标准卷积的“压缩”版本,其次,经过二值化后进一步对深度可分离卷积进行了近似操作。因此,深度可分离卷积二值化存在“双重近似问题”。
- 1x1卷积 & bottlneck 块 二值化难。因为关键的FeatureMap信息,由于1x1卷积权重值少和bottlneck所处的重要位置被二值化后无法有效传递下去。
- DilConv & SepConv 二值化难。标准的 DARTS 搜索空间定义的
DilConv和SepConv操作包含的卷积序列个数不同。DilConv包含两个卷积序列,SepConv包含四个卷积序列。导致训练过程中两者的收敛速度不同,并且会因此放大二值化过程中的梯度衰减现象(论文是这样描述的,不过具体原因不清楚)
二值神经网络搜索空间
二值神经网络搜索空间与标准 DARTS 搜索空间对比如下图所示:
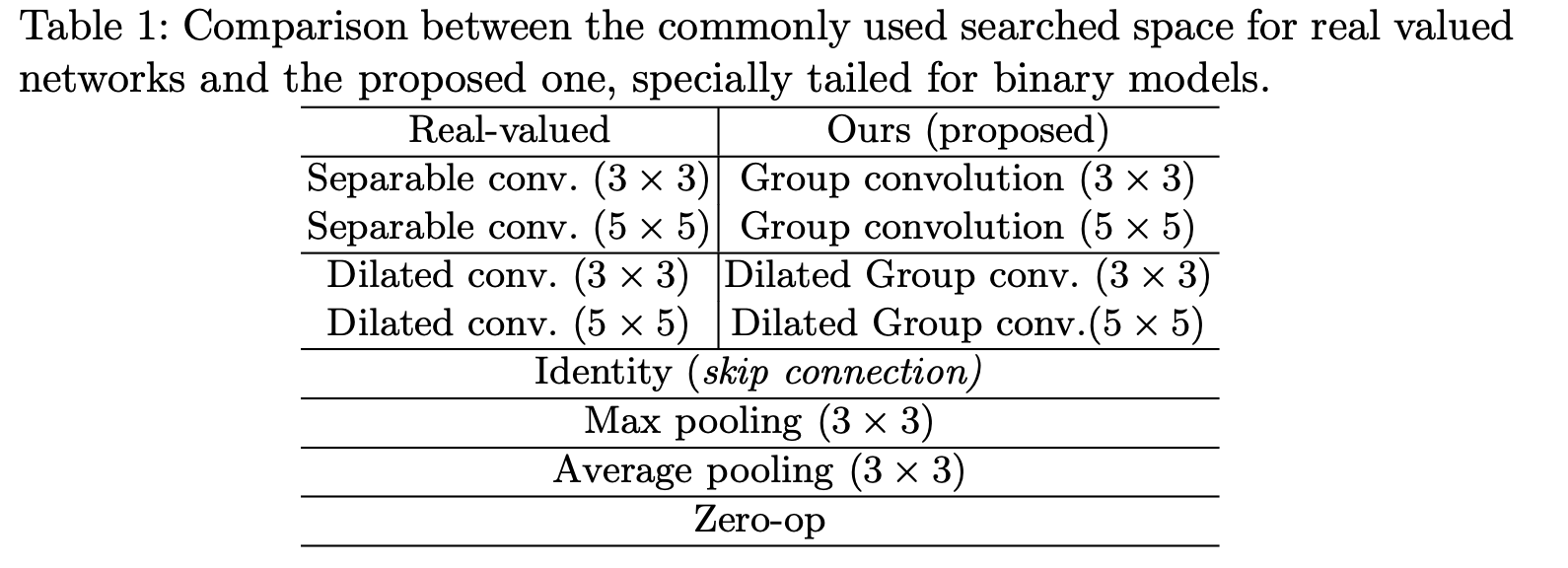
主要存在以下几方面的修改:
- 删除了 1x1 卷积。
- 重新分配了深度可分离卷积中 Group Size 与 Channel 的关系。标准的深度可分离卷积中
#groups = #in_channel。本文中,CIFAR数据集上预定义Group卷积为12 Groups x 3 Channels = 36 Channels;ImageNet 数据集上预定义Group卷积为16 Groups x 5 Channels = 80 Channels。 - 每个opetation只包含一个卷积序列,便于学习和实现低延时。
- 每个卷积操作都加上
Skip-Connect操作,有利于保持FeatureMap信息的传递和保留。
搜索的正则化和稳定性
DARTS 搜索的不稳定分析
尽管 DARTS 取得了成功,但根据随机种子的不同,DARTS 的精度在运行之间可能会有很大的差异。事实上,在有些情况下,随机搜索获得的架构甚至比搜索得到的架构通过表现的更好。此外,特别是当训练时间较长或在较大的数据集上进行搜索时,DARTS可能会出现 Skip-Connect 富集的问题。常用的解决方法包括:
- 在架构搜索过程中对跳连应用dropout
- 通过保留每个单元最多2个跳连作为后处理步骤,简单地促成概率第二高的操作
但是,这种机制仍然会导致大量的随机性,而且并不总是有效的:例如,它可能会用池化层(没有学习能力)取代跳过连接,或者搜索的架构跳连包含的太少。当搜索是在二进制域中直截了当地进行时,这样的问题就更加明显了。鉴于在搜索过程中,节点 j 的输入是通过对所有输入边的加权和来获得的,为了最大限度地提高信息流,架构参数 α 倾向于收敛到相同的值,使得最终架构的选择存在问题,并且容易受到噪声的影响,导致拓扑结构的性能可能比随机选择更差。此外,搜索高度偏向于实值操作(池化和跳连),使得搜索在早期阶段可以提供更大的收益。
温度正则(temperature regularization)
为了缓解上述问题,并使得搜索程序更具辨别力,迫使其做出 “harder” 的决策,本文借鉴知识蒸馏的思路,建议使用温度因子 T<1 的正则策略,定义从节点i到j的流程如下公式所示:
f i , j ( x i ) = ∑ o ∈ O exp ( α i , j o / T ) ∑ o ′ ∈ O exp ( α i , j o ′ / T ) ⋅ o ( x i ) f_{i, j}\left(\mathbf{x}_{i}\right)=\sum_{o \in O} \frac{\exp \left(\alpha_{i, j}^{o} / T\right)}{\sum_{o^{\prime} \in O} \exp \left(\alpha_{i, j}^{o^{\prime}} / T\right)} \cdot o\left(\mathbf{x}_{i}\right) fi,j(xi)=o∈O∑∑o′∈Oexp(αi,jo′/T)exp(αi,jo/T)⋅o(xi)
采用温度正则方法可以使架构参数的分布不那么均匀,更加尖锐(即更有辨别力)。在搜索过程中,由于信息流是使用加权进行聚合的,所以网络不能从所有信息流中提取信息,来平等地(或接近平等地)依赖所有可能的操作。相反,为了确保收敛到一个满意的解决方案,它必须将最高的概率分配给一个非0操作的路径,由一个次元温度(T <1)强制执行。这种行为也更接近评估过程,从而减少搜索(网络从所有路径中提取信息)和评估之间的性能差异。
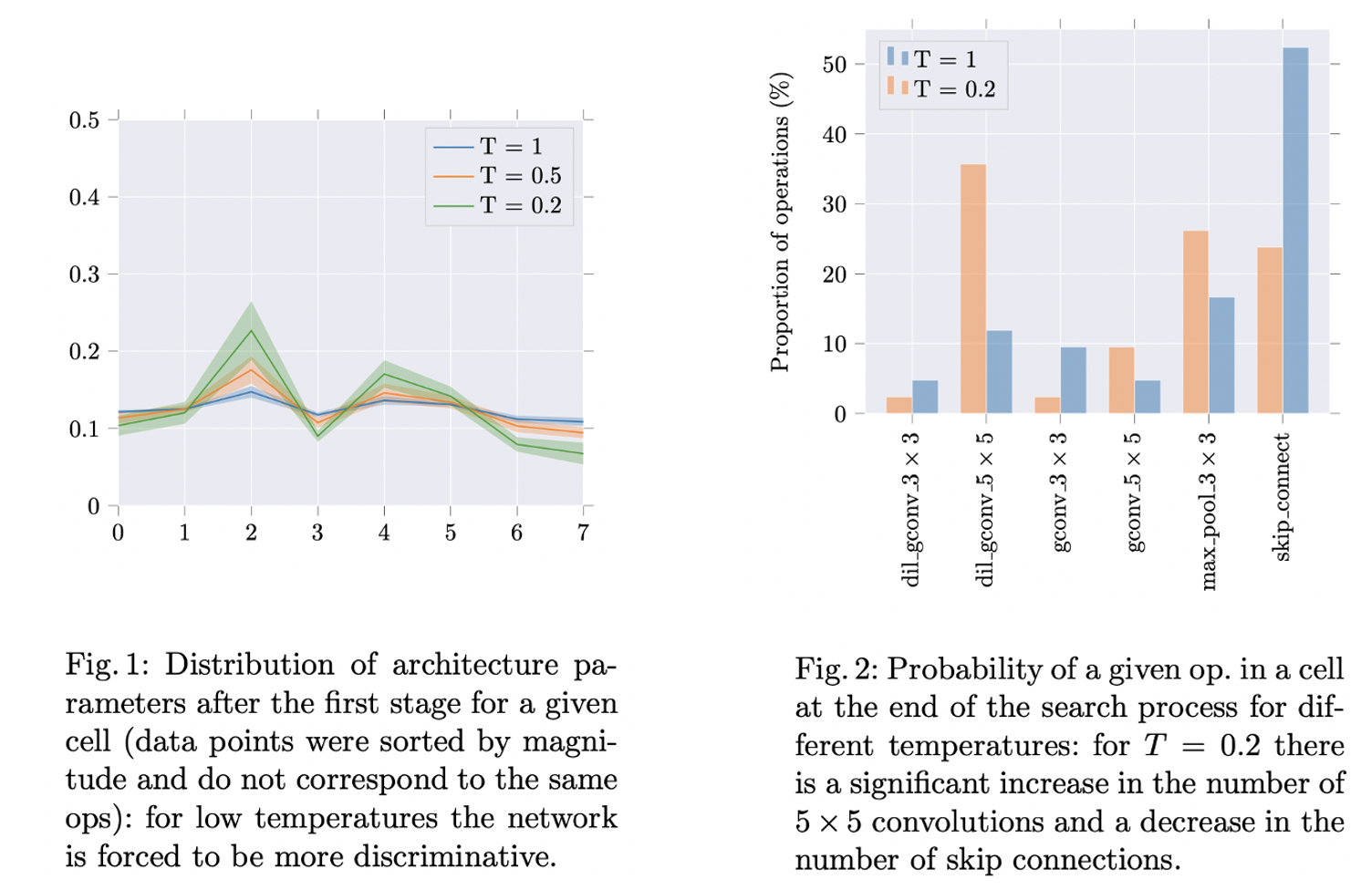
上图中,图1描述了给定单元在不同温度下的架构参数分布。对于低温(T=0.2),网络被迫做出更多的判别性决策,这反过来又使它减少了对 Skip-Connect 的依赖。图2 进一步证实了这一点,它描述了在不同温度下搜索过程结束时,在 Normal Cell 中各操作被选择的概率。
二值搜索策略
尽管二值网络具有加速和节省空间的特点,但与实值网络相比,二值网络的训练仍然比较困难,其方法通常需要一个预训练阶段或仔细调整超参数和优化器。对于搜索二值网络的情况,直接实现二值权重和激活的架构搜索,在大多数尝试中,要么导致退化的拓扑结构,要么训练简单地收敛到极低的精度值。此外,直接在实域中执行搜索,然后对网络进行二值化是次优的。
为了缓解这个问题,本文提出了一个两阶段的优化过程,在搜索过程中,激活是二值化的,而权重是实值化的,一旦发现了最佳架构,我们在评估阶段也要对权重进行二值化。【更具体地说,在评估过程中,首先从头开始训练一个具有二值激活和实值权重的新网络,然后对权重进行二值化。最后,在测试集上对完全二值化的网络进行评估。】这是因为实值网络的权重通常可以被二值化,而不会显著降低精度,但激活的二值化就不一样了,由于可能的状态数量有限,网络内部的信息流急剧下降。因此,本文提出将问题有效地分成两个子问题:权重和特征二值化,在搜索过程中,尝试解决最难的一个问题,即激活的二值化。一旦完成了这一点,权重的二值化以下总是会导致精度的小幅下降(~1%)。
实验
消融实验
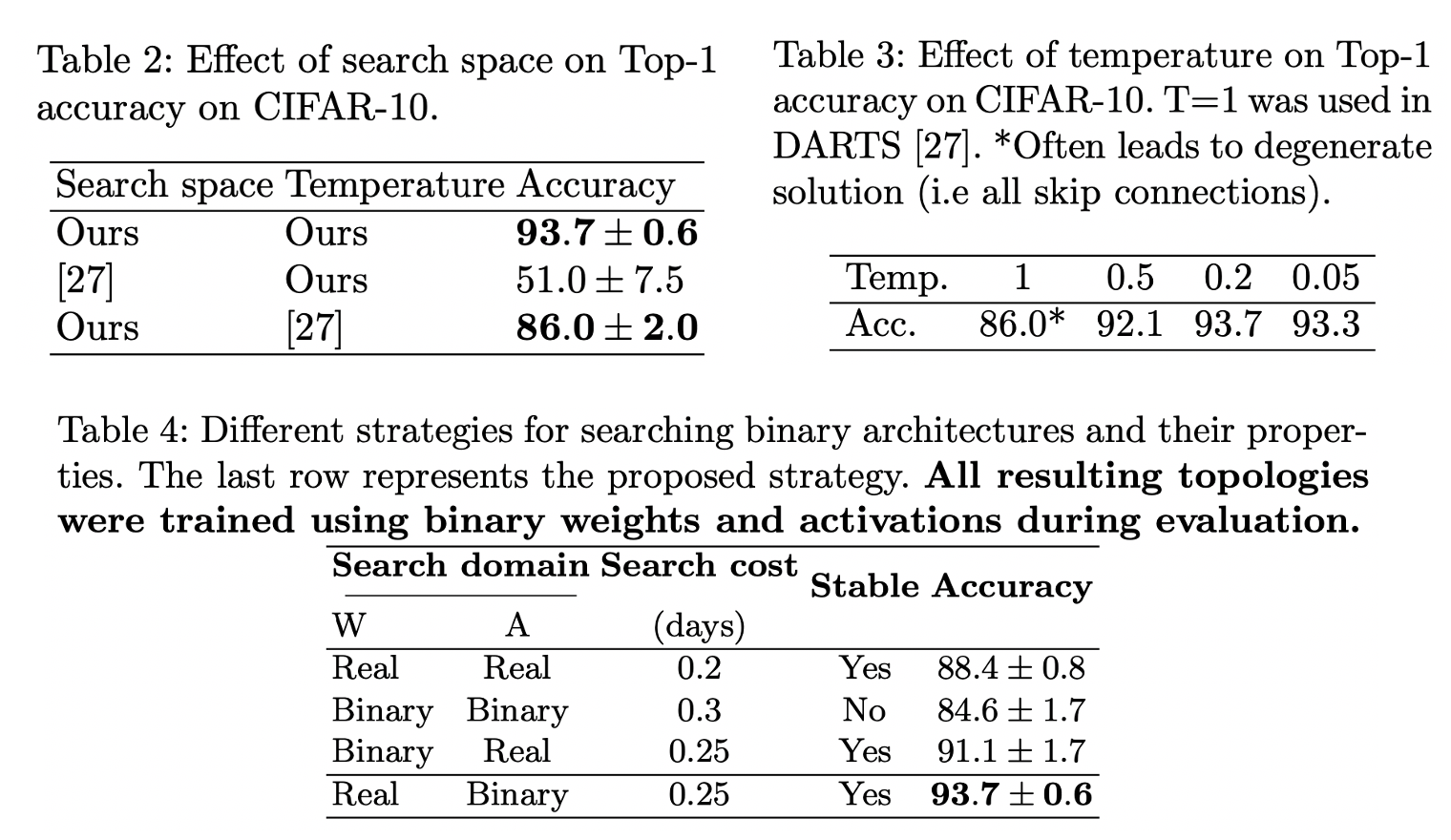
二值网络架构
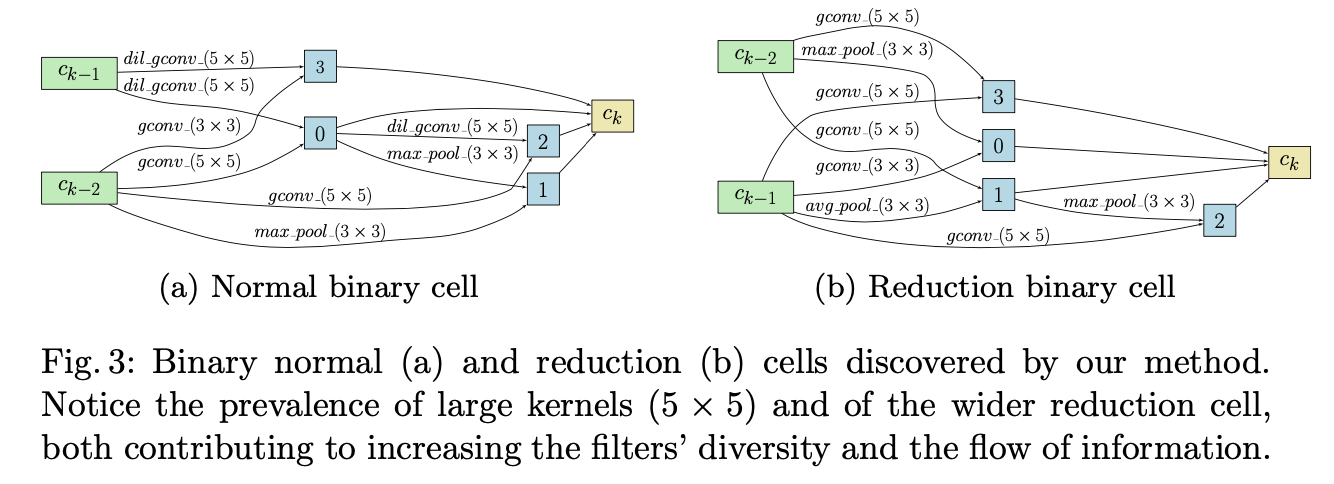
CIFAR
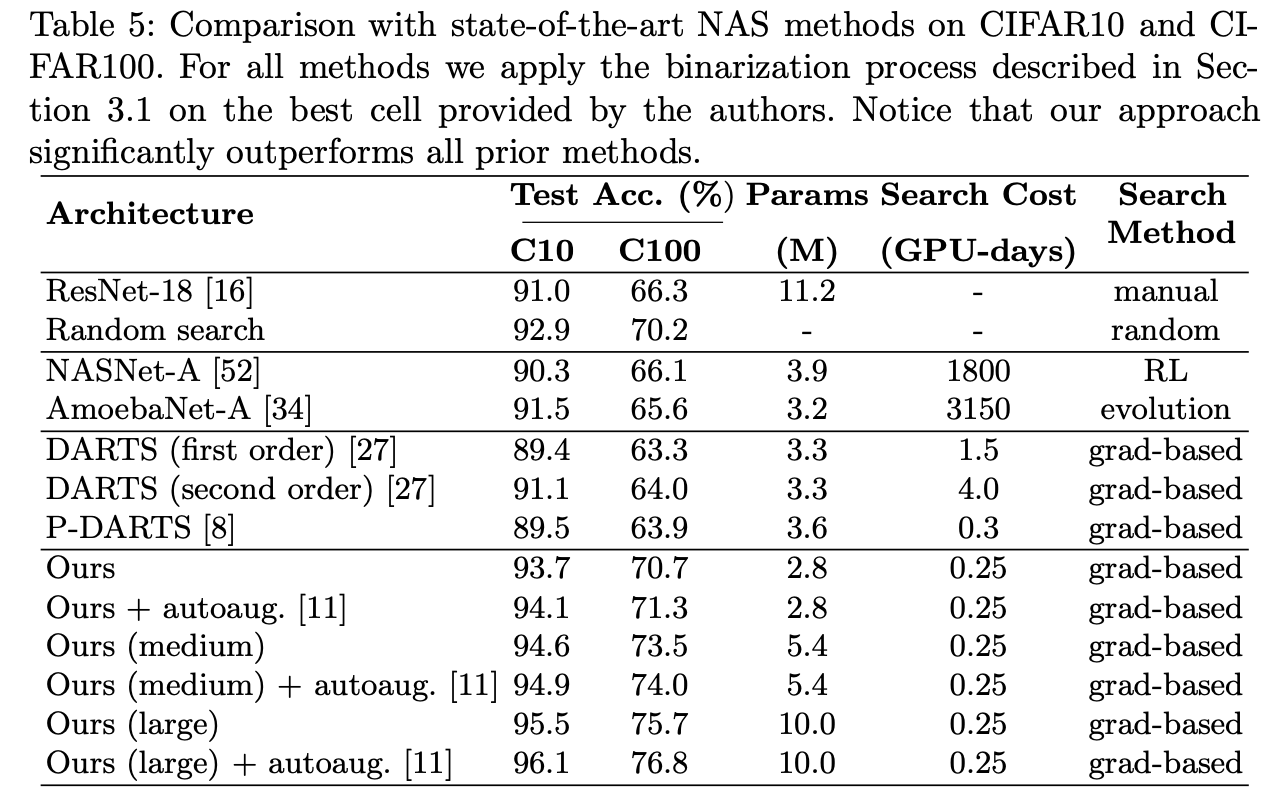
ImageNet
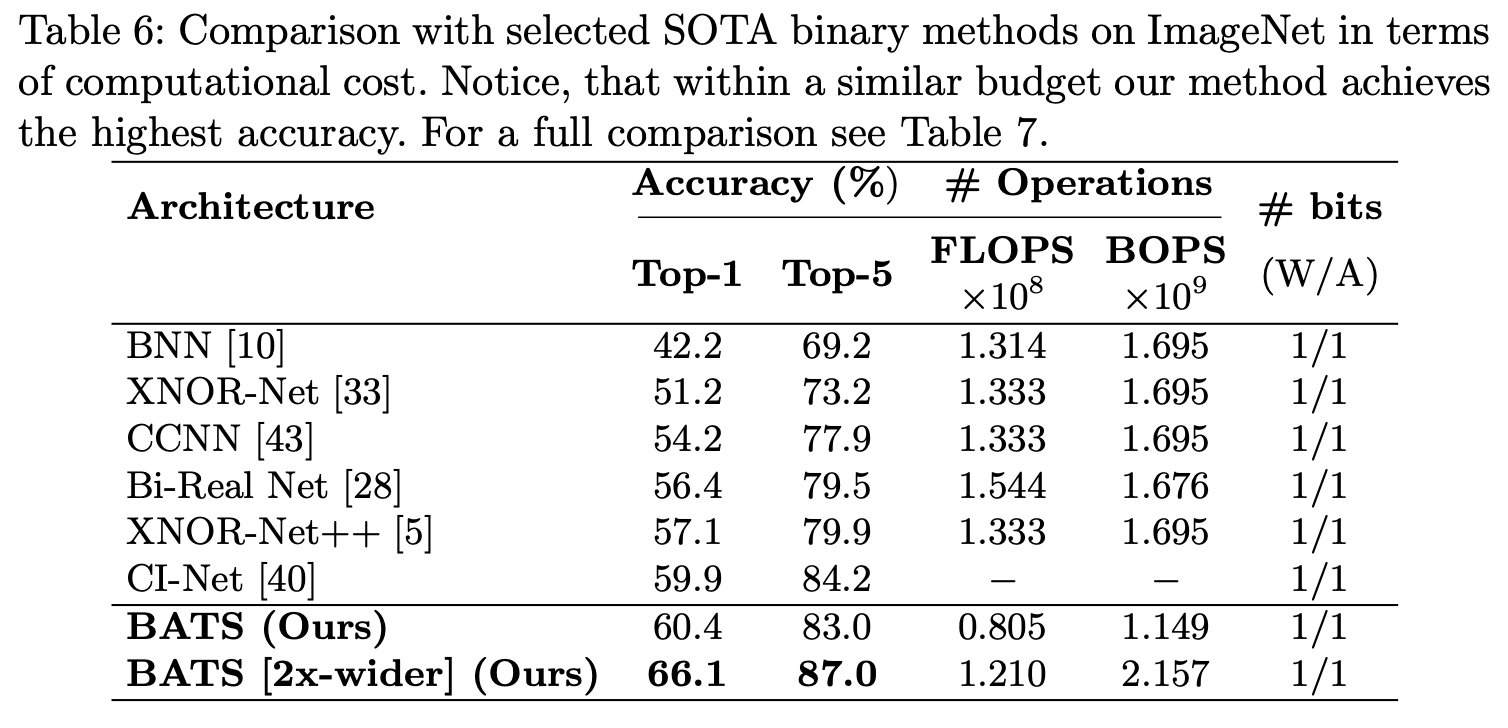
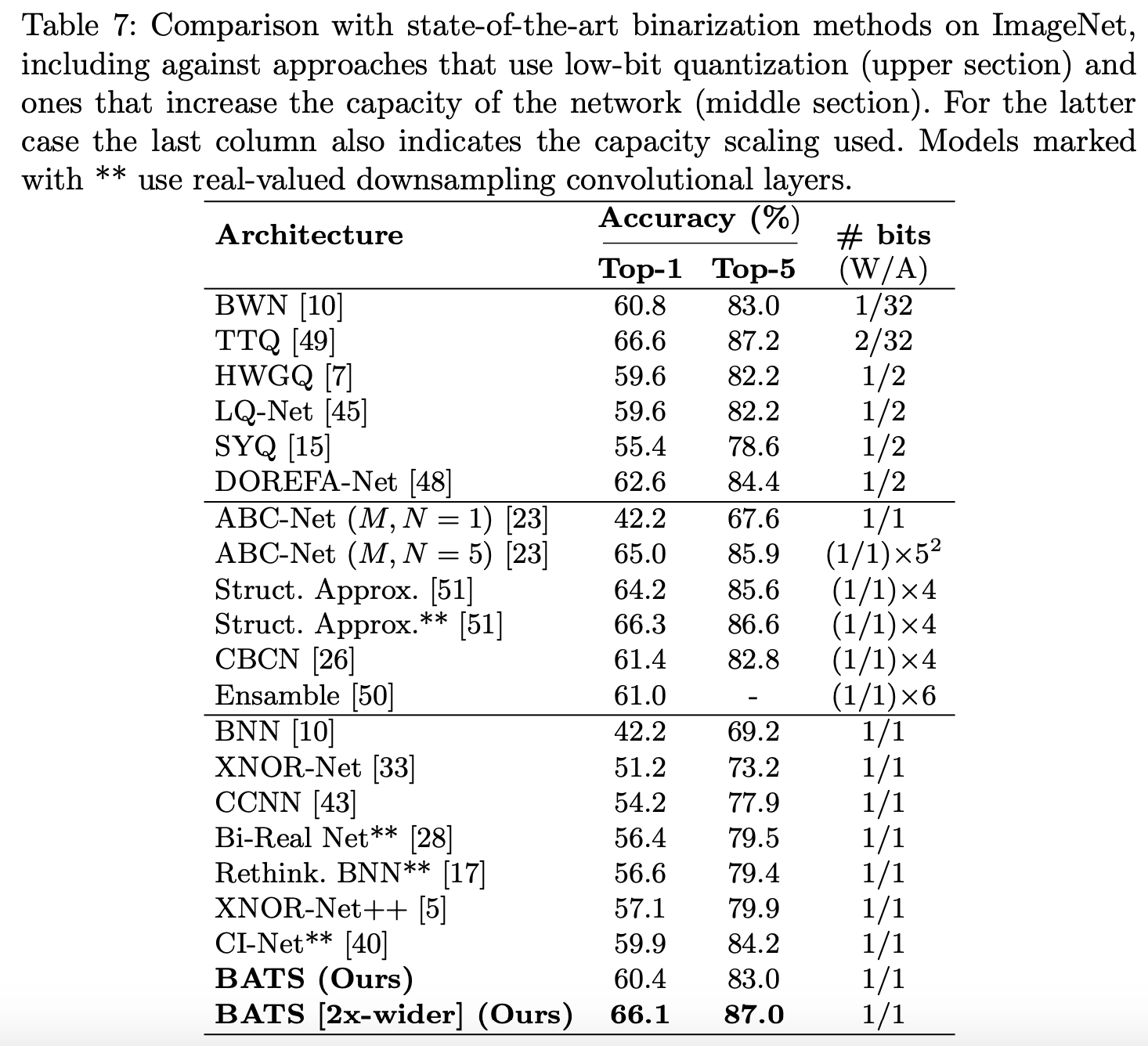



















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









