







01
前言
作为核心基础软件之一,数据库是其中至关重要的一环。许多企业目前使用的还是传统的商业型数据库,但是高昂的许可证费用,繁琐的许可条款,使众多企业将目光投向了更具成本效益、更加灵活的云端开源数据库。除此之外,云上数据库还具有安全稳定,弹性伸缩,便捷运维等优势。一般来说,从商业数据库往开源数据库迁移,会涉及到复杂的对象转换和数据迁移过程,并伴随着应用代码的适配重写,企业客户希望有一种更加平滑的方式,让整体迁移能够更快、风险更低。
Babelfish for Aurora PostgreSQL (以下简称 Babelfish)是亚马逊云科技在 2021 年推出的一项新功能,它能让 Aurora PostgreSQL 理解来自为 Microsoft SQL Server 编写的应用程序的查询,并支持相同的通信协议。因此,为数据库迁移而需要改动的代码量将会大大减少,从而可实现更快、风险更低且更具成本效益的迁移。Babelfish 功能在亚马逊云科技中国区的北京区域、宁夏区域均已上线,并在开利消防、Early Data 等多个案例中帮助客户成功地完成了从 SQL Server 向 Aurora PostgreSQL 的快速迁移。
在数据库迁移以及应用功能扩展阶段,基于 Babelfish 的 T-SQL 代码开发除了要注意与 SQL Server 的差异性之外,还要考虑包括对象属性、互操作性以及代码调试与优化等问题。本文将从实际案例出发,总结相关经验并整理成册,提供给您一份基于 Babelfish 的 T-SQL 代码开发最佳实践。
02
开发要点场景概述
要理解基于 Babelfish 上开发 T-SQL 和原有模式的差异和注意点,首先您要了解 Babelfish 的软件架构和基于 Babelfish 的开发模式选择。
软件架构
Aurora PostgreSQL 在开启了 Babelfish 功能后,数据库将开放两个不同的 TCP 端口接受连接。通过连接不同的端口,客户端可以通过 TDS 协议使用 T-SQL 对其进行访问,同时也可以通过 PostgreSQL 的连接方式进行访问。那么,Babelfish 是如何在 PostgreSQL 上接受 TDS 协议并处理 T-SQL 的解析与执行?从下图中的 Babelfish 软件架构和执行流程图中您可以找到答案。
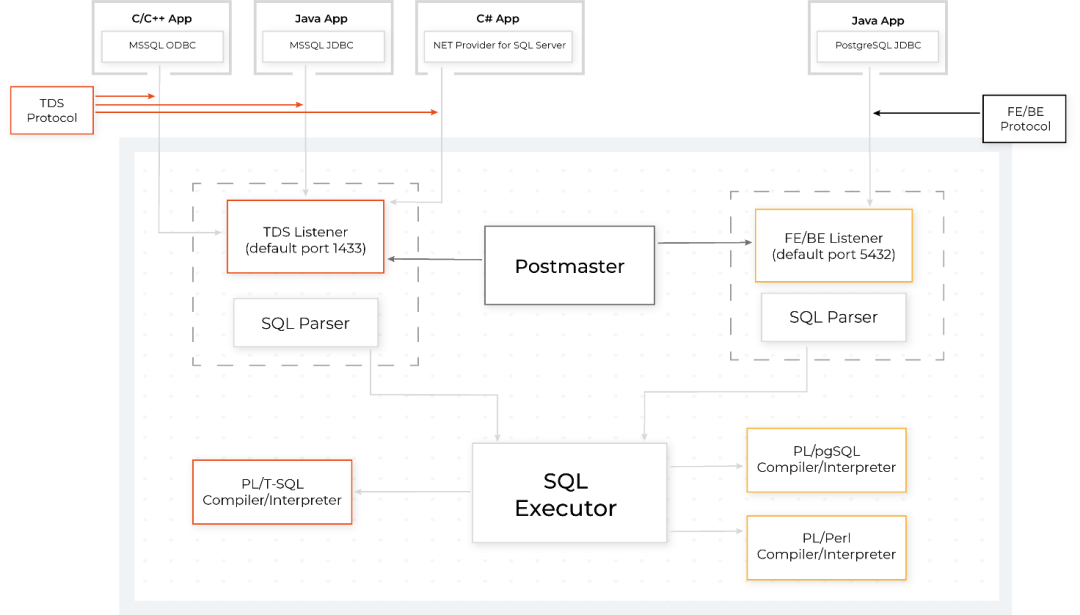
Babelfish 使用了协议 hooks 来实现 PostgreSQL 对 TDS 协议的访问支持,具体而言,当客户端通过 Babelfish 端口访问 Aurora PostgreSQL 时,hooks 将 T-SQL 的语句翻译成 PostgreSQL 能够理解与处理的操作,并在 PostgreSQL 中执行。而当客户端通过 PostgreSQL 端口进行访问时,hook 为 Null,此时和正常访问 PostgreSQL 的方式无异。更多详细信息,您可以参考 Babelfish 手册来了解 hooks 的运行机制。
无论是通过 Babelfish 连接,还是通过 PostgreSQL 对数据库进行操作,数据都将被写入底层的 PostgreSQL 数据库中,而读取也是从同一个 PostgreSQL 数据库中进行读取。这也就意味着,通过 Babelfish 端口用 T-SQL 语句写入的数据可以通过 PostgreSQL 进行读取,反之亦然。
开发模式
随着企业业务的发展及应用现代化的需求,当后端数据库从 SQL Server 迁移到 Babelfish 之后,您可以选择在 Babelfish 上的开发模式。通常来说,有以下几种开发模式:
使用 SQL Server 驱动开发 T-SQL 代码:典型场景为基于原有的技术开发栈,对原有业务系统进行维护、功能扩展等。
使用开源驱动开发 PL/pgSQL 代码:典型场景为技术平台升级,使用开源数据库作为底座开发新业务系统。
使用 SQL Server 驱动调用在 PostgreSQL 开发的代码,这是为解决 Babelfish 兼容性问题的典型开发场景,如利用 PostgreSQL 的分区、地理数据支持等功能实现 Babelfish 的兼容。

T-SQL 开发注意要点
当您使用 T-SQL 访问 Babelfish 时,无论是与使用 PostgreSQL 来对比,还是与使用 T-SQL 访问 SQL Server 对比,在语法、对象特性、事物语义等方面会有一点区别,请您在使用上要留意其中的区别,并了解如何规避和解决这些不同点,才能更好的进行开发。本文对于基于 Babelfish 的 T-SQL 开发的最佳实践介绍,主要包括以下几方面:
对象属性:当从 SQL Server 迁移到 Babelfish 之后,查询结果的字段大小写在特定场景下会有所不同,系统视图中的数据大小写也是不同的,需要规避这种差异对应用的影响;此外,PostgreSQL 与 SQL Server 自增字段的实现方式不同,因此,在迁移后也要对此类自增字段做相应设置,以避免可能造成的数据插入违反唯一约束的错误。
互操作性:除了 Babelfish 和 SQL Server 支持的 T-SQL 特性之间的区别之外,您可能还需要在 Aurora PostgreSQL 数据库集群的背景下考虑 Babelfish 和 PostgreSQL 之间的互操作性问题。如前所述,Babelfish 可以通过不同端口互相访问同一份数据。如果您正在考虑在生产部署中同时使用 PostgreSQL 和 Babelfish 功能,则需要意识到架构名称、标识符、权限、事务语义、多个结果集、原定设置排序规则等之间潜在的互操作性问题。
语法兼容和调试:Babelfish 对于语法、字段类型匹配要求相较于 SQL Server 都更加严格,比如在运算符中间存在空格时,以及数据转换的处理上有所不同,在迁移时的代码需要进行相应的改写。而当遇到逻辑复杂的代码或代码运行错误时,使用合适的调试方式可以提高调试效率。
SQL 优化:在 Babelfish 中开发的 T-SQL 代码同样可能需要进行优化,您可以通过查看执行计划,确认查询耗时较高的部分,对 SQL 进行改进。查询提示也是一种优化方式,它可以改变原有的查询计划,但要注意随着数据的变化,查询提示也应做相应的更新。
03
开发最佳实践
上文介绍了 Babelfish 的软件架构、开发模式选择以及开发中需要注意的一些事项。现在让我们来看真实世界的一些具体案例,了解基于 Babelfish 开发 T-SQL 的最佳实践。本文展示的所有案例,是运行在 Aurora PostgreSQL 14.7 (Babelfish 2.4) 的数据库版本上,它发布于2023年4月,与之进行场景对比的是 Amazon RDS SQL Server 2019。另外,下文中所描述的不同的连接方式分别指的是:
Babelfish 连接:使用 SQL Server 的驱动及工具等,通过 TDS 监听端口(默认 1433)连接到 Aurora PostgreSQL 并执行 T-SQL 语句
PostgreSQL 连接:使用 PostgreSQL 驱动及工具等,通过 PostgreSQL 监听端口(默认 5432)连接到 Aurora PostgreSQL 并执行 SQL 语句
SQL Server 连接:使用 SQL Server 的驱动及工具等,通过 TDS 监听端口(默认 1433)连接 RDS SQL Server 并执行 T-SQL 语句
3.1 对象属性
首先,我们来探讨一下常常容易忽略但可能造成应用错误的一类差异性问题,那就是 Babelfish 和 SQL Server 中一些对象显示和属性的不同。
1)表字段名大小写显示
Babelfish 中建表语句可指定字段名大小写及驼峰格式,同时在查询 SQL 语句中,也可以指定字段名称大小写,这些字段显示的结果和 SQL Server 是一致的。不同之处在于当查询包含表别名加具体字段时,Babelfish 中会将指定的具体字段名全部显示为小写,而 SQL Server 则显示为 SQL 语句中已定义的字段值大小写。以下的案例显示了这两者的具体差异点。
先使用下面的语句通过 Babelfish 连接和 SQL Server 连接分别创建相关的测试表:
create table Dept(
Deptno int NOT NULL PRIMARY KEY,
Dname varchar(14),
Loc varchar(13)
)
create table Employees (
Empno int NOT NULL PRIMARY KEY,
Ename varchar(10),
Job varchar(9),
MGR int,
Hiredate datetime,
Sal money,
Comm money,
Deptno int
)
alter table Employees add foreign key([Deptno]) references dept ([Deptno])
insert into Dept values (10,'ACCOUNTING ','New York')
insert into Employees values (1001,'Colin','Manager','8001',NOW(),5000,NULL,10)左滑查看更多
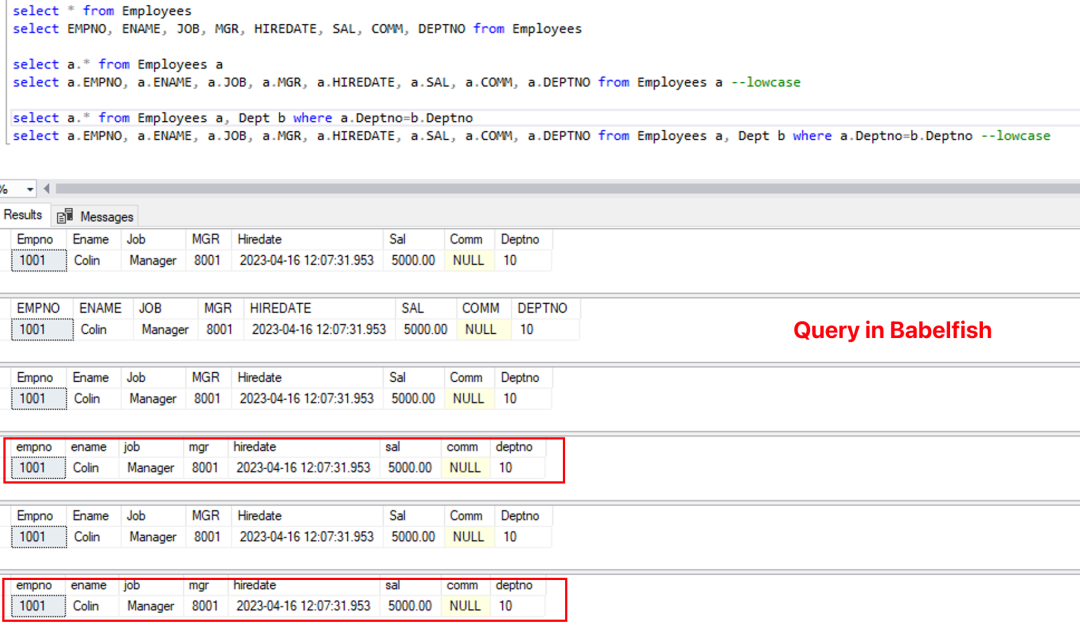
执行以下查询语句来展示不同场景下两者显示的字段大小写区别,在 Babelfish 中显示的结果如下:
使用“*”查询表的所有字段 – 返回建表语句中定义的字段大小写
使用“字段名”查询表的字段 – 返回 SQL 语句中定义的字段大小写
使用“别名+*”查询表的所有字段 – 返回建表语句中定义的字段大小写
使用“别名+字段名”查询表的字段 – 返回小写的字段名
使用“别名+*”查询表关联下的所有字段 – 返回建表语句中定义的字段大小写
使用“别名+字段名”查询表关联下的字段 – 返回小写的字段名
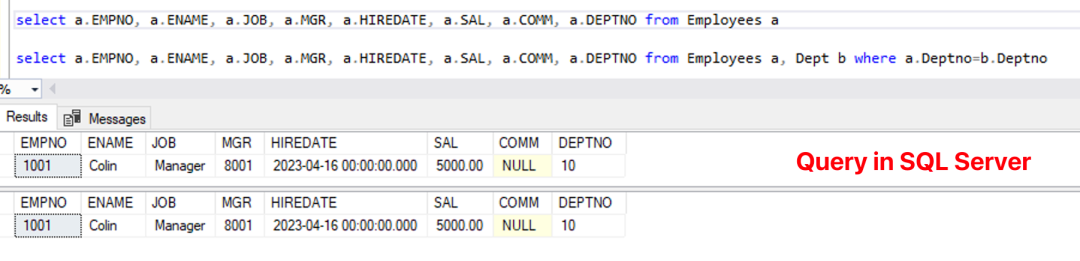
而在 SQL Server 的查询中,明显不同的就是使用了“别名+字段”时仍保持显示字段在 SQL 语句中的大小写设定。
我们知道,应用开发中常见的 ORM 框架如 Node.js 的 TypeOrm、Sequlize,Java 的 Hibernate,Mybatis 和 Go 的 Gorm、GoRose 等,实现了面向对象编程语言中的内存对象与关系型数据库中的业务实体之间的关系映射。这样在操作数据库的时候,不再需要和复杂的 SQL 语句打交道,只需要简单地操作对象的属性和方法就可以直接实现对数据库中对应实体表的 CRUD(增删改查)的操作。如果属性和 SQL 查询中显示的字段名大小写不匹配,则会导致应用在运行时报错。
我们建议在遇到此类场景时,需要仔细评估应用和 T-SQL 的开发代码,如果的确需要进行代码更改的,可以从复杂度、性能、时间成本上考虑,调整应用或者 T-SQL 上的代码(比如设置字段别名)。
2)系统视图对象名大小写
类似于 SQL Server 中使用的系统视图,Babelfish 中也提供了部分同名和相同结构的系统视图,可以获取存储在 Babelfish 中的数据库对象的信息。Babelfish 的每个新版本都增加了对更多系统视图的支持,您可以从 Babelfish 的使用手册中找到这些视图的信息来参考。但和 SQL Server 不同,Babelfish 中系统视图存储的对象名都是小写的,我们可以通过以下的 SQL 语句,从常用的几个视图中查询上文所建的对象来验证这一点。
select 'sys.tables' as "View", Name from sys.tables where name='Employees'
union all
select 'sys.columns' as "View", Name from sys.columns where object_id = (select object_id from sys.objects where name='Employees')
union all
select 'sys.indexes' as "View", Name from sys.indexes where object_id = (select object_id from sys.objects where name='Employees')左滑查看更多
查询结果对比显示 SQL Server 在系统视图中保存 DDL 语句中的对象大小写,而 Babelfish 则在系统视图中将数据统一存放为小写。
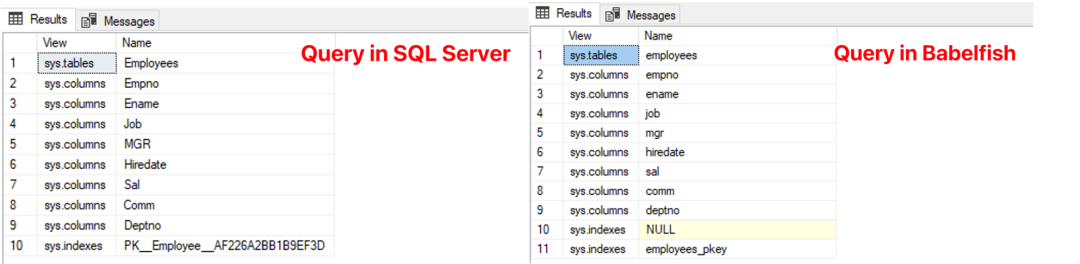
当您的应用程序和 T-SQL 代码涉及到在这些系统视图中查询数据并比对时,以上差异可能会导致数据获取失败,比如在设置为使用大小写敏感的排序集的数据库上执行此类查询语句。我们建议重新审阅和评估这些语句并进行适当调整,例如在查询中使用统一的 upper 或 lower 函数进行转换以确保能获取到数据。
3)IDENTITY 自增列
SQL Server 中表的字段如果设置为 Identity 属性标识,那么该列是 ID 列。ID 列是由系统自动赋值的,在赋值时,系统根据该表的 ID 值,自动插入递增的,唯一的数值,同时 ID 值根据 Increment 自动递增。
Babelfish 兼容 SQL Server 的 Identity 属性,它是使用 PostgreSQL 的 Identity 字段类型来支持。通常而言,PostgreSQL 中可以通过字段与 Sequence 绑定,Serial 类型和 Identity 类型来分别实现自增列功能,而 Identity 是 Serial 的“增强版”,更适合作为“自增列”使用。
通过比较使用 Babelfish 连接建表的语句和在 PostgreSQL 所看到的 DDL 语句,可以更加清晰地理解 Babelfish 中的 Identity 属性是如何在 PostgreSQL 中实现的:
Babelfish 连接所见 DDL 语句:列名 数据类型 IDENTITY NOT NULL
PostgreSQL 连接所见 DDL 语句:列名 数据类型 NOT NULL GENERATED ALWAYS AS IDENTITY
在实际使用中,对于 ID 列的操作 Babelfish 和 SQL Server 两者间存在相同和不同之处。
相同点:
都能实现 ID 列的值自动递增;
都支持 ID 值查询函数 IDENT_SEED、IDENT_INCR、IDENT_CURRENT;
Truncate 表之后,ID 值都能重置(注意:直接在 PostgreSQL 中创建的 Identity 列是不重置的,Babelfish 则兼容 SQL Server 的行为);
如果想要显式向 ID 列插入特定的数值,必须启用 IDENTITY_INSERT 选项,该选项自动将 ID 值更新为 ID 列的最大值。
不同点:
当 ID 列中的数据类型为 numeric 和 decimal 时,SQL Server 支持的精度达到38位,而 Babelfish 支持的精度是19位;
对于 ID 值的重设以及指定 ID 值,在 SQL Server 中可以通过 DBCC(Database Console Commands)的 CHECKIDENT 命令来完成,而在 Babelfish 中则是需要通过直接调用 PostgreSQL 的 setval 序列函数来完成。
您可以通过下面的 SQL 语句在 Babelfish 中查询所有表中的 ID 列,而表相关的序列名则可通过 PostgreSQL 连接查询系统表 pg_class,ID 列使用的序列名通常为:“表名_自增列名_SEQ”。
select b.name as [Table_Name] ,a.name as [Identity_Column]
from sys.columns a inner join sys.tables b on b.object_id=a.object_id
where is_identity = 1左滑查看更多
需要注意的是,当带有 ID 列的表数据从源端迁移到 Babelfish 目标端时,Babelfish 中的 ID 值并不会自动设置,ID 值仍为初始化建表时的值。当插入新数据时,会出现由于 ID 值重复而导致违反唯一约束的错误,您需要手工设置 ID 值。下图中的案例展示了使用 bcp 迁移一张包含1千万行数据的名为“transdata”的表到 Babelfish 后,检查表中的 ID 列“empno”的 ID 值并没有更新,需要手工更新的过程。
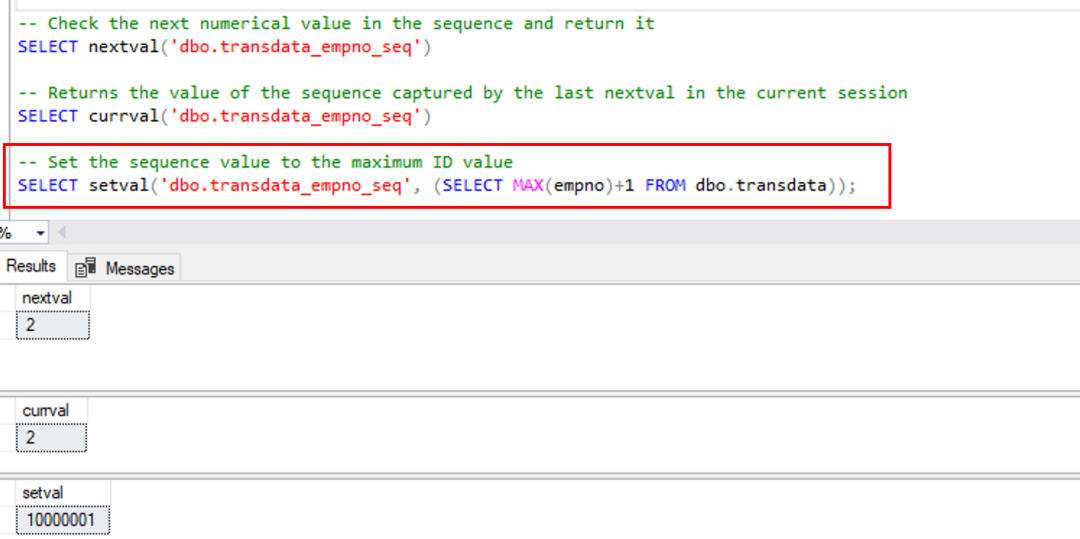
鉴于 Identity 属性在数据库中使用非常广泛,您需要清楚地了解它在 Babelfish 和 SQL Server 中的差异,特别是管理 ID 值时需要将 SQL Server 的 DBCC 命令更换为 PostgreSQL 的序列函数(可以在 Babelfish 中直接调用)。对于包含 ID 列的数据迁移到 Babelfish 后的检查,我们推荐使用以下 SQL 语句生成脚本来批量重新设置所有表中 ID 列的 ID 值(此 SQL 适用于单库迁移模式,多库模式的话请修改拼接的序列名中前缀“dbo”为“库名_dbo”)。
select 'SELECT setval('+concat(char(39),'dbo.')+b.name+'_'+a.name+'_seq'+concat(char(39))+','+'(SELECT MAX('+a.name+')+1 FROM dbo.'+b.name+'));'
from sys.columns a inner join sys.tables b on b.object_id=a.object_id
where is_identity = 1左滑查看更多
3.2 互操作性
Babelfish 提供双端口访问,支持 T-SQL 和 PostgreSQL,数据和其他对象都存放在底层 PostgreSQL 数据库中。如果您的开发场景中涉及到两者之间的相互访问,请注意架构名称、标识符、权限、事务语义、多个结果集和默认排序规则在两者之间的差异以避免可能的潜在问题。以下是互操作中遇到的一些典型案例和具体建议。
1)创建对象
Babelfish 所有的对象和数据都是存放 Aurora PostgreSQL 集群下固定名称为 Babelfish_db 的数据库中,您可以通过 Babelfish 连接或 PostgreSQL 连接来创建对象,然后互相进行访问和操作,但对于此类行为谨记需要注意两点:
在启用 Babelfish 选项时可以选择本地化的字符排序集,而 Babelfish_db 创建时默认是 UTF-8。如果创建对象时使用默认设置,则在一边创建的对象在另外一边访问时可能会遇到排序集的问题。
权限问题,简单来说就是通过 PostgreSQL 连接创建的对象需要授予相应权限才能在 Babelfish 中查看,反之则不需要。
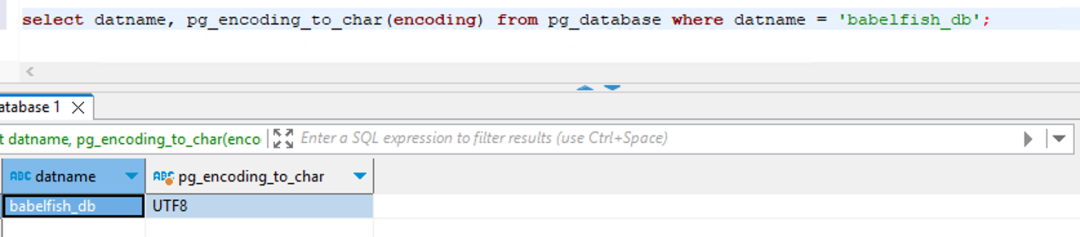
让我们来看看针对第一个问题的具体案例,首先我们检查从不同连接中看到的数据库默认排序集,PostgreSQL 连接看到的 Babelfish_db 是 UTF8 的排序集。
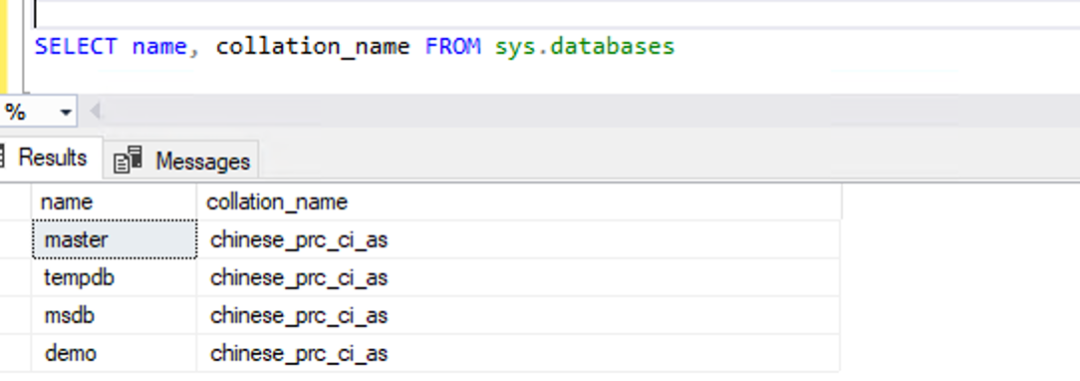
而 Babelfish 连接显示的是创建 Aurora PostgreSQL 集群时设置 Babelfish 选项中选择的排序集,我们测试环境使用的是 chinese_prc_ci_as 排序集,这是一个支持中文且大小写不敏感的排序集。
接下来我们使用相同的 DDL 建表语句在两边创建两张表:
通过 PostgreSQL 连接来创建:create table dbo.t1 (a varchar(10) not null unique)
通过 Babelfish 连接来创建:create table dbo.t2 (a varchar(10) not null unique)
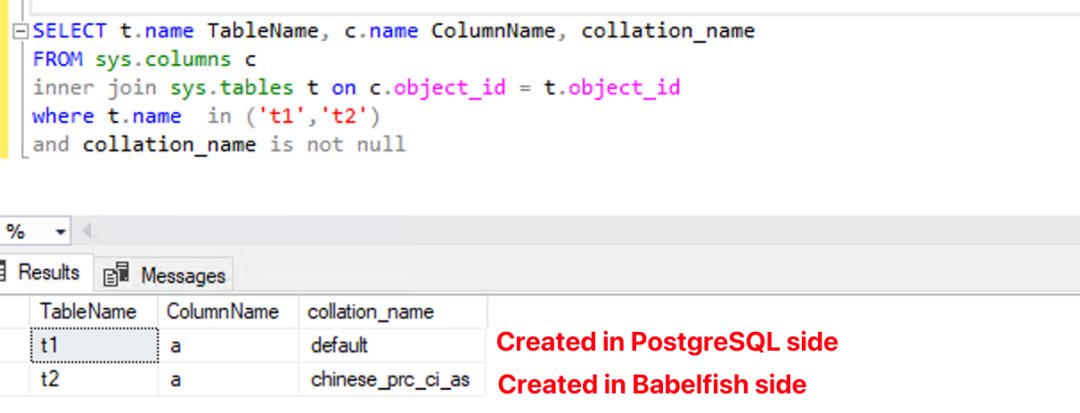
创建成功后在 Babelfish 中查看两张表中字符类型字段的排序集:
SELECT t.name TableName, c.name ColumnName, collation_name
FROM sys.columns c
inner join sys.tables t on c.object_id = t.object_id
where t.name in ('t1','t2')
and collation_name is not null左滑查看更多
查询结果显示:建表 DDL 语句中如果没有指定表中字符型字段的排序集的话,它就会使用所在库中默认的排序集。
对于 varchar(10)的字段,我们在两张表上分别插入多个中文字符来测试,结果显示在 PostgreSQL 中创建的默认为 UTF8 排序集的表可以插入最多10个中文字符。这是因为首先 UTF8 可存储 Unicode 编码,其次 Postgre SQL 中 varchar(n)定义的是存储长度最多为 n 个字符(而不是字节)的字符串,对于此字段类型的详细说明可以参考 PosgreSQL 的使用手册。
而在 Babelfish 中创建的中文排序集的表最多只能插入5个中文字符,这是符合预期的 SQL Server 行为,因为对于 Chinese_PRC_CI_AS 排序规则来说,varchar 类型的列使用 ANSI 编码,也即 GBK 编码存储中文数据。SQL Server 字段 varchar(n)最多使用 n 个字节来存储数据。最多存储 n 个英文字母或 n/2 个汉字,字段定义的差异请参考 SQL Server 的使用手册。
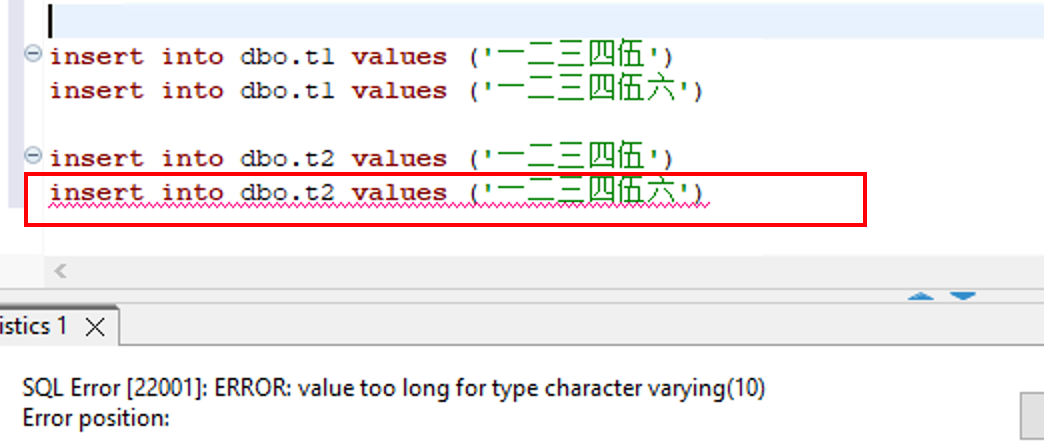
当在 Babelfish 中查询在 PostgreSQL 中创建的表 t1 时,查询大于5个中文字符的数据时,出现了长时间的等待,这是由于在 Babelfish 中通过语义转换解析字段定义值和实际字符值长度不匹配导致的问题。
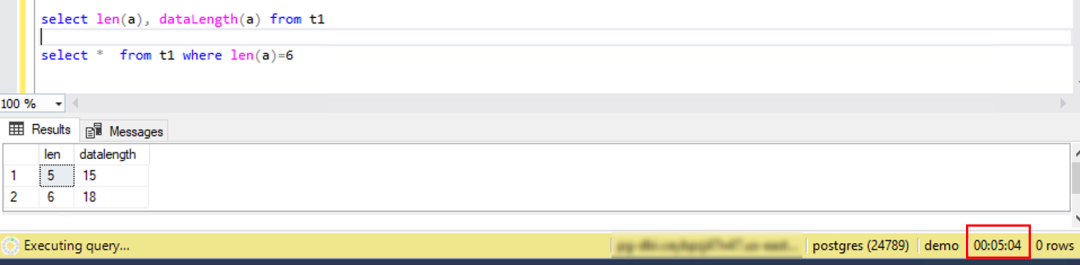
以上就是 Babelfish 开发中互操作性的一个简单案例,这个问题很容易被忽视,但它造成的影响却不可低估。我们建议在此类通过两种连接都能创建对象,并可互相访问的交互性操作的场景中,选择预期使用频次最多的连接方式来操作,同时务必注意两边的差异。另外,存储英文之外的多语言字符数据时,建议使用 nchar/nvarchar 而不是 char/varchar 的字段类型,因为前者能存储 Unicode 字符,同时也能避免出现字符乱码问题。更多的 Babelfish 上和排序集相关的差异及限制,请参考 Babelfish 的使用手册。
2)标识符
PostgreSQL 的最大标识符长度为63个字符,而 SQL Server 最多支持128个字符。此外,PostgreSQL 对索引名称的唯一性要求更严格。Babelfish 通过在内部附加或替换部分此类标识符来处理这些限制,该字符串表示标识符的哈希值。虽然这在 T-SQL 中是透明的,但从 PostgreSQL 中看到的对象名称是带有哈希的标识符。
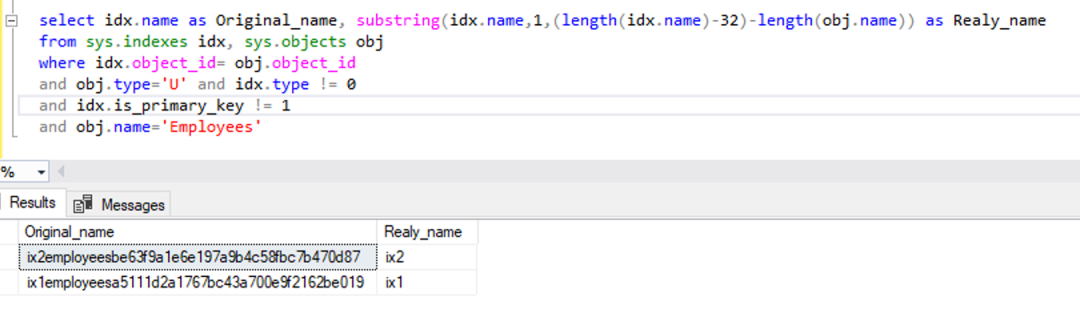
Babelfish 将索引名称与表名称连接起来,并连接使用 MD5 生成的字符串作为小写索引名称。某些场景下需要对索引进行删除操作,此时就需要获取真实的索引名,以下的 SQL 语句将系统视图中存放的索引名进行转换,能显示原始的索引名。注意:当原始索引名称超长时,无法进行转换。
select idx.name as Original_name, substring(idx.name,1,(length(idx.name)-32)-length(obj.name)) as Realy_name
from sys.indexes idx, sys.objects obj
where idx.object_id= obj.object_id
and obj.type='U' and idx.type != 0
and idx.is_primary_key != 1
and obj.name='Employees'左滑查看更多
下图显示了此查询语句的执行结果:
3)访问权限
Babelfish 的交互式的操作,可以使用不同的连接端口创建的对象,再从另一端来访问。此类操作可能会涉及到对象访问的权限问题,Babelfish 的设计可以保证:通过 Babelish 连接来创建的表或其他 SQL 对象,在使用相同的用户通过 PostgreSQL 连接时,可以使用相同的权限访问,而不需要运行任何额外的 PostgreSQL 语句。然而,不能保证另一种方式:通过 PostgreSQL 连接创建的对象,它可能无法从 TDS 连接中看到或访问,或者可以使用不同的权限访问。
以下展示的即为关于权限访问的案例:
1#. 首先通过 Babelfish 连接并以主用户(postgres)创建一张表 t1:create table t1(a int not null)
2#. 然后通过 PostgreSQL 连接以相同的用户(postgres)查询表 t1(需要加 schema 名),返回结果显示能正常访问
3#. 通过 PostgreSQL 连接也创建一张表 t2:create table dbo.t2(a int not null)
4#. 通过 Babelfish 连接查询在 PostgreSQL 中创建的表 t2,返回权限拒绝错误
5#. 通过 PostgreSQL 连接执行 Grant 语句,在 t2 上赋予相应的权限给 dbo schema

6#. 再次通过 Babelfish 连接查询表 t2,结果返回正常,两次查询的返回结果如下:

理解 Babelfish 中互操作性的权限问题,结合前文所谈论的对象操作,我们建议在选择使用何种连接来创建对象时,同时也需考虑对象创建之后的访问问题,并准备好必需的相关权限添加的 SQL 语句。
4)事务语义
SQL Server 和 PostgreSQL 在事务语义和处理上是有所区别得,具体而言,在一个 Begin…End 块中,当遇到出错的 SQL 语句时,SQL Server 由于使用了保存点,可以仅回滚出错的 SQL 语句,而 PostgreSQL 则会回滚所有的 SQL 语句。
当通过 Babelfish 连接来执行 SQL 语句时,将应用 T-SQL 事务语义;而当通过 PostgreSQL 连接时,将应用 PostgreSQL 事务语义。但在连接中混合或组合两种语言时,原则上会忽略 T-SQL 事务语义,只使用 PostgreSQL 语义。这可能意味着 T-SQL 过程在 PostgreSQL 上下文中执行时可能会有不同的行为。
实际当中,这是一种常见的场景:Babelfish 当前版本中一些不兼容的特性,需要通过 PostgreSQL 的连接来创建过程/函数,并在 Babelfish 中通过 T-SQL 调用来解决,那么对于这些可编程对象,在此类混用的场景下该如何处理?以下,让我们通过一个 T-SQL 调用 PostgreSQL 编程对象的案例来了解。
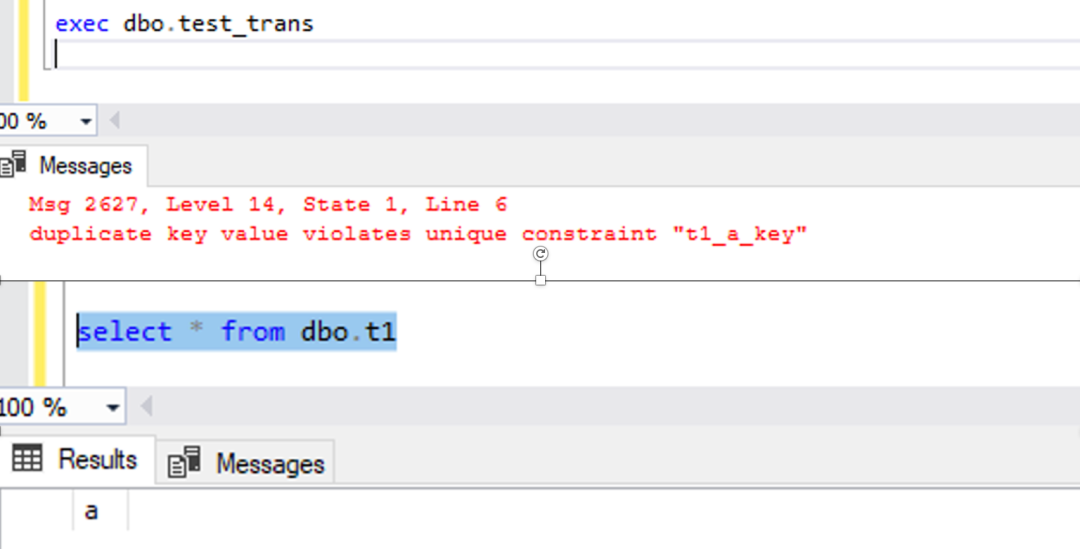
首先通过 PostgreSQL 连接来创建一个存储过程,里面是一些 DML 语句,使用的是默认的 plpgsql 语言。
CREATE or replace PROCEDURE dbo.test_trans()
LANGUAGE plpgsql
AS $$
BEGIN
truncate table dbo.t1;
insert into dbo.t1 values('1');
insert into dbo.t1 values('2');
insert into dbo.t1 values('3');
update dbo.t1 set a = '4';
END
$$;左滑查看更多
在 Babelfish 中调用执行这个过程,可以看到,执行时当遇到约束错误时,遵照了 PostgreSQL 的语义,回滚全部语句。
接下来,我们在 PostgreSQL 连接中修改存储过程,唯一的变动就是将 LANGUAGE plpgsql 修改为 LANGUAGE pltsql ,再次在 Babelfish 中执行,这次我们看到,修改后存储过程按照 SQL Server 的语义,仅回滚失败的 DML 语句。
以上的案例展示了在 Babelfish 和 PostgreSQL 互操作中,对于事务语义的控制,使用语言关键字来标识,可以保证事务按照预期的行为来处理,这对 Babelfish 中不兼容特性的处理提供了一个稳定的解决方案。
04
总结
本文是“基于 Babelfish 的 T-SQL 代码开发最佳实践”系列的第一篇,在此我们向读者介绍了 Babelfish 的软件架构、开发模式、开发中的常见问题,并通过具体案例展示了 T-SQL 开发的一些最佳实践指引。Babelfish 从2021年推出至今,已经经历了多次的版本迭代,每次迭代都会推出一些重要功能,包括对 SQL Server 兼容性的优化,建议您在规划和使用 Babelfish 时检查最新的 Babelfish 的特性支持说明,采用最新的特性进行 T-SQL 的开发。
本篇作者

唐晓华
亚马逊云科技数据库解决方案技术专家,二十余年数据库行业经验,负责基于亚马逊云计算数据库产品的技术咨询与解决方案工作。专注于云上关系型数据库架构设计、测试、运维、优化及迁移等工作。

张子曼
亚马逊云科技解决方案架构师,负责基于亚马逊云计算方案架构的咨询和设计,在国内推广 亚马逊云平台技术和各种解决方案。专注于 Serverless 和数据库等技术方向。
2023亚马逊云科技中国峰会即将开启!
👇👇👇点击下方图片即刻注册👇👇👇


听说,点完下面4个按钮
就不会碰到bug了!
















 8541
8541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









