









本章节通过spark-shell进入我们的单机spark的终端进行一些简单的运算。
本节内容如下
- 新建RDD 进行乘法操作
- 新建RDD 进行过滤操作
- 编写wordCount小例子
- union的使用
- groupByKey
- join
- reduce
- lookup
首先安装和启动spark,此部分请参照
启动后进入spark 的bin 目录运行spark-shell 进入终端。
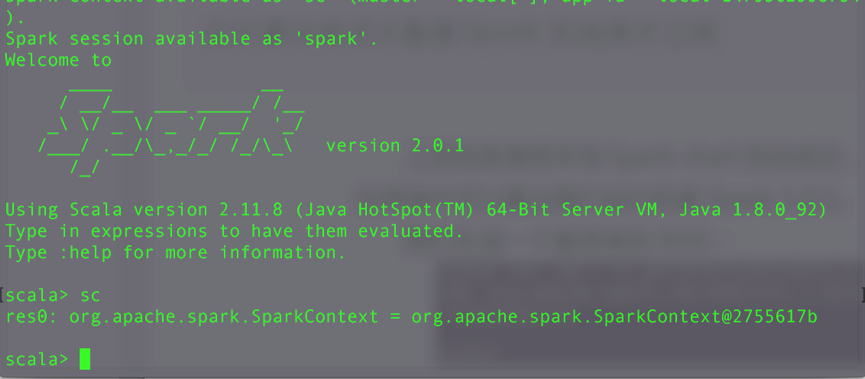
./spark-shell进入终端后输入sc,查看一下Spark-shell 帮我们自动生成的 SparkContext 的 实例。
结果如下图
1.新建RDD进行乘法操作
1.1 我们生成一个最简单的 List集合RDD:
//注意List大写
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9))
1.2 对集合的每个元素都乘以3
//rdd每个数都乘以3
val mappedRDD=rdd.map(3*_)
1.3 通过collect 查看结果
//计算结果
mappedRDD.collect
2.新建RDD 进行过滤操作
2.1 查看mappedRDD
mappedRDD
2.2 使用filter 过滤大于10 的
mappedRDD.filter(_>10)
2.3 查看结果

2.4 函数式编程,符合scala风格写法,也符合Spark的应用风格写法。在spark编程中,大多数功能实现之用一行代码即可实现
过滤操作如下:
val filteredRDDAgain=sc.parallelize(List(1,2,3,4,5,6,7,8,9)).map(3*_).filter(_>10).collect
3.编写wordCount小例子
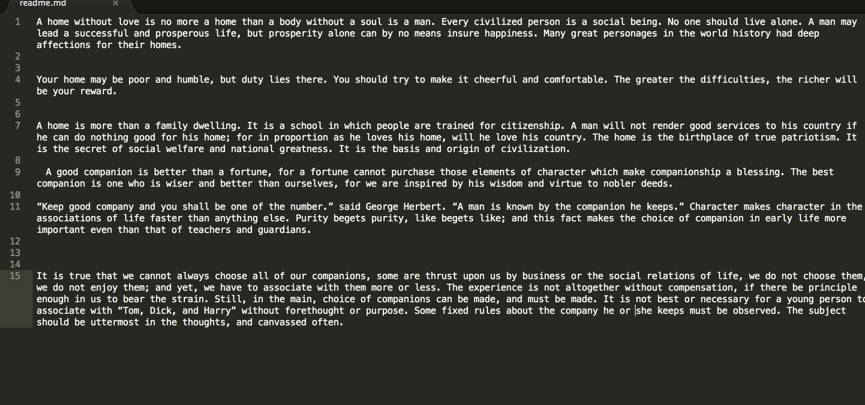
3.1 新建一个用于读取的文件(我的文件名叫做readme.md),内容是我粘贴的英文句子如下:
3.2 新建RDD读取文件
// "/Users/yangyibo/data/readme.md"是文件路径
val rdd =sc.textFile("/Users/yangyibo/data/readme.md")
3.3 统计readme.md 文件的行数
rdd.count
3.4 统计单词的个数
val wordcount=rdd.flatMap(_.split(' ')).map((_,1)).reduceByKey(_+_)
3.5 查看结果
wordcount.collect
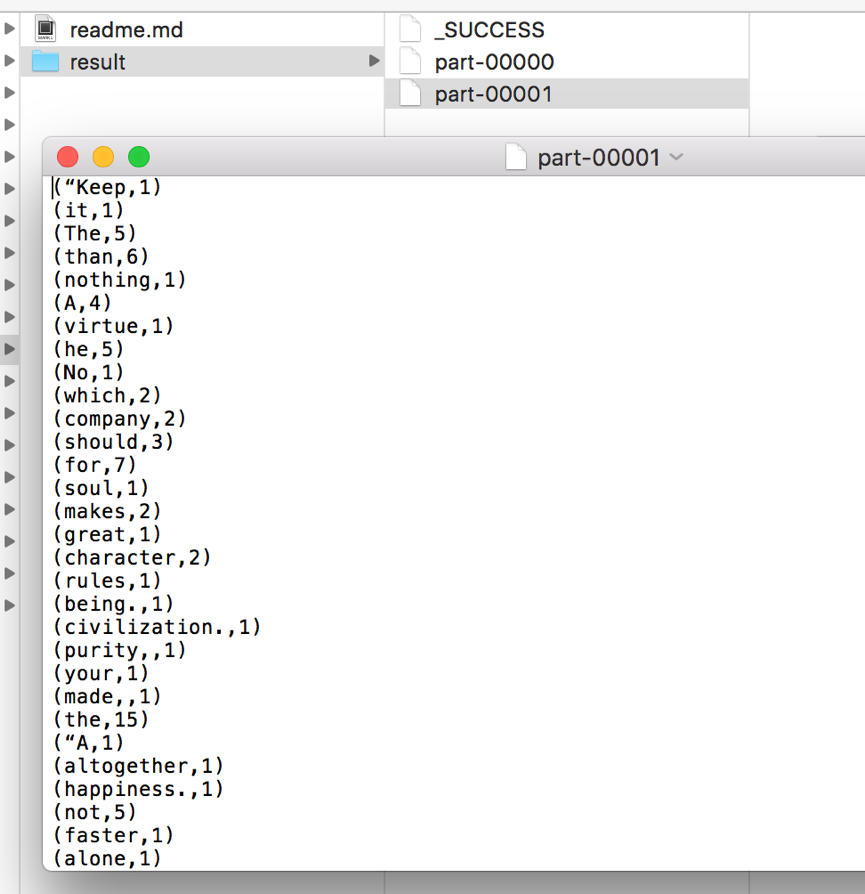
3.6 存储统计结果
//存储结果的路径/Users/yangyibo/data/result
wordcount.saveAsTextFile("/Users/yangyibo/data/result")
返回结果如下
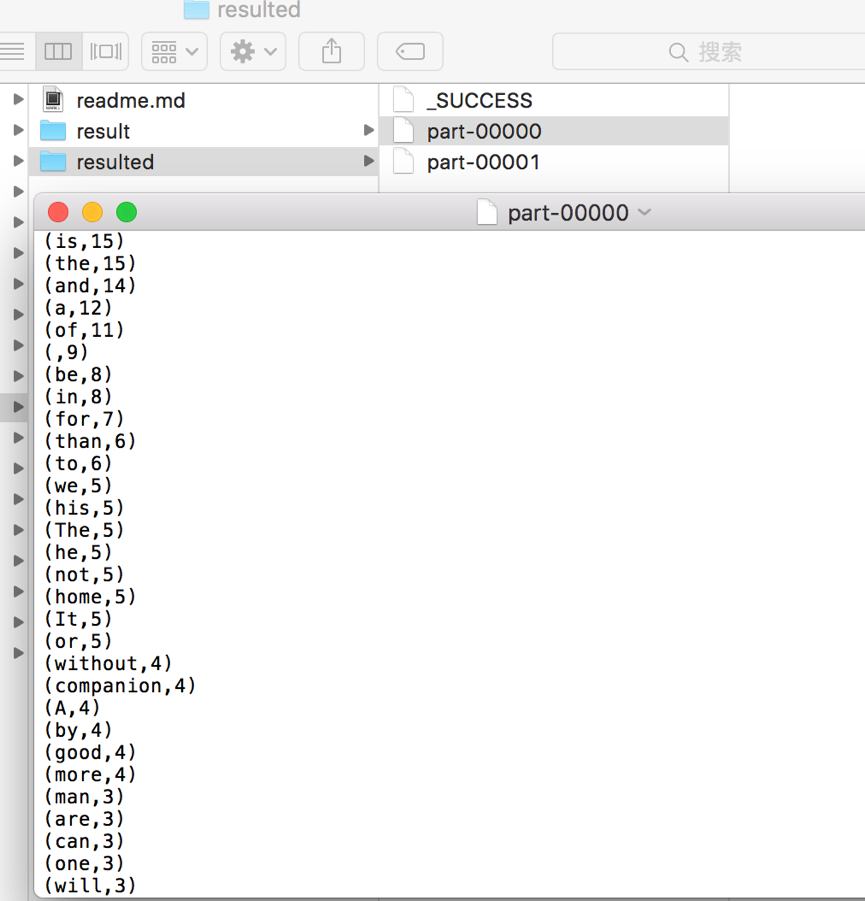
3.7 对分析结果进行排序输出
//”/Users/yangyibo/data/resulted”排序输出的输出文件路径
val wordcount=rdd.flatMap(_.split(' ')).map((_,1)).reduceByKey(_+_).map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1)).saveAsTextFile("/Users/yangyibo/data/resulted")
文件结果如下,按出现次数倒序排序
4.union 的使用(去重)
4.1 生成两个rdd ,进行union 匹配
val rdd1=sc.parallelize(List(('a',1),('b',1)))
val rdd2=sc.parallelize(List(('c',1),('d',1)))
4.2 查看结果
(rdd1 union rdd2).collect
5.groupByKey
5.1 新建RDD
val wordcount=rdd.flatMap(_.split(' ')).map((_,1)).groupByKey5.2 查看结果
wordcount.collect
6.join
join操作就是一个笛卡尔积操作的过程
6.1产生两个RDD
val rdd1=sc.parallelize(List(('a',1),('a',2),('b',3),('b',4)))
val rdd2=sc.parallelize(List(('a',5),('a',6),('b',7),('b',8)))
6.2 对rdd1和rdd2进行join
(rdd1 join rdd2).collect
7.reduce
reduce本身在 RDD 操作中属于一个 action 类型的操作,会导致 Job 的提交和执行
7.1生产一个RDD
val rdd = sc.parallelize(List(1,2,3,4,5,6))
7.2 对list求和
rdd.reduce(_+_) 
8.lookup (查找)
8.1 新建一个RDD
val rdd2=sc.parallelize(List(('a',5),('a',6),('a',7),('b',8),('b',9)))
8.2 查找key 是’a’ 的值
rdd2.lookup('a')
本节介绍结束,接下来就是idea 编写代码实战了。
idea 构建maven 管理的spark项目















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









