







http://blog.chinaunix.net/uid-20788636-id-4838269.html
RPS/RFS 功能是在Linux- 2.6.35中有google的工程师提交的两个补丁,这两个补丁的出现主要是基于以下两点现实的考虑:
(1) 这两个补丁的出现,是由于服务器的CPU越来越强劲,可以到达十几核、几十核,而网卡硬件队列则才4个、8个,这种发展的不匹配造成了CPU负载的不均衡。
(2) 上面的提到的是多队列网卡的情况,在单队列网卡的情况下,RPS/RFS相当于在系统层用软件模拟了多队列的情况,以便达到CPU的均衡。
出现RFS/RPS的原因主要是由于过多的网卡收包和发包中断集中在一个CPU上,在系统繁忙时,CPU对网卡的中断无法响应,这样导致了服务器端的网络性能降低,从这里可以看出其实网络性能的瓶颈不在于网卡,而是CPU,因为现在的网卡很多都是万兆并且多队列的,如果有过多的中断集中在一个CPU上,将导致该CPU无法处理,所以可以使用该方法将网卡的中断分散到各个CPU上。但对于CentOS 6.1已经支持了。
当网卡驱动加载时,通过获取的网卡型号,得到网卡的硬件queue的数量,并结合CPU核的数量,最终通过Sum=Min(网卡queue,CPU core)得出所要激活的网卡queue数量(Sum),并申请Sum个中断号,分配给激活的各个queue,当某个queue收到报文时,触发相应的中断,收到中断的核,将该任务加入到协议栈负责收包的该核的NET_RX_SOFTIRQ队列中(NET_RX_SOFTIRQ在每个核上都有一个实例),在NET_RX_SOFTIRQ中,调用NAPI的收包接口,将报文收到有多个netdev_queue的net_device数据结构中。
当CPU可以平行收包时,就会出现不同的核收取了同一个queue的报文,这就会产生报文乱序的问题,解决方法是将一个queue的中断绑定到唯一的一个核上去,从而避免了乱序问题。
查看网卡是否支持MSI-X可以直接查看 interrupts 文件,看关键字 MSI 就知道了:
# grep -i msi /proc/interrupts
在Broadcom的网卡手册上有关于MSI和MSI-X的定义:
MSI Version. This is the Message Signaled Interrupts (MSI) version beingused. The option MSI corresponds to the PCI 2.2 specification that supports 32messages and a single MSI address value. The option MSI-X corresponds to thePCI 3.0 specification that supports 2,048 messages and an independent messageaddress for each message.
实际应用场景中,MSI方式的中断对多核cpu的利用情况不佳,网卡中断全部落在某一个cpu上,即使设置cpu affinity也没有作用,而MSI-X中断方式可以自动在多个cpu上分担中断。
RPS(Receive Packet Steering)主要是把软中断的负载均衡到各个cpu,简单来说,是网卡驱动对每个流生成一个hash标识,这个HASH值得计算可以通过四元组来计算(SIP,SPORT,DIP,DPORT),然后由中断处理的地方根据这个hash标识分配到相应的CPU上去,这样就可以比较充分的发挥多核的能力了。通俗点来说就是在软件层面模拟实现硬件的多队列网卡功能,如果网卡本身支持多队列功能的话RPS就不会有任何的作用。该功能主要针对单队列网卡多CPU环境,如网卡支持多队列则可使用SMP irq affinity直接绑定硬中断。
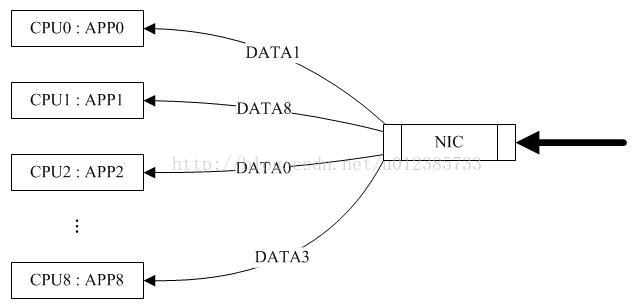
图1 只有RPS的情况下(来源网络)
由于 RPS 只是单纯把数据包均衡到不同的 cpu ,这个时候如果应用程序所在的 cpu 和软中断处理的 cpu 不是同一个,此时对于 cpu cache 的影响会很大,那么 RFS ( Receive flow steering )确保应用程序处理的 cpu 跟软中断处理的 cpu 是同一个,这样就充分利用 cpu 的 cache ,这两个补丁往往都是一起设置,来达到最好的优化效果 , 主要是针对单队列网卡多cpu的环境。
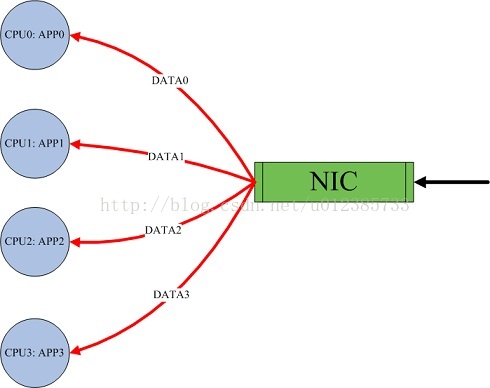
图2:同时开启RPS/RFS后(来源网络)
rps_flow_cnt,rps_sock_flow_entries,参数的值会被进位到最近的2的幂次方值,对于单队列设备,单队列的rps_flow_cnt值被配置成与 rps_sock_flow_entries相同。
RFS依靠RPS的机制插入数据包到指定CPU的backlog队列,并唤醒那个CPU来执行
RSS(receive side scaling)是有微软提处理,通过这项技术能够将网络流量分载到多个cpu上,降低单个cpu的占用率。默认情况下,每个cpu核对应一个rss队列。ixgbe驱动将收到的数据包的源、目的ip地址和端口号,交由网卡硬件计算出一个rss hash值,再根据这个hash值来决定将数据包分配到哪个队列中。通过cat /proc/interrupts |grep 网卡名的方式,就可以看到网卡使用了几个rss通道。
RSS(Receive-side scaling,接收端调节)技术,RSS是和硬件相关联的,必须要有网卡的硬件进行支持,RSS把发数据包分配到不同的队列中,其中HASH值的计算式在硬件中完成的,然后通过affinity的调整把不同的中断映射的不同的Core上。下面是Linux内核对RFS和RSS描述。
For a multi-queue system, if RSS is configured so that a hardware
receive queue is mapped to each CPU, then RPS is probably redundant
and unnecessary. If there are fewer hardware queues than CPUs, then
RPS might be beneficial if the rps_cpus for each queue are the ones that
share the same memory domain as the interrupting CPU for that queue.
在Intel架构上的一些硬件上是有该功能的。
On the Intel architecture, multi-queue NICs use MSI-X (the extendedversion of Message Signaled Interrupts) to send interrupts to multiple cores.The feature that distributes arriving packets to different CPUs based on(hashed) connection identifiers is called RSS (Receive Side Scaling) on Inteladapters, and its kernel-side support on Windows was introduced as part ofthe Scalable Networking Pack in Windows 2003 SP2.
This performanceenhancement works as follows: Incoming packets are distributed over multiplelogical CPUs (e.g. cores) based on a hash over the source and destination IPaddresses and port numbers. This hashing ensures that packets from the samelogical connection (e.g. TCP connection) are always handled by the sameCPU/core. On some network adapters, the work of computing the hash can beoutsourced to the network adapter. For example, some Intel and Myricom adapterscompute a Toeplitz hashfrom these header fields. This has thebeneficial effect of avoiding cache misses on the CPU that performs thesteering - the receiving CPU will usually have to read these fields anyway.
Receive-Side Scaling (RSS), also known as multi-queue receive, distributesnetwork receive processing across several hardware-based receive queues,allowing inbound network traffic to be processed by multiple CPUs. RSS can beused to relieve bottlenecks in receive interrupt processing caused byoverloading a single CPU, and to reduce network latency。(https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Performance_Tuning_Guide/network-rss.html)
通过上面的介绍可以知道,对于RSS和RFS的区别,它们都是把同一个流的数据包给同一个CPU,但是RSS是使用硬件实现的,而RFS是纯软件实现的。
SMP IRQ affinity Linux 2.4内核之后引入了将特定中断绑定到指定的CPU的技术,称为SMP IRQ affinity。
smp_affinity是否需要设置,根据网卡是否支持多队列,如果网卡支持多队列则设置才有作用,如果网卡有多队列,就会有多个中断号,这样就可以把不同的中断号分配到不同CPU上,这样中断号就能相对均匀的分配到不同的CPU上。
这里简单的理解一下,smp_affinity值得映射关系,下面简单的举个例子:
如果cat /proc/irq/84/smp_affinity的值为:20(二进制为:00100000),则84这个IRQ的亲和性为#5号CPU。
每个IRQ的默认的smp affinity在这里:cat /proc/irq/default_smp_affinity,默认值是全F。
但是对于单队列的网卡配置「smp_affinity」和「smp_affinity_list」对多CPU无效。
如果是单队列的话/proc/sys/net/core/rps_sock_flow_entries值和rps_flow_cnt设置为相同,rps更多的是针对网卡驱动是NAPI方式的,如果应用场景更多是内核的forward,RPS就足够了,再在该基础上使用RFS也不会有性能的提升。
在执行脚本向/sys/class/net/eth0/queues/rx-0/rps_cpus文件中写对应的数据时,提示
./set_irq_affinity.sh
./set_irq_affinity.sh: line 52: echo: write error: Value too large fordefined datatype
这是由于rps_cpus文件中的数,需要和CPU的个数相匹配,当写入的数据大于CPU的个数时,会出现上面的错误提示信息。
可使用逗号为不连续的 32 位组限定 smp_affinity 值。在有 32 个以上核的系统有这个要求。例如:以下示例显示在一个 64 核系统的所有核中提供 IRQ 40。
# cat /proc/irq/40/smp_affinity
ffffffff,ffffffff
在 64 核系统的上 32 核中提供 IRQ 40,请执行:
# echo 0xffffffff,00000000 > /proc/irq/40/smp_affinity
# cat /proc/irq/40/smp_affinity
ffffffff,00000000
RFS需要内核编译CONFIG_RPS选项,RFS才起作用。全局数据流表(rps_sock_flow_table)的总数可以通过下面的参数来设置:
/proc/sys/net/core/rps_sock_flow_entries
每个队列的数据流表总数可以通过下面的参数来设置:
/sys/class/net/<dev>/queues/rx/rps_flow_cnt
echo ff > /sys/class/net//queues/rx-/rps_cpus
echo 4096 > /sys/class/net//queues/rx-/rps_flow_cnt
echo 30976 > /proc/sys/net/core/rps_sock_flow_entries
对于2个物理cpu,8核的机器为ff,具体计算方法是第一颗cpu是00000001,第二个cpu是00000010,第3个cpu是 00000100,依次类推,由于是所有的cpu都负担,所以所有的cpu数值相加,得到的数值为11111111,十六进制就刚好是ff。而对于 /proc/sys/net/core/rps_sock_flow_entries的数值是根据你的网卡多少个通道,计算得出的数据,例如你是8通道的网卡,那么1个网卡,每个通道设置4096的数值,8*4096就是/proc/sys/net/core/rps_sock_flow_entries 的数值,对于内存大的机器可以适当调大rps_flow_cnt,
参考文献:
http://blog.csdn.net/turkeyzhou/article/details/7528182
http://lwn.net/Articles/328339/

















 1710
1710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









