






Pseudo-Label:深度学习中一种简单有效的半监督方法
1 摘要
提出了一种简单有效的深度神经网络半监督学习方法。基本上,该网络采用带标签和无标签数据同时训练的监督方式。对于未标记的数据,伪标记,只是选取具有最大预测概率的类,就像它们是真实的标签一样使用。这实际上相当于熵正则化。它倾向于类与类之间的低密度间隔,这是半监督学习通常假定的前提。在MNIST手写体十位数数据集上,采用Denoising Auto-Encoder 和Dropout,这种方法在小数据集上MNIST的表现非常突出。
译者笔记:先用有标记的数据训练模型,然后再用这个模型训练无标记数据,给无标记数据一个Pseudo-label,在MixMatch中就叫guess label,猜测标签。然后用这个带伪标签的数据,对原有标记的数据做一个数据扩容。而MixMatch是不断循环迭代,不仅model进行迭代,guess label也要进行迭代。不断迭代的话,一则model是否收敛需要证明,二则时间上会很复杂。很有可能限制了MixMatch在深度学习模型上的应用。不过在本文中对为什么伪标签有效进行了一个说明,用entropy regularization 进行解释,是比较巧妙的。如果一次伪标签有效,那么多次伪标签也应该是有效的,具体的还要看实验结果。
2 介绍
近年来,深度神经网络在人工智能的硬任务中取得了巨大的成功。所有成功的训练深度神经网络的方法都有一个共同点:它们依赖于无监督学习算法。大多数工作分为两个主要阶段。在第一阶段,无监督预训练中,所有层的权值都由这种分层的无监督训练初始化。在第二阶段,微调,权值是全球训练标签使用反向传播算法在监督的方式。所有这些方法也以半监督的方式工作。我们只需要使用额外的未标记数据进行无监督的预培训。
本文提出了一种简单的半监督神经网络训练方法。该网络基本上是同时训练有标记和无标记数据的有监督中。对于未标记的数据,伪标签,只是选取每次权值更新的预测概率最大的类,就像它们是真实的labels一样使用。原则上,该方法可以将几乎所有的神经网络模型与训练方法相结合。在我们的实验中,去噪自动编码器和dropout提高了效果。
这种方法实际上相当于Entropy Regularization。这种关于类别概率的conditional entropy,用于衡量每一个类别之间的重叠量。通过最小化未标记数据的熵,可以减少类概率分布的重叠。它倾向于类与类之间的低密度间隔,这是半监督学习的普遍假设。
3 深度学习伪标签
3.1 深度神经网络
神经网络
伪标签是一种半监督训练深度神经网络的方法。在本文中,我们将考虑具有M层隐藏单元的多层神经网络:
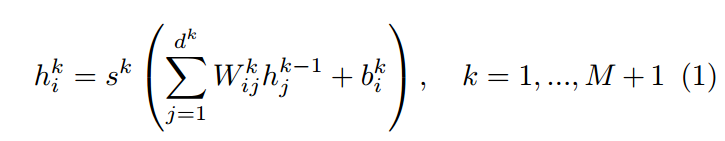
- S^k 是第k层的一种非线性的激活函数,就像是sigmoid那种。
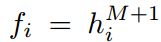 就是输出的预测的目标
就是输出的预测的目标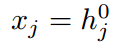 是输入的函数
是输入的函数
激活函数
Sigmoid Unit 是神经网络中最常用的单元之一。这个激活值通常代表二进制概率
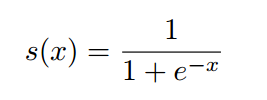
当输出使用sigmoid单位而不是soft max时,我们假设每个标签的概率彼此独立。虽然我们的实验数据集的标签是相互排斥的,但为了最大限度地利用sigmoid的饱和区域,我们使用了sigmoid输出单元。
近年来,Rectified Linear Unit (ReLU)受到了广泛的关注。本机组采用ReLU:
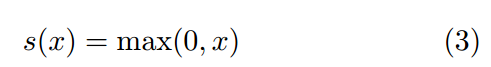
损失函数
整个网络可以通过最小化可容许损失函数来训练
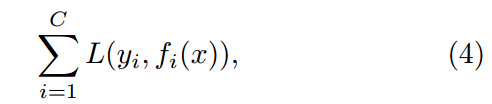
- C是标签的数量
- y是第i个label
- fi 是第i个输出值
- x 是输入向量
== 交叉熵==
如果我们用sigmoid 输出单元,我们可以选择交叉熵作为损失函数:
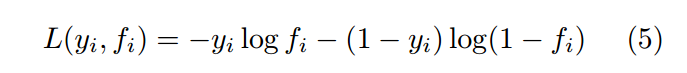
编者笔记:其实y就是实际label,fi就是模型在x下的输出值。交叉熵就是衡量二者之间差距的一个熵值,这里就是一个很普通的M层的深度神经网络(M一般大于3)
3.2 Denoising Auto-Encoder 去噪自编码器
自编码去噪是一种无监督学习算法,其思想是使所学习的代表方向对inpu模式的部分破坏具有鲁棒性(Vincent et al., 2008)。该方法可用于训练自动编码器,并可将这些DAE叠加起来初始化深度神经网络。
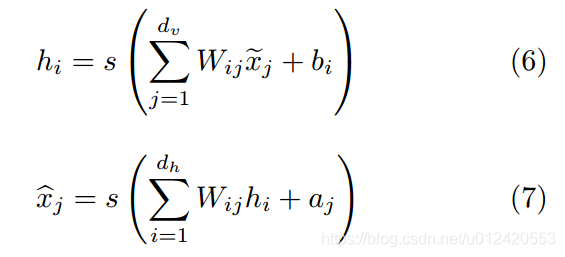
在那里;为损坏版本的第j个输入值,C;为第j个输入值的重构。Au码员的训练主要包括最小化之间的侦察结构误差;对于二进制输入值,重构误差的一般选择是交叉熵:
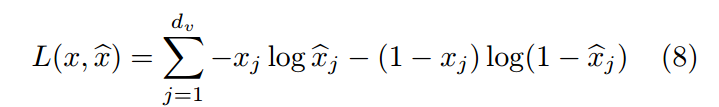
我们在无监督的训练前阶段使用DAE。掩蔽噪声的概率为0.5,用于corrup。与原始DAE不同的是,在我们的实验中,隐藏单元的掩蔽率也为0.5。此外,我们还使用了一个按顺序递减的学习率和线性递增的动量。这个方案的灵感来自于辍学。














 8125
8125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









