







1. Thread.yield方法声明把CPU让给其他具有相同优先级的线程去执行,不过这只是一个暗示,并没有保障机制
2. Executor
执行器,管理Thread对象。
语法demo:
ExecutorService exec=Executors.newCachedThreadPool();
for(int i=0;i<5;i++)
exec.execute(new XXX()); //XXX为实现Runnable接口的类
exec.shutdown();
三种类型及其区别:
CachedThreadPool:在程序执行过程中创建与所需数量相同的线程,在回收旧线程时停止创建新线程,是Executor首选。
FixedThreadPool: 一次性预先执行代价高昂的线程分配,可以限制线程的数量。
SingleThreadExecutor: 如果向其提交多个任务,那么这些任务排队,每个任务都在下个任务开始前结束,所有的任务使用相同的线程。
3.如何创建有返回值的线程
实现Callable接口,重写call()方法。
exec.submit(new XXX()) 会返回Future对象,用future.get()获取值,这个值是泛型的, 取决于实现接口时的声明,如 implements Callable<String> 则get到的是String类型
关于get: 可以先调用Future的isDone()方法来查询是否已经完成。任务完成时会具有一个结果,可以通过get来获取。如果不用isDone直接get,get会阻塞直到结果准备就绪。
4.通过编写定制的ThreadFactory可以定制由Executor创建的线程的属性(是否是后台,优先级,名称),
比如class MyThreadFactory implements ThreadFactory{
public Thread newThread(Runnable r) {
// TODO 自动生成的方法存根
Thread t=new Thread(r);
t.setDaemon(true); //设置为后台线程
return ..;
}
5. 守护线程中派生的子线程默认是守护线程,当所有的非守护线程结束时,后台线程终止,一旦main()退出,JVM会关闭所有的守护线程。
当所有的非后台线程结束时,程序就终止了。同时会杀死进程中所有后台线程。反过来说,只要有任何非后台线程还在运行,程序就不会终止。
6.线程join方法:
若在A线程中调用B.join,则A被挂起,直到B结束。在调用时也可以带上一个超时参数。 对join方法的调用可以被打断(通过在调用线程上调用interrupt()方法),这时被打断的B需要用到try-catch子句。(在run方法中,catch InterruptedException)
7.捕获线程抛出的异常
线程抛出的异常不能被正常的try catch到,可以用Executor解决这个问题:
如4中所示自定义一个myfactory类,在该factory的newThread方法中t.setUncaughtExceptionHandler(new XXX) ; XXX是实现了Thread.UncaughtExceptionHandler接口的类。 然后ExecutorService exec=Executors.newCachedThreadPool(new myfactory);
8. synchronized和Lock对象
synchronized:如果某个任务处于一个对标记为synchronized的调用中,那么在这个线程从该方法返回之前,其他所有要调用类中任何标记为synchronized方法的线程都会被阻塞。不过如果是synchronized(obj)方法块,只要obj不是相同的对象,两个方法不会因为另一个方法的同步而被阻塞
用synchronized时代码量更小,且不会出现忘了unlock这种情况,用Lock对象需要 lock(); try{ } finally{ unlock},避免在lock之后代码出现异常导致死锁。
显式使用lock对象可以解决更特殊的问题,比如尝试获取锁一段时间然后放弃、实现自己的调度算法等等。且在加锁释放锁方面有更细粒度的控制力。
ps:synchronized关键字不属于方法特征签名的组成部分,所以可以在覆盖方法的时候加上去。
9. volatile
一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份。
如果多个任务在同时访问某个域,这个域就应该时volatile的,否则只能由同步来访问。同步也会导致向主存中刷新。因此如果一个域完全由synchronized方法或语句块来防护,就不必将其设置为volatile。
long和double的读取写入可能不是原子的,因为long和double 64位,在32位机器上的读写操作会被当作两个分离的32位操作执行。如果使用volatile关键字,就会获得原子性。此关键字还确保了应用中的可视性。如果把一个域声明为volatile的,只要对这个域产生写操作,所有的读操作都可以看到这个修改。即便使用了缓存,volatile域会被立即写入到主存中,而读取操作发生在主存。如果域由synchronized方法或语句块防护,不必设置为volatile。使用volatile 而不是synchronized的唯一安全的情况是类中只有一个可变域。第一选择应该是synchronized。
10.同步控制块
亦称为临界区,在方法内部:
synchronized(syncObject){
}
11.ThreadLocal
当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
从线程的角度看,目标变量就象是线程的本地变量,这也是类名中“Local”所要表达的意思。
12.线程的暂停、继续、终止
wait,notify,exec.shutdownNow()
在Executor上调用shutdownNow(),将发送一个interrupt()调用给它启动的所有线程。(相当于xx.interrupt())
如果想中断某个单一任务,使用Executor.submit()而不是execute()来启动任务,返回一个Future<?> f,可以通过调用f.cancel(true)来中断。
可以中断对sleep的调用(或者任何要求抛出InterruptedException的调用),不能中断正在试图获取synchronized锁或者试图执行I/O操作的线程(办法是关闭任务在其上发生阻塞的底层资源)。
13.wait 和 notify
sleep和yield不释放锁,wait会释放锁
两种形式的wait:毫秒数作为参数或者不加参数
把wait、notify放在Object类中是因为这些方法操作的锁也是所有对象的一部分,所以可以把wait放进任何同步控制方法里,不需要考虑这个类是继承Thread还是实现Runnable接口。实际上,只能在同步控制方法或同步控制块里调用wait、notify。否则在运行时将得到IllegalMonitorStateException异常。调用这两个方法的任务在调用这些方法前必须拥有对象的锁。
notify()和notifyAll()都是Object对象用于通知处在等待该对象的线程的方法。
void notify(): 唤醒一个正在等待该对象的线程。
void notifyAll(): 唤醒所有正在等待该对象的线程。
两者的最大区别在于:
notifyAll使所有原来在该对象上等待被notify的线程统统退出wait的状态,变成等待该对象上的锁,一旦该对象被解锁,他们就会去竞争。notify他只是选择一个wait状态线程进行通知,并使它获得该对象上的锁,但不惊动其他同样在等待被该对象notify的线程们,当第一个线程运行完毕以后释放对象上的锁,此时如果该对象没有再次使用notify语句,即便该对象已经空闲,其他wait状态等待的线程由于没有得到该对象的通知,继续处在wait状态,直到这个对象发出一个notify或notifyAll,它们等待的是被notify或notifyAll,而不是锁。
可以用lock+condition来代替wait和notify,但是更复杂,只有在更加困难的多线程问题中才必需。
ReentrantLock
java.util.concurrent.lock 中的Lock 框架是锁定的一个抽象,它允许把锁定的实现作为 Java 类,而不是作为语言的特性来实现。这就为Lock 的多种实现留下了空间,各种实现可能有不同的调度算法、性能特性或者锁定语义。
ReentrantLock 类实现了Lock ,它拥有与synchronized 相同的并发性和内存语义,但是添加了类似锁投票、定时锁等候和可中断锁等候的一些特性。此外,它还提供了在激烈争用情况下更佳的性能。(换句话说,当许多线程都想访问共享资源时,JVM 可以花更少的时候来调度线程,把更多时间用在执行线程上。)
- class Outputter1 {
- private Lock lock = new ReentrantLock();// 锁对象
- public void output(String name) {
- lock.lock(); // 得到锁
- try {
- for(int i = 0; i < name.length(); i++) {
- System.out.print(name.charAt(i));
- }
- } finally {
- lock.unlock();// 释放锁
- }
- }
- }
区别:
需要注意的是,用sychronized修饰的方法或者语句块在代码执行完之后锁自动释放,而是用Lock需要我们手动释放锁,所以为了保证锁最终被释放(发生异常情况),要把互斥区放在try内,释放锁放在finally内!!
读写锁ReadWriteLock
上例中展示的是和synchronized相同的功能,那Lock的优势在哪里?
例如一个类对其内部共享数据data提供了get()和set()方法,如果用synchronized,则代码如下:
- class syncData {
- private int data;// 共享数据
- public synchronized void set(int data) {
- System.out.println(Thread.currentThread().getName() + "准备写入数据");
- try {
- Thread.sleep(20);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- this.data = data;
- System.out.println(Thread.currentThread().getName() + "写入" + this.data);
- }
- public synchronized void get() {
- System.out.println(Thread.currentThread().getName() + "准备读取数据");
- try {
- Thread.sleep(20);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println(Thread.currentThread().getName() + "读取" + this.data);
- }
- }
然后写个测试类来用多个线程分别读写这个共享数据:
- public static void main(String[] args) {
- // final Data data = new Data();
- final syncData data = new syncData();
- // final RwLockData data = new RwLockData();
- //写入
- for (int i = 0; i < 3; i++) {
- Thread t = new Thread(new Runnable() {
- @Override
- public void run() {
- for (int j = 0; j < 5; j++) {
- data.set(new Random().nextInt(30));
- }
- }
- });
- t.setName("Thread-W" + i);
- t.start();
- }
- //读取
- for (int i = 0; i < 3; i++) {
- Thread t = new Thread(new Runnable() {
- @Override
- public void run() {
- for (int j = 0; j < 5; j++) {
- data.get();
- }
- }
- });
- t.setName("Thread-R" + i);
- t.start();
- }
- }
运行结果:
- Thread-W0准备写入数据
- Thread-W0写入0
- Thread-W0准备写入数据
- Thread-W0写入1
- Thread-R1准备读取数据
- Thread-R1读取1
- Thread-R1准备读取数据
- Thread-R1读取1
- Thread-R1准备读取数据
- Thread-R1读取1
- Thread-R1准备读取数据
- Thread-R1读取1
- Thread-R1准备读取数据
- Thread-R1读取1
- Thread-R2准备读取数据
- Thread-R2读取1
- Thread-R2准备读取数据
- Thread-R2读取1
- Thread-R2准备读取数据
- Thread-R2读取1
- Thread-R2准备读取数据
- Thread-R2读取1
- Thread-R2准备读取数据
- Thread-R2读取1
- Thread-R0准备读取数据 //R0和R2可以同时读取,不应该互斥!
- Thread-R0读取1
- Thread-R0准备读取数据
- Thread-R0读取1
- Thread-R0准备读取数据
- Thread-R0读取1
- Thread-R0准备读取数据
- Thread-R0读取1
- Thread-R0准备读取数据
- Thread-R0读取1
- Thread-W1准备写入数据
- Thread-W1写入18
- Thread-W1准备写入数据
- Thread-W1写入16
- Thread-W1准备写入数据
- Thread-W1写入19
- Thread-W1准备写入数据
- Thread-W1写入21
- Thread-W1准备写入数据
- Thread-W1写入4
- Thread-W2准备写入数据
- Thread-W2写入10
- Thread-W2准备写入数据
- Thread-W2写入4
- Thread-W2准备写入数据
- Thread-W2写入1
- Thread-W2准备写入数据
- Thread-W2写入14
- Thread-W2准备写入数据
- Thread-W2写入2
- Thread-W0准备写入数据
- Thread-W0写入4
- Thread-W0准备写入数据
- Thread-W0写入20
- Thread-W0准备写入数据
- Thread-W0写入29
现在一切都看起来很好!各个线程互不干扰!等等。。读取线程和写入线程互不干扰是正常的,但是两个读取线程是否需要互不干扰??
对!读取线程不应该互斥!
我们可以用读写锁ReadWriteLock实现:
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
- class Data {
- private int data;// 共享数据
- private ReadWriteLock rwl = new ReentrantReadWriteLock();
- public void set(int data) {
- rwl.writeLock().lock();// 取到写锁
- try {
- System.out.println(Thread.currentThread().getName() + "准备写入数据");
- try {
- Thread.sleep(20);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- this.data = data;
- System.out.println(Thread.currentThread().getName() + "写入" + this.data);
- } finally {
- rwl.writeLock().unlock();// 释放写锁
- }
- }
- public void get() {
- rwl.readLock().lock();// 取到读锁
- try {
- System.out.println(Thread.currentThread().getName() + "准备读取数据");
- try {
- Thread.sleep(20);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println(Thread.currentThread().getName() + "读取" + this.data);
- } finally {
- rwl.readLock().unlock();// 释放读锁
- }
- }
- }
测试结果:
- Thread-W1准备写入数据
- Thread-W1写入9
- Thread-W1准备写入数据
- Thread-W1写入24
- Thread-W1准备写入数据
- Thread-W1写入12
- Thread-W0准备写入数据
- Thread-W0写入22
- Thread-W0准备写入数据
- Thread-W0写入15
- Thread-W0准备写入数据
- Thread-W0写入6
- Thread-W0准备写入数据
- Thread-W0写入13
- Thread-W0准备写入数据
- Thread-W0写入0
- Thread-W2准备写入数据
- Thread-W2写入23
- Thread-W2准备写入数据
- Thread-W2写入24
- Thread-W2准备写入数据
- Thread-W2写入24
- Thread-W2准备写入数据
- Thread-W2写入17
- Thread-W2准备写入数据
- Thread-W2写入11
- Thread-R2准备读取数据
- Thread-R1准备读取数据
- Thread-R0准备读取数据
- Thread-R0读取11
- Thread-R1读取11
- Thread-R2读取11
- Thread-W1准备写入数据
- Thread-W1写入18
- Thread-W1准备写入数据
- Thread-W1写入1
- Thread-R0准备读取数据
- Thread-R2准备读取数据
- Thread-R1准备读取数据
- Thread-R2读取1
- Thread-R2准备读取数据
- Thread-R1读取1
- Thread-R0读取1
- Thread-R1准备读取数据
- Thread-R0准备读取数据
- Thread-R0读取1
- Thread-R2读取1
- Thread-R2准备读取数据
- Thread-R1读取1
- Thread-R0准备读取数据
- Thread-R1准备读取数据
- Thread-R0读取1
- Thread-R2读取1
- Thread-R1读取1
- Thread-R0准备读取数据
- Thread-R1准备读取数据
- Thread-R2准备读取数据
- Thread-R1读取1
- Thread-R2读取1
- Thread-R0读取1
与互斥锁定相比,读-写锁定允许对共享数据进行更高级别的并发访问。虽然一次只有一个线程(writer 线程)可以修改共享数据,但在许多情况下,任何数量的线程可以同时读取共享数据(reader 线程)
从理论上讲,与互斥锁定相比,使用读-写锁定所允许的并发性增强将带来更大的性能提高。
在实践中,只有在多处理器上并且只在访问模式适用于共享数据时,才能完全实现并发性增强。——例如,某个最初用数据填充并且之后不经常对其进行修改的 collection,因为经常对其进行搜索(比如搜索某种目录),所以这样的 collection 是使用读-写锁定的理想候选者。
线程间通信Condition
Condition可以替代传统的线程间通信,用await()替换wait(),用signal()替换notify(),用signalAll()替换notifyAll()。
——为什么方法名不直接叫wait()/notify()/nofityAll()?因为Object的这几个方法是final的,不可重写!
传统线程的通信方式,Condition都可以实现。
注意,Condition是被绑定到Lock上的,要创建一个Lock的Condition必须用newCondition()方法。
Condition的强大之处在于它可以为多个线程间建立不同的Condition
看JDK文档中的一个例子:假定有一个绑定的缓冲区,它支持 put 和 take 方法。如果试图在空的缓冲区上执行take 操作,则在某一个项变得可用之前,线程将一直阻塞;如果试图在满的缓冲区上执行 put 操作,则在有空间变得可用之前,线程将一直阻塞。我们喜欢在单独的等待 set 中保存put 线程和take 线程,这样就可以在缓冲区中的项或空间变得可用时利用最佳规划,一次只通知一个线程。可以使用两个Condition 实例来做到这一点。
——其实就是java.util.concurrent.ArrayBlockingQueue的功能
- class BoundedBuffer {
- final Lock lock = new ReentrantLock(); //锁对象
- final Condition notFull = lock.newCondition(); //写线程锁
- final Condition notEmpty = lock.newCondition(); //读线程锁
- final Object[] items = new Object[100];//缓存队列
- int putptr; //写索引
- int takeptr; //读索引
- int count; //队列中数据数目
- //写
- public void put(Object x) throws InterruptedException {
- lock.lock(); //锁定
- try {
- // 如果队列满,则阻塞<写线程>
- while (count == items.length) {
- notFull.await();
- }
- // 写入队列,并更新写索引
- items[putptr] = x;
- if (++putptr == items.length) putptr = 0;
- ++count;
- // 唤醒<读线程>
- notEmpty.signal();
- } finally {
- lock.unlock();//解除锁定
- }
- }
- //读
- public Object take() throws InterruptedException {
- lock.lock(); //锁定
- try {
- // 如果队列空,则阻塞<读线程>
- while (count == 0) {
- notEmpty.await();
- }
- //读取队列,并更新读索引
- Object x = items[takeptr];
- if (++takeptr == items.length) takeptr = 0;
- --count;
- // 唤醒<写线程>
- notFull.signal();
- return x;
- } finally {
- lock.unlock();//解除锁定
- }
- }
优点:
假设缓存队列中已经存满,那么阻塞的肯定是写线程,唤醒的肯定是读线程,相反,阻塞的肯定是读线程,唤醒的肯定是写线程。
那么假设只有一个Condition会有什么效果呢?缓存队列中已经存满,这个Lock不知道唤醒的是读线程还是写线程了,如果唤醒的是读线程,皆大欢喜,如果唤醒的是写线程,那么线程刚被唤醒,又被阻塞了,这时又去唤醒,这样就浪费了很多时间。
14.同步队列
详见 http://wsmajunfeng.iteye.com/blog/1629354
15.管道
两个线程之间,一个拥有pepedwriter,一个拥有pipedreader(需要writer做参数)。
16.CountDownLatch和CyclicBarrier
CountDownLatch:
被用来同步一个或多个任务,强制他们等待由其他任务执行的一组操作完成。
new CountDownLatch(int size) , 被等待的线程在执行完操作后latch.countdown(),等待的线程调用latch.await(); 计数值为0时结束等待。
CyclicBarrier:
字面意思回环栅栏,通过它可以实现让一组线程等待至某个状态之后再全部同时执行。叫做回环是因为当所有等待线程都被释放以后,CyclicBarrier可以被重用。适用于:创建一组任务,并行执行,然后再下一个步骤之前等待。用于一组或几组线程,比如一组线程需要在一个时间点上达成一致,例如同时开始一个工作。
//当await的数量到达了设定的数量后,首先执行该Runnable对象。
CyclicBarrier(int,Runnable):
//通知barrier已完成线程
await():
- /**
- * 各省数据独立,分库存偖。为了提高计算性能,统计时采用每个省开一个线程先计算单省结果,最后汇总。
- *
- * @author guangbo email:weigbo@163.com
- *
- */
- public class Total {
- // private ConcurrentHashMap result = new ConcurrentHashMap();
- public static void main(String[] args) {
- TotalService totalService = new TotalServiceImpl();
- CyclicBarrier barrier = new CyclicBarrier(5,
- new TotalTask(totalService));
- // 实际系统是查出所有省编码code的列表,然后循环,每个code生成一个线程。
- new BillTask(new BillServiceImpl(), barrier, "北京").start();
- new BillTask(new BillServiceImpl(), barrier, "上海").start();
- new BillTask(new BillServiceImpl(), barrier, "广西").start();
- new BillTask(new BillServiceImpl(), barrier, "四川").start();
- new BillTask(new BillServiceImpl(), barrier, "黑龙江").start();
- }
- }
- /**
- * 主任务:汇总任务
- */
- class TotalTask implements Runnable {
- private TotalService totalService;
- TotalTask(TotalService totalService) {
- this.totalService = totalService;
- }
- public void run() {
- // 读取内存中各省的数据汇总,过程略。
- totalService.count();
- System.out.println("=======================================");
- System.out.println("开始全国汇总");
- }
- }
- /**
- * 子任务:计费任务
- */
- class BillTask extends Thread {
- // 计费服务
- private BillService billService;
- private CyclicBarrier barrier;
- // 代码,按省代码分类,各省数据库独立。
- private String code;
- BillTask(BillService billService, CyclicBarrier barrier, String code) {
- this.billService = billService;
- this.barrier = barrier;
- this.code = code;
- }
- public void run() {
- System.out.println("开始计算--" + code + "省--数据!");
- billService.bill(code);
- // 把bill方法结果存入内存,如ConcurrentHashMap,vector等,代码略
- System.out.println(code + "省已经计算完成,并通知汇总Service!");
- try {
- // 通知barrier已经完成
- barrier.await();
- } catch (InterruptedException e) {
- e.printStackTrace();
- } catch (BrokenBarrierException e) {
- e.printStackTrace();
- }
- }
- }
Semaphore
Semaphore翻译成字面意思为 信号量,Semaphore可以控同时访问的线程个数,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可。
假若一个工厂有5台机器,但是有8个工人,一台机器同时只能被一个工人使用,只有使用完了,其他工人才能继续使用。那么我们就可以通过Semaphore来实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public
class
Test {
public
static
void
main(String[] args) {
int
N =
8
;
//工人数
Semaphore semaphore =
new
Semaphore(
5
);
//机器数目
for
(
int
i=
0
;i<N;i++)
new
Worker(i,semaphore).start();
}
static
class
Worker
extends
Thread{
private
int
num;
private
Semaphore semaphore;
public
Worker(
int
num,Semaphore semaphore){
this
.num = num;
this
.semaphore = semaphore;
}
@Override
public
void
run() {
try
{
semaphore.acquire();
System.out.println(
"工人"
+
this
.num+
"占用一个机器在生产..."
);
Thread.sleep(
2000
);
System.out.println(
"工人"
+
this
.num+
"释放出机器"
);
semaphore.release();
}
catch
(InterruptedException e) {
e.printStackTrace();
}
}
}
}
|
下面对上面说的三个辅助类进行一个总结:
1)CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同:
CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;
而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
另外,CountDownLatch是不能够重用的,而CyclicBarrier是可以重用的。
2)Semaphore其实和锁有点类似,它一般用于控制对某组资源的访问权限。
17.concurrenthashmap(转自http://blog.csdn.net/liuzhengkang/article/details/2916620)
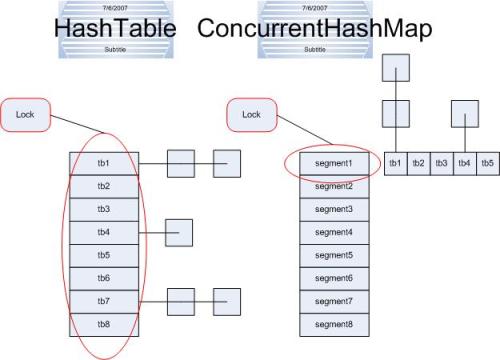
| |
| |
| |
| |
| |















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









