







实例1 读取文件
1 演示说明
在该实例中 Spark Streaming 将监控某目录中的文件,获取在间隔时间段内变化的数据,
然后通过 Spark Streaming 计算出改时间段内单词统计数。
2 演示代码
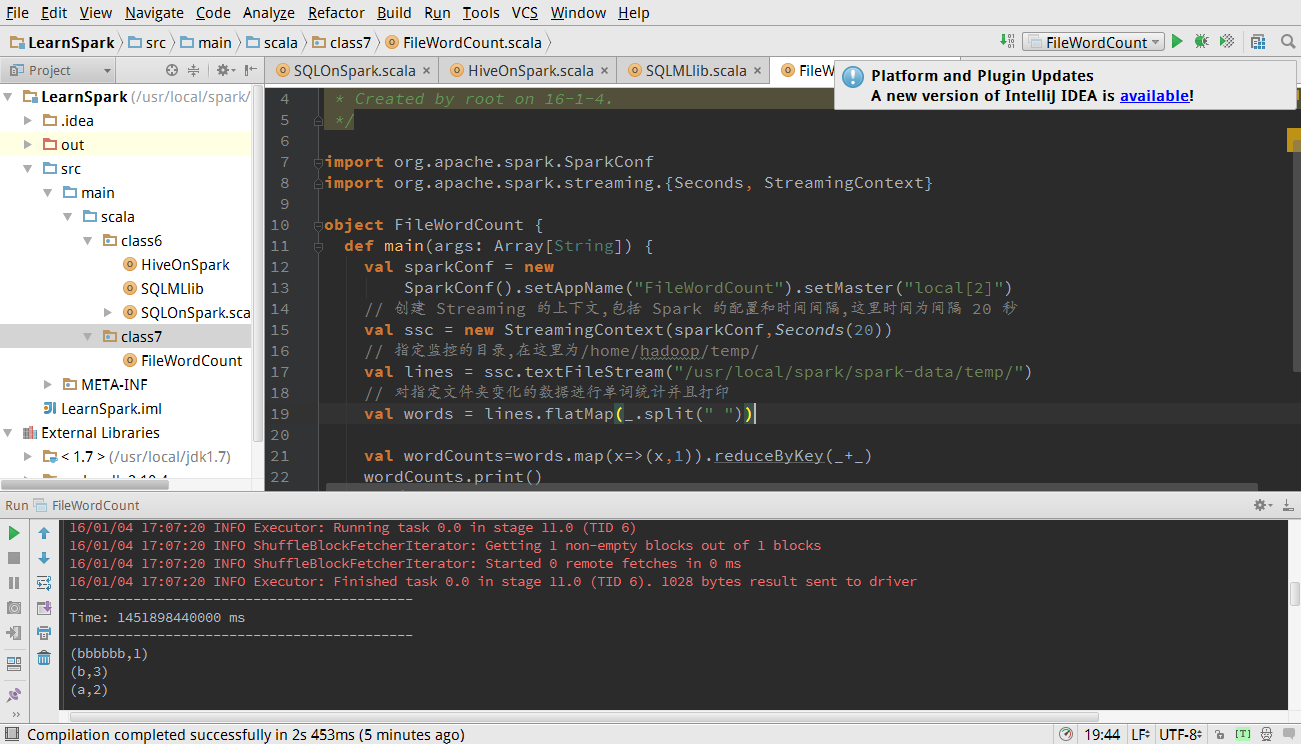
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.StreamingContext._
object FileWordCount {
def main(args: Array[String]) {
val sparkConf = new
SparkConf().setAppName("FileWordCount").setMaster("local[2]")
// 创建 Streaming 的上下文,包括 Spark 的配置和时间间隔,这里时间为间隔 20 秒
val ssc = new StreamingContext(sparkConf, Seconds(20))
// 指定监控的目录,在这里为/home/hadoop/temp/
val lines = ssc.textFileStream("/usr/spark/spark-data/temp/")
// 对指定文件夹变化的数据进行单词统计并且打印
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
// 启动 Streaming
ssc.start()
ssc.awaitTermination()
}
}3 运行代码
第一步创建监控目录,并写入数据
cd /usr/spark/spark-data/temp/
例如
vi test
a a
b bb bbb ....第二步运行程序
















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









