









1 思路
考虑零售户的总销售量,总库存量两个特征,用这两个特征对零售户进行聚类,找出哪些零售户供不应求、哪些零售户供过于求。合理安排配货。
2 数据存准备
在hive中创建两张表,之前已经导入了销售数据,现在创建库存数据
hive -e "
create table hhstore_data(
LICENSE_CODE BIGINT,
ITEM_CODE INT,
QTY_ORD DECIMAL(8,6),
DATE1 INT,
TIME1 varchar(10),
COM_NAME VARCHAR(10)
)row format delimited
fields terminated by ',';"导入库存数据
hive -e "load data local inpath '/usr/local/tobacco_data/红华库存数据002.csv
' overwrite into table hhstore_data;"这里顺便测试了一下hive的查询速度:
查出每个零售户的总库存和总销量
select COM_NAME, sum(a.QTY_ORD) store_qty, sum(b.QTY_ORD) sale_qty from hhstore_data a left join hhsale_data b on a.COM_NAME=b.COM_NAME group by a.COM_NAME limit 10;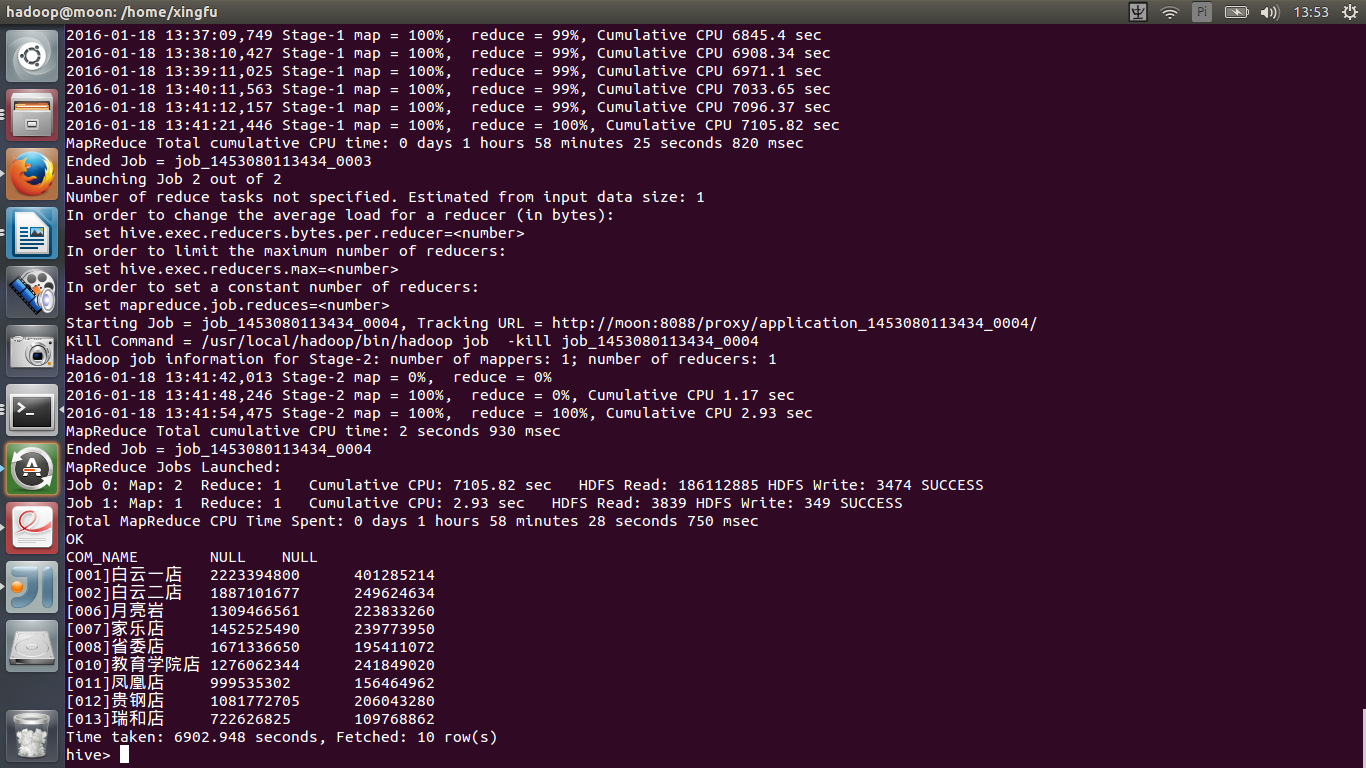
好啊!这家伙竟然花了7105s 近两个小时!无法忍受
使用hive on spark试试:
package class6
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by root on 16-1-4.
* Spark+Hive整合
我们知道,在使用Hive进行查询的时候,到底层MapReduce计算层会将HiveQL翻译成MapReduce程序,
在Hadoop平台上执行计算,这使得计算的延迟比较大。我们整合Spark和Hive,就是通过Spark平台来计算Hive查询,
也就是Hive不再使用它默认的MapReduce计算引擎,Spark会直接读取Hive的元数据存储,
将Hive数据转换成Spark RDD数据,通过Spark提供的计算操作来实现(Transformation和Action)。
实验结果:下面那个查询hive用了7105s而hiveonspark只用了178s快了39.9倍
*/
object HiveOnSpark {
case class Record(key:Int,value:String)
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("HiveOnSpark")
val sc = new SparkContext(sparkConf)
val HiveContext = new HiveContext(sc)
import HiveContext._
// sql("use hive")
// sql("select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tbStock a " +
// "join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on " +
// "a.dateid=c.dateid group by c.theyear order by c.theyear")
// .collect().foreach(println)
sql("select a.COM_NAME, sum(a.QTY_ORD) store_qty, sum(b.QTY_ORD) sale_qty from hhstore_data a left join hhsale_data b " +
"on a.COM_NAME=b.COM_NAME group by a.COM_NAME limit 10")
.collect().foreach(println)
sc.stop()
}
}
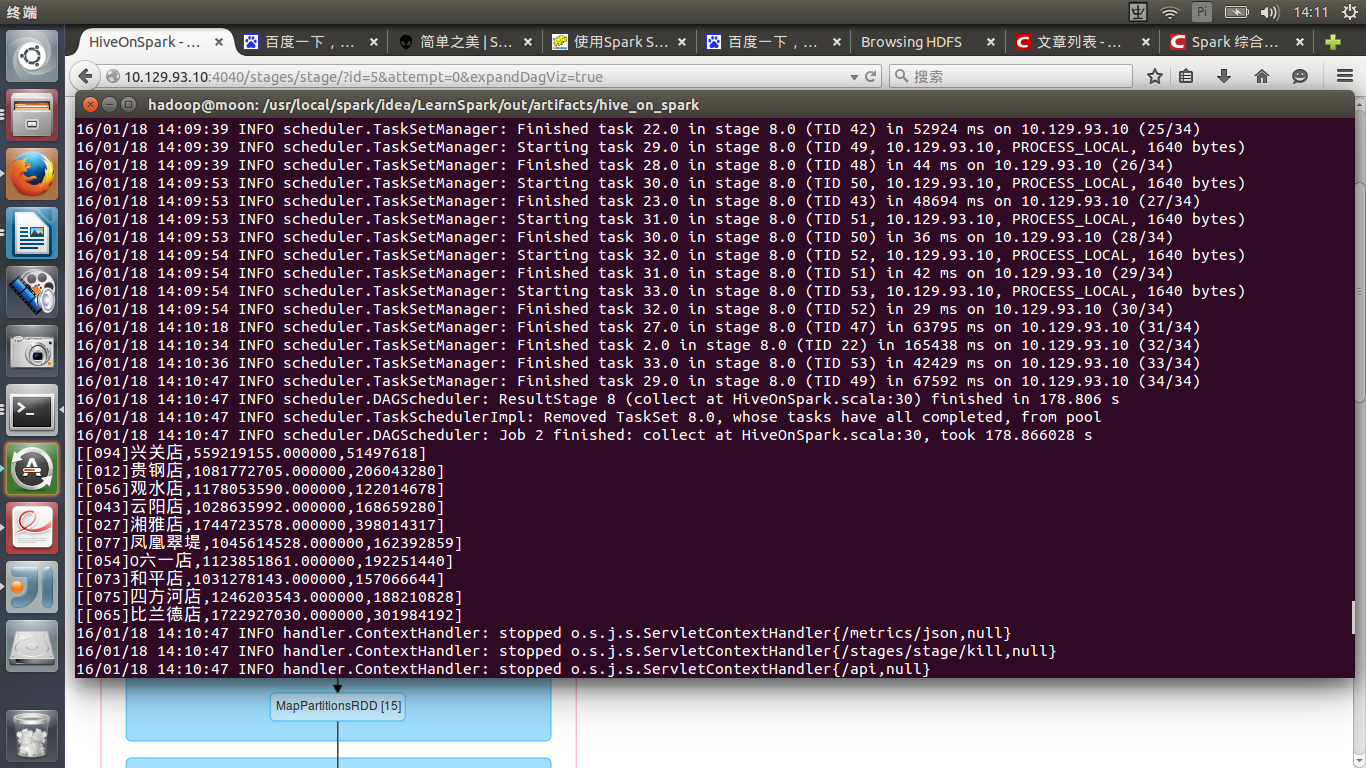
嗯、花了178s,毕竟查询逻辑在那。快了近40倍。
3进行kmeans聚类
package class6
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.Row
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by root on 16-1-18.
*/
object tobacco_in_out_km {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("tobacco_in_out_km")
val sc = new SparkContext(sparkConf)
val HiveContext = new HiveContext(sc)
import HiveContext._
val sqldata = sql("select a.COM_NAME, sum(a.QTY_ORD) store_qty, sum(b.QTY_ORD) sale_qty from hhstore_data a left join hhsale_data b " +
"on a.COM_NAME=b.COM_NAME group by a.COM_NAME")
//将查询数据转换成向量
val parsedData = sqldata.map{
case Row(_,store_qty,sale_qty)=>
val features = Array[Double](store_qty.toString.toDouble,
sale_qty.toString.toDouble)
Vectors.dense(features)
}.cache()//注意使用cache提高效率。
//对数据集聚类,3 个类,20 次迭代,形成数据模型
//注意这里会使用设置的 partition 数 20
val numClusters = 3
val numIterations = 20
val model = KMeans.train(parsedData,numClusters,numIterations)
//打印数据模型的中心点
println("---------------------------------------------------------------" +
"Cluster centers:" +
"---------------------------------------------------------------------")
for(c <-model.clusterCenters){
println(" "+c.toString)
}
//使用误差平方之和来评估数据模型,--------------------------------------模型在训练集上计算损失
val cost=model.computeCost(parsedData)
println("--------------------------------------------------------------------" +
"Within Set Sum of Squared Errors=-----------------------------------------"+cost)
用模型对读入的数据进行分类,并输出
//由于 partition 没设置,输出为 200 个小文件,可以使用 bin/hdfs dfs -getmerge 合并
//下载到本地
val result2 = sqldata.map{
case Row(com_name,store_qty,sale_qty)=>
val features =Array[Double](store_qty.toString.toDouble,
sale_qty.toString.toDouble)
val linevectore = Vectors.dense(features)
val prediction = model.predict(linevectore)
com_name+" "+store_qty+" "+sale_qty+" "+prediction
}.saveAsTextFile(args(0))
}
}
4提交任务
启动hive服务
$nohup hive --service metastore > metastore.log 2>&1 &spark-submit --master spark://moon:7077 --class class6.tobacco_in_out_km --executor-memory 2g --total-executor-cores 4 tobacco_in_out.jar /class6/tobacco_in_out_km1
spark-submit --master spark://moon:7077 --class class6.tobacco_in_out_km --executor-memory 2g --total-executor-cores 4 tobacco_in_out.jar /class6/tobacco_in_out_km_chach > /usr/local/spark/tobacco_km.log
程序在一台笔记本上跑了7个多小时。
对数据进行cache后只用了1个小时!
输出的评估内容:
1 ---------------------------------------------------------------Cluster centers:------------------------------------------------------------- --------
2 [1.1661534191111112E9,1.9860203797777778E8]
3 [2.0781018788888888E9,3.346425471111111E8]
4 [5.471160729130435E8,9.399341230434783E7]
5 --------------------------------------------------------------------Within Set Sum of Squared Errors=--------------------------------------- --7.5440041898105969E18
5获取结果
hdfs dfs -getmerge /class6/tobacco_in_out_km1 /usr/local/spark/tobacco_in_out_km_result.txt聚类结果如下(部分,嘿嘿):
[094]兴关店 559219155.000000 51497618 0
[012]贵钢店 1081772705.000000 206043280 0
[056]观水店 1178053590.000000 122014678 1
[043]云阳店 1028635992.000000 168659280 0
[027]湘雅店 1744723578.000000 398014317 1
[077]凤凰翠堤 1045614528.000000 162392859 0
[054]O六一店 1123851861.000000 192251440 0
[073]和平店 1031278143.000000 157066644 06优化部分
1 去除脏数据
数据的第一条是字段名,值为null,不去掉的话会影响结果
val sqldata = sql("select a.COM_NAME, sum(a.QTY_ORD) store_qty, sum(b.QTY_ORD) sale_qty from (select * from hhstore_data where item_code is not null)a left join " +
"hhsale_data b on a.COM_NAME=b.COM_NAME group by a.COM_NAME")2 聚类数K选取
用程序选择K
computeCost 方法,该方法通过计算所有数据点到其最近的中心点的平方和来评估聚类的效果。一般来说,
同样的迭代次数和算法跑的次数,这个值越小代表聚类的效果越好。
但是在实际情况下,我们还要考虑到聚类结果的可解释性,不能一味的选择使 computeCost 结果值最小的那个 K
package class6
import org.apache.spark.mllib.clustering.{KMeansModel, KMeans}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.Row
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by root on 16-1-18.
*/
object tobacco_in_out_km {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("tobacco_in_out_km")
val sc = new SparkContext(sparkConf)
val HiveContext = new HiveContext(sc)
import HiveContext._
val sqldata = sql("select a.COM_NAME, sum(a.QTY_ORD) store_qty, sum(b.QTY_ORD) sale_qty from (select * from hhstore_data where item_code is not null)a left join " +
"hhsale_data b on a.COM_NAME=b.COM_NAME group by a.COM_NAME")
//将查询数据转换成向量
val parsedData = sqldata.map{
case Row(_,store_qty,sale_qty)=>
val features = Array[Double](store_qty.toString.toDouble,
sale_qty.toString.toDouble)
Vectors.dense(features)
}.cache()
val ks:Array[Int] = Array(3,4,5,6,7,8,9)
ks.foreach(cluster => {
val model:KMeansModel = KMeans.train(parsedData, cluster,20,1)
val ssd = model.computeCost(parsedData)
println("sum of squared distances of points to their nearest center when k=" + cluster + " -> "+ ssd)
})
//需要重复使用的模型可以保存下来的。。。。
// //对数据集聚类,3 个类,20 次迭代,形成数据模型
// //注意这里会使用设置的 partition 数 20
// val numClusters = 3
// val numIterations = 20
// val model = KMeans.train(parsedData,numClusters,numIterations)
// //打印数据模型的中心点
// println("---------------------------------------------------------------" +
// "Cluster centers:" +
// "---------------------------------------------------------------------")
// for(c <-model.clusterCenters){
// println(" "+c.toString)
// }
//
// //使用误差平方之和来评估数据模型,--------------------------------------模型在训练集上计算损失
//
// val cost=model.computeCost(parsedData)
// println("--------------------------------------------------------------------" +
// "Within Set Sum of Squared Errors=-----------------------------------------"+cost)
// 用模型对读入的数据进行分类,并输出
// //由于 partition 没设置,输出为 200 个小文件,可以使用 bin/hdfs dfs -getmerge 合并
// //下载到本地
// val result2 = sqldata.map{
// case Row(com_name,store_qty,sale_qty)=>
// val features =Array[Double](store_qty.toString.toDouble,
// sale_qty.toString.toDouble)
// val linevectore = Vectors.dense(features)
// val prediction = model.predict(linevectore)
// com_name+" "+store_qty+" "+sale_qty+" "+prediction
// }.saveAsTextFile(args(0))
}
}
3 使用5G内存运行程序
hadoop@moon:/usr/local/spark/idea/LearnSpark/out/artifacts/tobacco_in_out$ spark-submit --master spark://moon:7077 --class class6.tobacco_in_out_km --executor-memory 5g --total-executor-cores 4 tobacco_in_out.jar >/usr/local/spark/tobacco_in_out_km_result3456789.txt
运行完毕用时26分钟,注意这里其实运行了7次KMeans算法
4 输出评估不同k的结果
1 sum of squared distances of points to their nearest center when k=3 -> 6.4890327862785249E18
2 sum of squared distances of points to their nearest center when k=4 -> 3.209487674100267E18
3 sum of squared distances of points to their nearest center when k=5 -> 2.1814111396728471E18
4 sum of squared distances of points to their nearest center when k=6 -> 1.30515483214681062E18
5 sum of squared distances of points to their nearest center when k=7 -> 1.18605067864590848E18
6 sum of squared distances of points to their nearest center when k=8 -> 7.1604954233549261E17
7 sum of squared distances of points to their nearest center when k=9 -> 6.0889529116193229E17
看来K=4是最合理的
package class6
import org.apache.spark.mllib.clustering.{KMeansModel, KMeans}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.Row
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by root on 16-1-18.
*/
object tobacco_in_out_km {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("tobacco_in_out_km")
val sc = new SparkContext(sparkConf)
val HiveContext = new HiveContext(sc)
import HiveContext._
val sqldata = sql("select a.COM_NAME, sum(a.QTY_ORD) store_qty, sum(b.QTY_ORD) sale_qty from (select * from hhstore_data where item_code is not null)a left join " +
"hhsale_data b on a.COM_NAME=b.COM_NAME group by a.COM_NAME")
//将查询数据转换成向量
val parsedData = sqldata.map{
case Row(_,store_qty,sale_qty)=>
val features = Array[Double](store_qty.toString.toDouble,
sale_qty.toString.toDouble)
Vectors.dense(features)
}.cache()
// val ks:Array[Int] = Array(3,4,5,6,7,8,9)
// ks.foreach(cluster => {
// val model:KMeansModel = KMeans.train(parsedData, cluster,20,1)
// val ssd = model.computeCost(parsedData)
// println("sum of squared distances of points to their nearest center when k=" + cluster + " -> "+ ssd)
// })
//需要重复使用的模型可以保存下来的。。。。
//对数据集聚类,3 个类,20 次迭代,形成数据模型
//注意这里会使用设置的 partition 数 20
val numClusters = 4
val numIterations = 20
val model = KMeans.train(parsedData,numClusters,numIterations)
//打印数据模型的中心点
println("---------------------------------------------------------------" +
"Cluster centers:" +
"---------------------------------------------------------------------")
for(c <-model.clusterCenters){
println(" "+c.toString)
}
//使用误差平方之和来评估数据模型,--------------------------------------模型在训练集上计算损失
val cost=model.computeCost(parsedData)
println("--------------------------------------------------------------------" +
"Within Set Sum of Squared Errors=-----------------------------------------"+cost)
用模型对读入的数据进行分类,并输出
//由于 partition 没设置,输出为 200 个小文件,可以使用 bin/hdfs dfs -getmerge 合并
//下载到本地
val result2 = sqldata.map{
case Row(com_name,store_qty,sale_qty)=>
val features =Array[Double](store_qty.toString.toDouble,
sale_qty.toString.toDouble)
val linevectore = Vectors.dense(features)
val prediction = model.predict(linevectore)
com_name+" "+store_qty+" "+sale_qty+" "+prediction
}.saveAsTextFile(args(0))
}
}
提交任务
hadoop@moon:/usr/local/spark/idea/LearnSpark/out/artifacts/tobacco_in_out$ spark-submit --master spark://moon:7077 --class class6.tobacco_in_out_km --executor-memory 5g --total-executor-cores 4 tobacco_in_out.jar /class6/tobacco_in_out_4--------------------------------------------------------------------Within Set Sum of Squared Errors=-----------------------------------------3.2094876741002665E18
获取结果
hdfs dfs -getmerge /class6/tobacco_in_out_4 /usr/local/spark/tobacco_in_out_4_result.txt 1 [094]兴关店 559219155.000000 51497618 0
2 [012]贵钢店 1081772705.000000 206043280 2
3 [056]观水店 1178053590.000000 122014678 2
4 [043]云阳店 1028635992.000000 168659280 2
5 [027]湘雅店 1744723578.000000 398014317 1
6 [077]凤凰翠堤 1045614528.000000 162392859 2
7 [054]O六一店 1123851861.000000 192251440 2
.....7修改
销售量跟库存量没有直接关系,销售量会小于进货量。
把库存为负的数据过滤掉
package class6
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.stat.Statistics
import org.apache.spark.sql.Row
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by root on 16-1-22.
* 零售户按年库存量、销售量进行聚类
* 两表join出现了数据重叠,考虑每次读一张表,利用RDD的join方法
* 得到特征矩阵。。。
*--------------------------------------------------------------------Within Set Sum of Squared Errors=-----------------------------------------2.6105260195375473E10
*
*/
object tobacco_kmeans {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("tobacco_kmeans")//.setMaster("local[4]")
val sc = new SparkContext(sparkConf)
val HiveContext = new HiveContext(sc)
import HiveContext._
/*
销售数据
*/
val saledata = sql("select com_name ,sum(qty_ord) sale_qty from hhsale_data where puh_time is " +
"not null group by com_name")
/*
库存数据
*/
val storedata = sql("select com_name ,sum(qty_ord) store_qty from hhstore_data where item_code is not " +
"null and qty_ord >0 group by com_name")
val data=saledata.join(storedata,"com_name")
val parsedData = data.map{
case Row(_, sale_qty, store_qty) =>
val features = Array[Double](sale_qty.toString.toDouble,
store_qty.toString.toDouble)
Vectors.dense(features)
}.cache()//.saveAsTextFile("/class6/data")
/*
标准化
*/
// val summary = Statistics.colStats(parsedData)
// parsedData.map{
// case Row(_,sale,store) =>
//
// }
// val dataAsArray = parsedData.map(_.toArray)
//val numCols = dataAsArray.first().length
//val n = dataAsArray.count()
//val sums = dataAsArray.reduce(
//(a,b) => a.zip(b).map(t => t._1 + t._2))
//val sumSquares = dataAsArray.fold(
//new Array[Double](numCols)
//)(
//(a,b) => a.zip(b).map(t => t._1 + t._2 * t._2)
//)
//val stdevs = sumSquares.zip(sums).map {
//case(sumSq,sum) => math.sqrt(n*sumSq - sum*sum)/n
//}
//val means = sums.map(_ / n)
// def normalize(datum: Vector) = {
//val normalizedArray = (datum.toArray, means, stdevs).zipped.map(
//(value, mean, stdev) =>
//if (stdev <= 0) (value - mean) else (value - mean) / stdev
//)
//Vectors.dense(normalizedArray)
//}
val numClusters = 3
val numIterations = 20
val model = KMeans.train(parsedData,numClusters,numIterations)
//打印数据模型的中心点
println("---------------------------------------------------------------" +
"Cluster centers:" +
"---------------------------------------------------------------------")
for(c <-model.clusterCenters){
println(" "+c.toString)
}
//使用误差平方之和来评估数据模型,--------------------------------------模型在训练集上计算损失
val cost=model.computeCost(parsedData)
println("--------------------------------------------------------------------" +
"Within Set Sum of Squared Errors=-----------------------------------------"+cost)
用模型对读入的数据进行分类,并输出
//由于 partition 没设置,输出为 200 个小文件,可以使用 bin/hdfs dfs -getmerge 合并
//下载到本地
val result = data.map{
case Row(com_name, sale_qty, store_qty) =>
val features = Array[Double](sale_qty.toString.toDouble,
store_qty.toString.toDouble)
val linevectore = Vectors.dense(features)
val prediction = model.predict(linevectore)
com_name+" "+sale_qty+" "+store_qty+" "+prediction+"\n"
}.saveAsTextFile(args(0))
// val result2 = sqldata.map{
// case Row(com_name,store_qty,sale_qty)=>
// val features =Array[Double](store_qty.toString.toDouble,
// sale_qty.toString.toDouble)
// val linevectore = Vectors.dense(features)
// val prediction = model.predict(linevectore)
// com_name+" "+store_qty+" "+sale_qty+" "+prediction
// }.saveAsTextFile(args(0))
System.out.println("-----------------------------")
sc.stop()
}
}
提交
hadoop@moon:/usr/local/spark/idea/LearnSpark/out/artifacts/tobacco_kmeans$ spark-submit --master spark://moon:7077 --class class6.tobacco_kmeans --executor-memory 3g --total-executor-cores 4 tobacco_kmeans.jar /class6/tobacco_kmeans_new
-------------------------------------------------------------------Within Set Sum of Squared Errors=-----------------------------------------2.9486673754847862E10
获取结果
hdfs dfs -getmerge /class6/tobacco_kmeans_new /usr/local/spark/tobacco_kmeans_new.txtSpark 实战,第 4 部分: 使用 Spark MLlib 做 K-means 聚类分析
Spark 实战,第 5 部分: 使用 ML Pipeline 构建机器学习工作流















 1273
1273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









