










word2vec
为什么要进行embedding
word2vec就是对word进行embedding
首先,我们知道,在机器学习和深度学习中,对word的最简单的表示就是使用one-hot([0,0,1,0,0…..]来表示一个word). 但是用one-hot表示一个word的话,会有一些弊端:从向量中无法看出word之间的关系(
(wworda)Twwordb=0
),而且向量也太稀疏. 所以一些人就想着能否用更小的向量来表示一个word,希望这些向量能够承载一些语法和语义上的信息, 这就产生了word2vec
Language Model(Unigrams, Bigrams, Trigrams..etc)
language model 对序列的概率建模
Unigram:
假设句子中,各个word是独立的
P(w1,w2,w3..,wn)=∏ni=1P(wi)
Bigram
假设句子中,每个word只和之前的一个word有关系
P(w1,w2,w3..,wn)=∏ni=2P(wi|wi−1)
Trigram
假设句子中,每个word和前两个word有关系
P(w1,w2,w3..,wn)=∏ni=1P(wi|wi−1,wi−2)
上面的模型都基于很强的假设,而实际上,句子中的每个word,是和整个句子有关系的,不仅仅只是考虑前一个或前两个
Continuous Bags of Words Model (CBOW)
这个模型是上面几种模型的扩展.CBOW不是简单的只考虑前一个词或前两个词,它是考虑了单词的上下文(context).在CBOW,我们的目标是
maxP(w|context(w))
.
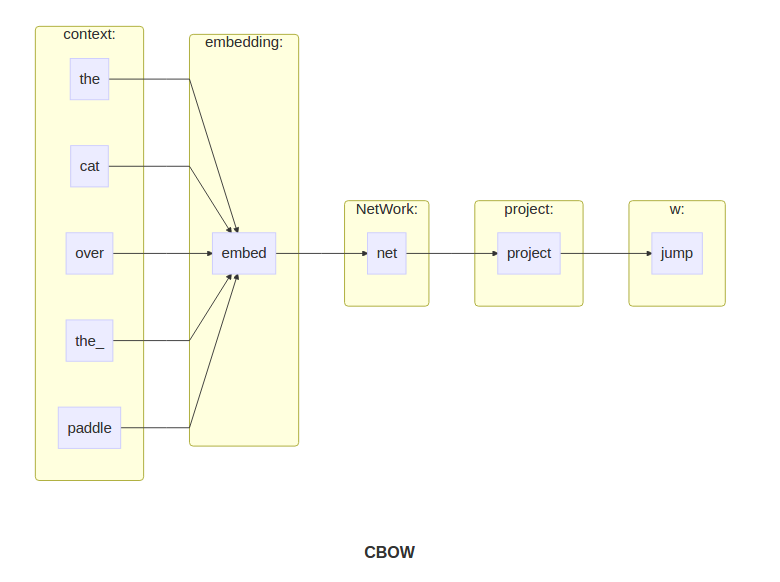
首先,模型的输入(context)是one-hot’s ,模型的输出(w)是one-hot,
one_hot∈R|V|
,这个是已知的.我们要创建两个矩阵
E=Matrix(embedding)∈R|V|∗embedding_size
,
P=Matrix(projection)∈Rembedding_size∗|V|
, 这两个矩阵是需要训练的.
|V|
是字典的大小,
embedding_size
是任意值(代表你想把onehot压缩成几维表示).
模型运作步骤:
(1) 生成
context的
one-hot矩阵
(2) 计算出
context的
embedding matrix,
context∗E∈Rcontext(w)∗|V|
(3) 将获取的
matrix平均,
v̂ =reducemean(context∗E,1)
(4) 生成评分向量 z=reduce_mean(context∗E,1)∗P∈R|V|
(5) 将评分向量转成概率分布 ŷ =softmax(z)
ŷ 的分布和实际分布 y 越相近,则模型学习的越好, 如何描述两个分布的相似性呢?借用信息论中的交叉熵
m:窗口大小
skip-gram Model
skip-gram model和CBOW结构相反, CBOW输入上下文, 输出中间的word.skip-gram输入中间的word,输出上下文.
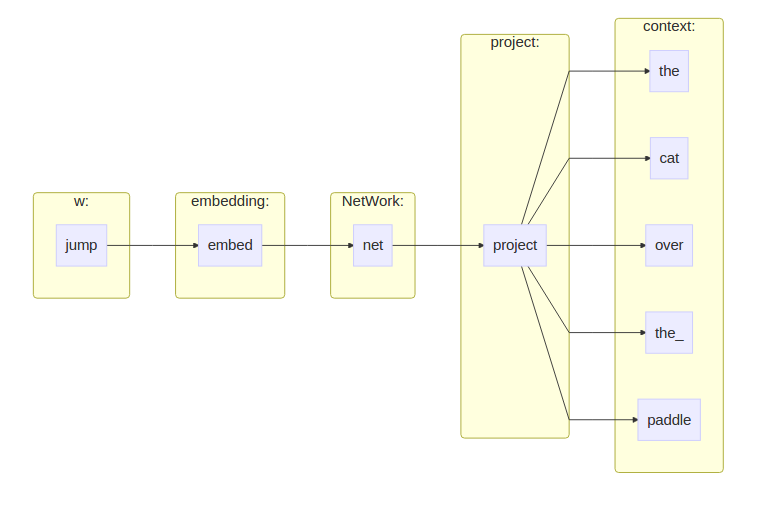
需要学习的依旧是两个矩阵,
Embed∈R|V|∗embedding_size
和
Proj∈Rembedding_size∗|V|
Negtive Sampling
看公式
∑|V|i=1projiv̂ T
,如果
|V|
很大,那么运算量是相当大的,为了减少运算量,就提出了Negtive Sampling.
Negtive Sampling基于skip-gram model.
考虑一个(w,c)对,其中w是中心单词,c为w上下文中的一个单词,
P(D=1|w,c,θ)
表示c是w上下文中单词的概率,
P(D=0|w,c,θ)
表示c不是w上下文中单词的概率.我们先对
P(D=1|w,c,θ)
进行建模:
相比
CBOW和
skip-gram,
Negtive Sampling思想是,如果
c是
w的上下文中的单词,就最大
P(D=1|w,c,θ)
,如果不是,就最大化
P(D=0|w,c,θ)
,
θ
就是
Embed,Proj
这样运算量就被减小了.
x训练之后,对 Embed 和 Proj 有多种处理方式:
(1) 求和
(2)平均
(3)连接起来
问题:
(1):
Negtive Sampling只考虑了上下文关系,没有考虑单词之间的顺序关系,如果考虑进去的话,效果会不会更好?
(2):
word2vec,优化的都是
proj_c和
embed_w的距离,让这两个向量尽量的近,这个代表了什么?
(3):对于 Embed ,感觉更新的频率不够















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









