







上节课我们一起学习了用Java来对HBase的表进行增、删、改、查操作。这节课我们开始步入Hive的学习阶段
我们先来看一下Hive的简介,如下图所示,Hive是一个数据仓库,它部署在Hadoop集群上,它的数据是存储在HDFS上的,Hive所建的表在HDFS上对应的是一个文件夹,表的内容对应的是一个文件。它不仅可以存储大量的数据而且可以对存储的数据进行分析,但它有个缺点就是不能实时的更新数据,无法直接修改和删除数据,如果想要修改数据需要先把数据所在的文件下载下来,修改完之后再上传上去。Hive的语法非常类似于我们的MySQL语句,所以上起手来特别容易。HIve特别神奇的地方是我们只需写一条SQL语句它就会自动转换为MapReduce任务去执行,不用我们再手动去写MapReduce了。

图一 Hive简介

图二 Hive简介
接下来我们一起来看一下Hive的系统架构图,如下图所示,这张图还是比较老的图,不过还是可以拿来学习的,我们看到Hive的最上方是CLI、JDBC/ODBC、WebUI。CLI的意思是Command Line Interface(命令行接口),这意味着我们可以通过三种方式来操作我们的Hive,我们发送命令用CLI,尽量不要使用JDBC/ODBC因为事实证明它是有很多问题的,我们可以通过Web来浏览我们的Hive表及数据。元数据我们一般存储在mysql当中(Hive默认的数据库是derby),元数据是指表的信息,比如表的名字,表有哪些列等等描述信息。并不是我们要计算的数据。我们向表中插入的数据是保存在HDFS上的。
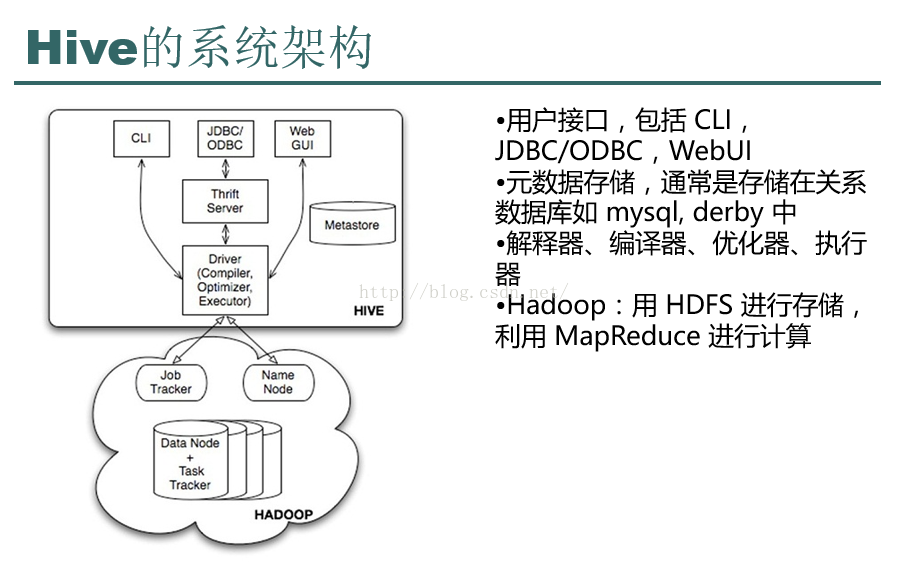
图三 Hive架构图

图四 Hive系统架构说明。
上面说了些理论,接下来我们一起来真正操作一下我们的Hive。当然在操作之前请确保您的Hadoop集群是正常的。如果还没有搭建好集群请参考:http://blog.csdn.net/u012453843/article/details/52829830这篇博客进行搭建。
首先我们需要下载Hive的安装包,我们使用以前的版本apache-hive-0.13.0-bin.tar.gz,因为我发现最新的版本放在我们的hadoop-2.2.0版本上执行会有问题。我们可以从http://download.csdn.net/detail/u012453843/9673736这个网址下载0.13.0版本的开发包。
下载完开发包之后上传到itcast01上,然后把它解压到/itcast/目录下。
[root@itcast01 ~]# ls
anaconda-ks.cfg apache-maven-3.3.9-bin.tar.gz Documents glibc-2.14 hadoop-2.2.0-src hbase-0.96.2-hadoop2-bin.tar.gz install.log.syslog Music Public Videos apache-hive-0.13.0-bin.tar.gz Desktop Downloads glibc-2.14.tar.gz hadoop-2.2.0.tar.gz install.log jdk-7u80-linux-x64.gz Pictures Templates
[root@itcast01 ~]# tar -zxvf apache-hive-0.13.0-bin.tar.gz -C /itcast/
解压完之后我们到/itcast/目录下查看一下hive包,在它的bin目录下是一些可执行的脚本。如下所示。
[root@itcast01 ~]# cd /itcast/
[root@itcast01 itcast]# ls
apache-hive-0.13.0-bin hadoop-2.2.0 hbase-0.96.2-hadoop2
[root@itcast01 itcast]# cd apache-hive-0.13.0-bin/
[root@itcast01 apache-hive-0.13.0-bin]# ls
bin conf examples hcatalog lib LICENSE NOTICE README.txt RELEASE_NOTES.txt scripts
[root@itcast01 apache-hive-0.13.0-bin]# cd bin
我们来查看一下bin目录下的脚本有哪些,发现hive脚本当前所属组是502,所属用户是games,我们把它修改一下。
[root@itcast01 bin]# ls -ls
total 40
4 -rwxr-xr-x. 1 502 games 881 Mar 5 2014 beeline
4 -rw-r--r--. 1 root root 690 Nov 5 13:29 derby.log
4 drwxr-xr-x. 3 root root 4096 Nov 5 13:28 ext
8 -rwxr-xr-x. 1 502 games 7164 Mar 13 2014 hive
4 -rwxr-xr-x. 1 502 games 1900 Mar 5 2014 hive-config.sh
4 -rwxr-xr-x. 1 502 games 885 Mar 5 2014 hiveserver2
4 drwxr-xr-x. 5 root root 4096 Nov 5 13:29 metastore_db
4 -rwxr-xr-x. 1 502 games 832 Mar 5 2014 metatool
4 -rwxr-xr-x. 1 502 games 884 Mar 5 2014 schematool
[root@itcast01 bin]# cd /itcast/
[root@itcast01 itcast]# ls
apache-hive-0.13.0-bin hadoop-2.2.0 hbase-0.96.2-hadoop2
使用chown -R root:root apache-hive-0.13.0-bin/来改变用户组和所属用户都改成root,改完之后再查看一下。
[root@itcast01 itcast]# chown -R root:root apache-hive-0.13.0-bin/
[root@itcast01 itcast]# cd apache-hive-0.13.0-bin/
[root@itcast01 apache-hive-0.13.0-bin]# ls -ls
total 304
4 drwxr-xr-x. 4 root root 4096 Nov 5 13:29 bin
4 drwxr-xr-x. 2 root root 4096 Nov 5 13:28 conf
4 drwxr-xr-x. 4 root root 4096 Nov 5 13:28 examples
4 drwxr-xr-x. 7 root root 4096 Nov 5 13:28 hcatalog
4 drwxr-xr-x. 4 root root 4096 Nov 5 13:28 lib
24 -rw-r--r--. 1 root root 23828 Mar 5 2014 LICENSE
4 -rw-r--r--. 1 root root 277 Mar 5 2014 NOTICE
4 -rw-r--r--. 1 root root 3838 Mar 5 2014 README.txt
248 -rw-r--r--. 1 root root 251948 Apr 16 2014 RELEASE_NOTES.txt
4 drwxr-xr-x. 3 root root 4096 Nov 5 13:28 scripts
conf目录下是它的配置文件。
[root@itcast01 apache-hive-0.13.0-bin]#
[root@itcast01 bin]# cd ..
[root@itcast01 apache-hive-0.13.0-bin]# cd conf
[root@itcast01 conf]# ls
hive-default.xml.template hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template
[root@itcast01 conf]#
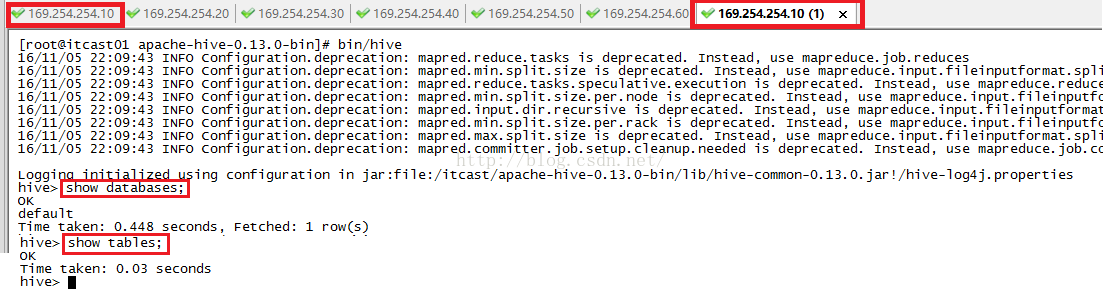
我们不用对配置做任何修改便可以使用Hive的功能,我们先到bin目录下,然后使用./hive命令启动我们的hive,然后我们可以使用命令show tables查看当前都有哪些表,使用show databases查看都有哪些数据库,如下所示。我们在关系型数据库中如果想查看有哪些表必须先指定用哪个数据库,但是我们的Hive就不用,它会默认使用default数据库。
[root@itcast01 bin]# ls
beeline ext hive hive-config.sh hiveserver2 metatool schematool
[root@itcast01 bin]# ./hive
16/11/05 13:29:16 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/05 13:29:16 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/05 13:29:16 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/05 13:29:16 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/05 13:29:16 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/05 13:29:16 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/05 13:29:16 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/05 13:29:16 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Logging initialized using configuration in jar:file:/itcast/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
hive> show tables;
OK
Time taken: 0.608 seconds
hive> show databases;
OK
default
Time taken: 0.017 seconds, Fetched: 1 row(s)
hive>
接下来我们就创建一张student表,有两列,分别是id和name,如下所示,创建完表之后我们查看一下当前都有哪些表,发现有我们刚才创建的表student。
hive> create table student(id int,name string);
OK
Time taken: 0.84 seconds
hive> show tables;
OK
student
Time taken: 0.069 seconds, Fetched: 1 row(s)
hive>
我们还可以查看创建表的信息,如下所示,可以看到有建表语句,有student表存储的位置'hdfs://ns1/user/hive/warehouse/student'。
hive> show create table student;
OK
CREATE TABLE `student`(
`id` int,
`name` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://ns1/user/hive/warehouse/student'
TBLPROPERTIES (
'transient_lastDdlTime'='1478326020')
Time taken: 0.799 seconds, Fetched: 13 row(s)
hive>
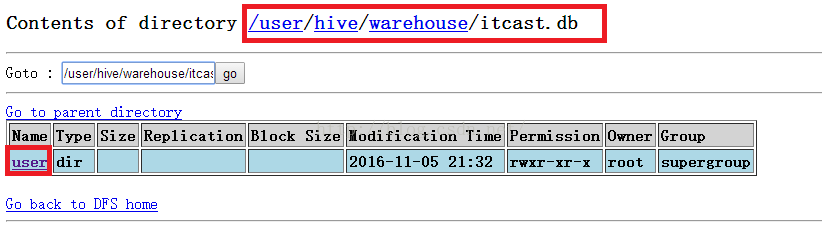
既然student表是存储在hdfs上的,那么我们便到hdfs系统去查看一下,我们HDFS根目录下点击user--->点击hive---->点击warehouse就会看到如下图所示的界面,可以看到这里确实有我们刚才创建的表,它是一个文件夹,我们以后向student表插入数据就是把一个文件放到student目录下。

接下来我们便创建一个student.txt文件并在里面添加几条数据,创建student.txt直接使用命令vim student.txt便可以,然后在里面输入三行内容,然后保存退出。
[root@itcast01 ~]# vim student.txt
1 zhangsan
2 lisi
3 wangwu
接着我们把student.txt文件上传到HDFS系统student目录下,如下所示。
hive> load data local inpath '/root/student.txt' into table student;
Copying data from file:/root/student.txt
Copying file: file:/root/student.txt
Loading data to table default.student
Table default.student stats: [numFiles=1, numRows=0, totalSize=33, rawDataSize=0]
OK
Time taken: 1.796 seconds
hive>
操作完毕之后我们到HDFS文件系统查看一下,如下图所示,发现已经有student.txt文件并且文件中的内容与我们输入的内容一致。
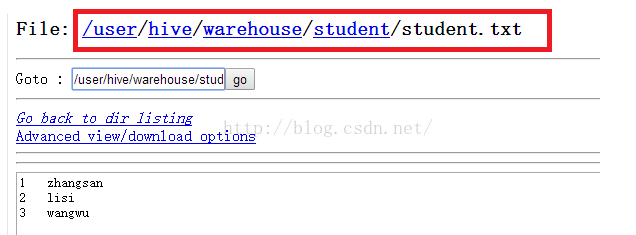
我们从hive视图查询一下student表的内容,如下所示。发现查询出来的内容都是NULL,这是因为我们创建表的时候没有指定列与列之间是以什么分割的。有两列NULL是因为我们创建了两个字段。
hive> select * from student;
OK
NULL NULL
NULL NULL
NULL NULL
Time taken: 1.058 seconds, Fetched: 3 row(s)
hive>
我们不妨来试试查询student表中插入元素的数量,如下所示。我们从执行信息中可以看到Hive自动去调用MapReduce去统计我们的数量了,我们根本就没做什么事情。是不是很神奇呢。最后查询的结果是3,完全正确。
hive> select count(*) from student;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1478323409873_0001, Tracking URL = http://itcast03:8088/proxy/application_1478323409873_0001/
Kill Command = /itcast/hadoop-2.2.0/bin/hadoop job -kill job_1478323409873_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2016-11-05 14:35:51,757 Stage-1 map = 0%, reduce = 0%
2016-11-05 14:36:01,163 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.66 sec
2016-11-05 14:36:11,584 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.7 sec
MapReduce Total cumulative CPU time: 2 seconds 700 msec
Ended Job = job_1478323409873_0001
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 2.7 sec HDFS Read: 237 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 700 msec
OK
3
Time taken: 35.475 seconds, Fetched: 1 row(s)
hive>
既然我们建的student表没有指定列与列的分割符,那么我们接下来再建一张表并且指定分隔符。我们就建一张teacher表吧,建表语句如下。
hive> create table teacher(id bigint,name string)row format delimited fields terminated by '\t';
OK
Time taken: 0.545 seconds
hive> show create table teacher;
OK
CREATE TABLE `teacher`(
`id` bigint,
`name` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://ns1/user/hive/warehouse/teacher'
TBLPROPERTIES (
'transient_lastDdlTime'='1478344693')
Time taken: 0.309 seconds, Fetched: 13 row(s)
建好了teacher表,我们再来给teacher表中插入一些数据。我们的做法是新建一个teacher.txt文件并在里面输入一些数据,如下所示,输入完毕后保存退出该文件。
[root@itcast01 ~]# vim teacher.txt
1 赵老师
2 王老师
3 刘老师
4 邓老师
接下来我们把teacher.txt插入到teacher表当中。如下所示。
hive> load data local inpath '/root/teacher.txt' into table teacher;
Copying data from file:/root/teacher.txt
Copying file: file:/root/teacher.txt
Loading data to table default.teacher
Table default.teacher stats: [numFiles=1, numRows=0, totalSize=48, rawDataSize=0]
OK
Time taken: 0.764 seconds
hive>
上传完后,我们到HDFS文件系统中去看看我们的teacher表及数据。如下图所示,发现我们的表及teacher.txt文件都存在于HDFS中。
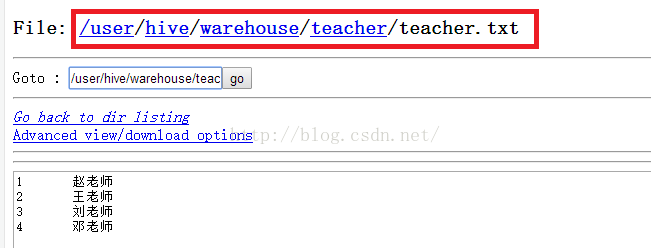
我们再通过shell命令来查看teacher表的信息,如下所示,可以看到我们查询到了teacher表中的数据。
hive> select * from teacher;
OK
1 赵老师
2 王老师
3 刘老师
4 邓老师
Time taken: 0.971 seconds, Fetched: 4 row(s)
hive>
我们以前学MapReduce的时数据的排序都需要我们手动写MapReduce程序来完成,现在有了Hive,我们只需要一条order by语句便可以搞定,假如我们想让teacher表中的数据降序排列,我们可以使用语句select * from teacher order by desc;我们并没有写任何MapReduce语句,接下来我们执行这条语句,信息如下,可以发现它会自动启用MapReduce来帮我们完成排序功能,真的是省去了我们很多麻烦。但是这也有个问题就是延迟性比较高,因为它要启动MapReduce,小弟要领取jar包领取任务,有可能还要执行多个MapReducer,因此延迟性便会比较多。
hive> select * from teacher order by id desc;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1478323409873_0002, Tracking URL = http://itcast03:8088/proxy/application_1478323409873_0002/
Kill Command = /itcast/hadoop-2.2.0/bin/hadoop job -kill job_1478323409873_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2016-11-05 20:52:32,598 Stage-1 map = 0%, reduce = 0%
2016-11-05 20:52:40,933 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.4 sec
2016-11-05 20:52:47,147 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.43 sec
MapReduce Total cumulative CPU time: 2 seconds 430 msec
Ended Job = job_1478323409873_0002
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 2.43 sec HDFS Read: 252 HDFS Write: 48 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 430 msec
OK
4 邓老师
3 刘老师
2 王老师
1 赵老师
Time taken: 25.794 seconds, Fetched: 4 row(s)
hive>
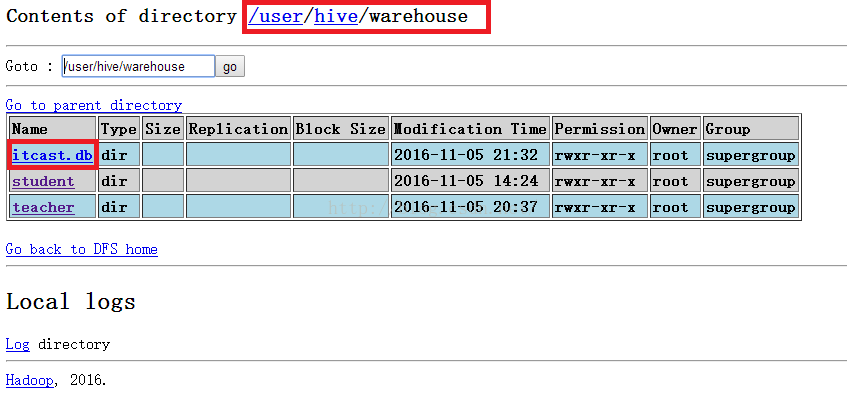
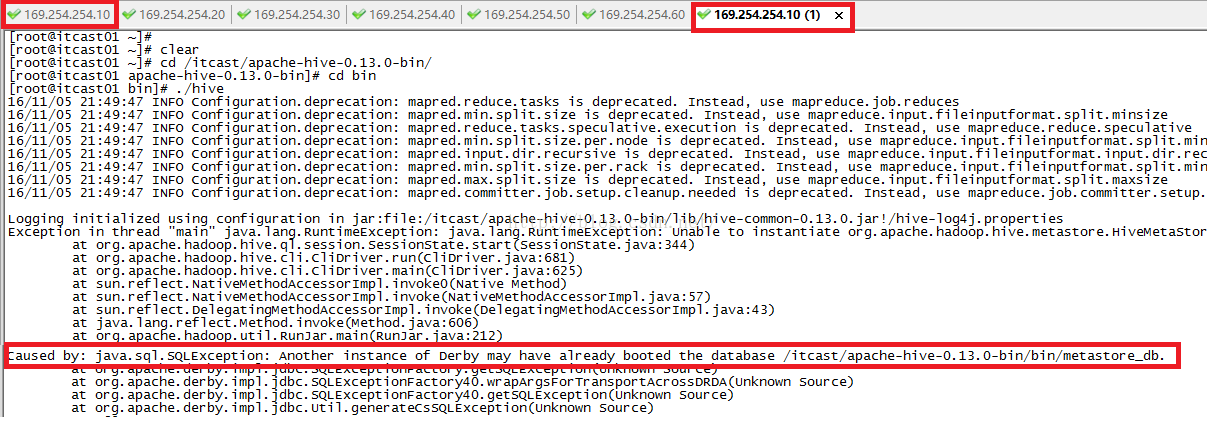
下面我们来说一下数据库的问题,我们在上面Hive架构图的时候提到了metadata元数据库,它里面有表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。Hive默认使用的元数据库是derby数据库,但是这个数据库有它致命的缺陷,那就是它仅支持单连接,这在公司的开发中简直就是恶梦。我下面为大家证明一下derby数据库仅支持单连接。
我们先hive的bin目录下启动hive并且建一个数据库itcast,如下所示。
启动hive
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
hive> create database itcast;
OK
Time taken: 0.579 seconds
hive> show databases;
OK
default
itcast
Time taken: 0.08 seconds, Fetched: 2 row(s)
hive> show tables;
OK
student
teacher
Time taken: 0.037 seconds, Fetched: 2 row(s)
hive> use itcast;
OK
Time taken: 0.012 seconds
hive> show tables;
OK
Time taken: 0.017 seconds
hive> create table user(id int,name string) row format delimited fields terminated by '\t';
OK
Time taken: 0.229 seconds
hive> show tables;
OK
user
Time taken: 0.016 seconds, Fetched: 1 row(s)
hive>
beeline derby.log ext hive hive-config.sh hiveserver2 metastore_db metatool schematool
[root@itcast01 bin]#
[root@itcast01 apache-hive-0.13.0-bin]# ls
bin conf examples hcatalog lib LICENSE NOTICE README.txt RELEASE_NOTES.txt scripts
[root@itcast01 apache-hive-0.13.0-bin]#
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
hive>
bin conf derby.log examples hcatalog lib LICENSE metastore_db NOTICE README.txt RELEASE_NOTES.txt scripts
[root@itcast01 apache-hive-0.13.0-bin]#
16/11/06 00:53:09 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /user/hive
[root@itcast03 bin]#
[root@itcast03 itcast]# ls
apache-hive-0.13.0-bin hadoop-2.2.0 hbase-0.96.2-hadoop2 sqoop-1.4.6 sqoop-1.4.6.bin__hadoop-2.0.4-alpha
[root@itcast03 itcast]# cd apache-hive-0.13.0-bin/
[root@itcast03 apache-hive-0.13.0-bin]# ls
bin conf examples hcatalog lib LICENSE NOTICE README.txt RELEASE_NOTES.txt scripts
[root@itcast03 apache-hive-0.13.0-bin]# cd conf
[root@itcast03 conf]# ls
hive-default.xml.template hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template
[root@itcast03 conf]#
hive-default.xml.template hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template
[root@itcast03 conf]# mv hive-default.xml.template hive-site.xml
[root@itcast03 conf]# ls
hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template hive-site.xml
[root@itcast03 conf]#
<!--配置连接的URL,现在我们的mysql安装在了itcast05上了,因此我们改成itcast05,如果hive库不存在我们创建它-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://itcast05:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!--连接驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!--连接数据库的用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<!--连接数据库的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>
anaconda-ks.cfg Documents hbase-0.96.2-hadoop2-bin.tar.gz install.log.syslog logs mysql-connector-java-5.1.40-bin.jar Public Templates time wc.txt
Desktop Downloads install.log jdk-7u80-linux-x64.gz Music Pictures sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz test.sh Videos
[root@itcast03 ~]# cp mysql-connector-java-5.1.40-bin.jar /itcast/apache-hive-0.13.0-bin/lib/
[root@itcast03 ~]#
[root@itcast03 bin]# ./hive
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:344)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:681)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:625)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:964)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:897)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:886)
at com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:1040)
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 10
Server version: 5.1.73 MySQL Community Server (GPL)
affiliates. Other names may be trademarks of their respective
owners.
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
hive> show tables;
OK
Time taken: 0.619 seconds
hive> create table people (id int,name string);
OK
Time taken: 0.396 seconds
hive>







anaconda-ks.cfg Documents hbase-0.96.2-hadoop2-bin.tar.gz install.log.syslog logs mysql-connector-java-5.1.40-bin.jar Public Templates time wc.txt
Desktop Downloads install.log jdk-7u80-linux-x64.gz Music Pictures sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz test.sh Videos
[root@itcast03 ~]# /itcast/apache-hive-0.13.0-bin/bin/hive
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
hive> show tables;
OK
people
Time taken: 0.401 seconds, Fetched: 1 row(s)
hive> exit;
[root@itcast03 ~]# ls
anaconda-ks.cfg Documents hbase-0.96.2-hadoop2-bin.tar.gz install.log.syslog logs mysql-connector-java-5.1.40-bin.jar Public Templates time wc.txt
Desktop Downloads install.log jdk-7u80-linux-x64.gz Music Pictures sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz test.sh Videos
[root@itcast03 ~]#
好了,本小节我们便一起学习到这里。

















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









