







目录
1.数据不一致?
如下代码所示,先将byte数组转String,然后将String再转回byte数组,发现结果和原始值不一致
public static void main(String[] args) {
byte[] bytes = {12, -56 - 18, -121, -119, 12};
System.out.println(Arrays.toString(bytes));
String str = new String(bytes);
System.out.println(str);
System.out.println(Arrays.toString(str.getBytes()));
}上述程序结果如下
[12, -74, -121, -119, 12]
���
[12, -17, -65, -67, -17, -65, -67, -17, -65, -67, 12]
要弄清楚为何不一样的原因,还需要从编码和解码说起
具体原因可看3.4.5
2.编码解码
编码是信息从一种形式或格式转换为另一种形式的过程,也称为计算机编程语言的代码,简称编码。用预先规定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号。编码在电子计算机、电视、遥控和通讯等方面广泛使用。编码是信息从一种形式或格式转换为另一种形式的过程。解码,是编码的逆过程

3.字符编码
3.1 字符集和字符编码编码
字符集是多个字符的集合,可以理解为二进制数,与字符的映射关系,唯一的一个编号就代表一个字
字符编码是计算机中对字符的表示方式
字符集与字符编码区别:
- 字符集是书写系统字母与符号的集合
- 字符编码则是将字符映射为一特定的字节或字节序列,是一种规则
字符集:ASCII、GBK,Big5,Unicode 等
字符编码:EUC-CN,Big5,utf8,utf16,utf32 等
ascii和unicode字符集 及 utf-8、utf-16等
3.2 ASCII
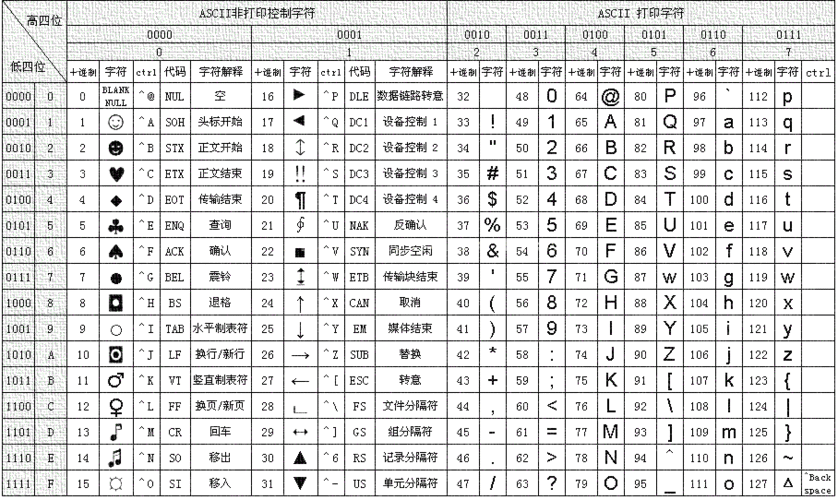
ASCII (American Standard Code for Information Interchange):美国信息交换标准代码是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准 ISO/IEC 646。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符
标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符 [1]
- 0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符)
- 在英语中,用128个符号编码便可以表示所有,但是用来表示其他语言,128个符号是不够的,这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号
- 不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段
- ASCII中一个字节对应一个字符
常见ASCII码的大小规则:数字< 大写字母 < 小写字母。
- 数字比字母要小。如 “7”<“F”;
- 数字0比数字9要小,并按0到9顺序递增。如 “3”<“8” ;
- 字母A比字母Z要小,并按A到Z顺序递增。如“A”<“Z” ;
- 同个字母的大写字母比小写字母要小32。如“A”<“a” 。
- 几个常见字母的ASCII码大小: “A”为65;“a”为97;“0”为 48
3.3 GB2312
GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312
基本集共收入汉字6763个和非汉字图形字符682个。整个字符集分成94个区,每区有94个位。每个区位上只有一个字符,因此可用所在的区和位来对汉字进行编码,称为区位码
GB2312标准把ASCII码表127号之后的扩展字符集去掉,并规定,小于127(0x7F)的编码按照ASCII标准进行解码,当出现连续两个大于127(0x7F)的编码时,这两个连续的大于0x7F的编码表示一个汉字,第一二个字节都是用0xA1~0xFE进行编码。其中,ASCII码中原有的数字字符、英文字符、标点等称为半角字符,大于0x7F的相应字符编码称为全角字符
GB 2312中对所收汉字进行了“分区”处理,每区含有94个汉字/符号。这种表示方式也称为区位码。
- 01-09区为特殊符号
- 16-55区为一级汉字,按拼音排序。
- 56-87区为二级汉字,按部首/笔画排序。
- 10-15区及88-94区则未有编码。
- 举例来说,“啊”字是GB2312之中的第一个汉字,它的区位码就是1601
在使用GB2312的程序中,通常采用EUC储存方法,以便兼容于ASCII。浏览器编码表上的“GB2312”,通常都是指“EUC-CN”表示法
每个汉字及符号以两个字节来表示。第一个字节称为“高位字节”(也称“区字节)”,第二个字节称为“低位字节”(也称“位字节”)
“高位字节”使用了0xA1-0xF7(把01-87区的区号加上0xA0),“低位字节”使用了0xA1-0xFE(把01-94加上 0xA0)。 由于一级汉字从16区起始,汉字区的“高位字节”的范围是0xB0-0xF7,“低位字节”的范围是0xA1-0xFE,占用的码位是 72*94=6768。其中有5个空位是D7FA-D7FE
例如“啊”字在大多数程序中,会以两个字节,0xB0(第一个字节) 0xA1(第二个字节)储存。区位码=区字节+位字节(与区位码对比:0xB0=0xA0+16,0xA1=0xA0+1)
- ASCII的字符完整地包含在GB2312里,编码不变,仍然是以0开头,用一个字节来表示一个字符;对于ASCII没有的字符,就用1开头来区分,用两个字节合起来表示一个字符
- 这样,在解码的时候,遇到字节是以0开头的,就知道这一个字节就表示了一个字符;遇到字节是以1开头的,就知道要加上下一个字节合起来表示一个字符。这样就在GB2312中既把ASCII的字符包含了进来,又能将它们区分出来,能达到兼容的效果了
代码验证:
public static void main(String[] args) throws UnsupportedEncodingException {
System.out.println(Arrays.toString("A".getBytes("GBK")));
System.out.println(Arrays.toString("啊".getBytes("GBK")));
System.out.println(Arrays.toString("啊".getBytes("GB2312")));
System.out.println(Arrays.toString("你好啊".getBytes("GB2312")));
}结果如下:
[65]
[-80, -95]
[-80, -95]
[-60, -29, -70, -61, -80, -95]
3.3 GBK
GBK编码在GB2312的基础上又增加了14240个汉字、生僻字和符号。按照GB2312的编码方式,两个字节已经不够用了,这时,GBK编码制定了新的标准:只要出现一个大于0x7F的字节,那么这个字节和它后面一个字节共两个字节就表示一个汉字(GB2312规定两个字节都大于0x7F才表示一个汉字),这样做的好处就是,GBK编码兼容了ASCII编码和GB2312编码。
GBK解码规则:当使用GB2312编码标准时,给定一串字符编码,按照字节进行检测,首先检测每个字节的大小,如果字节值小于0x7F,就用ASCII标准解码,如果遇到一个大于0x7F的字节,就把该字节和它后面一个字节连在一起用GBK标准进行解码,然后从第三个字节开始继续遍历检测
GBK和GB2312异同:
- GB2312和GBK是采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码
- GB2312为GBK的子集
- 在进行双字节编码时,GB2312“高位字节”使用了0xA1-0xF7(把01-87区的区号加上0xA0),“低位字节”使用了0xA1-0xFE(把01-94加上 0xA0),GBK双字节范围为8140-FEFE(首字节在 81-FE 之间,尾字节在 40-FE 之间)
public static void main(String[] args) throws UnsupportedEncodingException {
System.out.println(Arrays.toString("A".getBytes("GBK")));
System.out.println(Arrays.toString("啊".getBytes("GBK")));
System.out.println(Arrays.toString("啊".getBytes("GBK")));
System.out.println(Arrays.toString("你好啊".getBytes("GBK")));
// 编码有误 ,"癡" 不在 GB2312 字符集
System.out.println(Arrays.toString("癡".getBytes("GB2312")));
System.out.println(Arrays.toString("癡".getBytes("GBK")));
}结果为
[65]
[-80, -95]
[-80, -95]
[-60, -29, -70, -61, -80, -95]
[63]
[-80, 86]
3.4 Unicode
每个国家和地区都有一套自己的文字,不同的文字系统就要使用不同的编码标准,这就出现这样一个问题,同一个二进制编码在不同的编码标准中可能代表了不同的字符,比如0xB0A1,在GBK编码标准中为“啊”,而在Big5编码标准中就不是这个字了。这样,各个编码标准之间的不兼容就导致使用起来非常不方便。国际标准化组织ISO,将全球所有的语言所使用的字母、符号、文字进行统一编号,每个字符指定唯一一个标号与之对应(ASCII码编号不变),字符的编号从0x000000~0x10FFFF,该编号集称为Universal Multiple-Octet coded Character Set,简称UCS,一般也叫做Unicode。Unicode字符集仅仅是对所有字符进行了编号,并没有指定这些编号的编码规则,所以,后来才出现了各种Unicode的编码规则Unicode Transformation Format,典型的Unicode编码规则如UTF-8,UTF-16,UTF-32等
统一码(Unicode),也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求
3.4.1. UTF-32
Unicode Transformation Format 32,用32位(4字节)对Unicode字符集进行编码。编码时,Unicode字符集中的每一个字符都用4字节表示,直接把字符对应的Unicode编号转换为二进制数进行存储。而正因为UTF-32用4字节为每个字符编码,所以,UTF-32不兼容ASCII编码,使用ASCII编码标准写的程序,通过UTF-32编码方式打开会显示乱码。
解码时,直接按四个字节检测,编码与Unicode标号一一对应。
字符:A ASCII编码:0x41 Unicode编号:0x0000 0041 UTF-32编码:0x0000 0041
字符:啊 GBK编码:0xB0A1 Unicode编号:0x0000 554A UTF-32编码:0x0000 554A
3.4.2. UTF-16
Unicode Transformation Format 16,用16位(2字节)或32位(4字节)对Unicode字符集进行编码。对Unicode字符编号在0~65535的字符使用2字节编码,将每个字符的编号直接转换为2字节的二进制数0x0000~0xFFFF。而Unicode字符集在0xD800~0xDBFF区间内的编号不表示任何字符,UTF-16用这段编号与Unicode字符集中大于0xFFFF的字符编号进行映射,得到扩展的4字节编码。UTF-16也不兼容ASCII编码。
UTF-16解码时,按两个字节去检测,如果这两个字节都不在0xD800~0xDFFF之间,就说明是双字节编码的字符,使用双字节解码;如果这两个字节在0xD800~0xDFFF之间,说明是4字节编码的字符,以4字节解码。
3.4.3. UTF-8
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部分修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码
Unicode Transformation Format 8,用1,2,3,4个字节对Unicode字符集进行编码,每个字符根据自己的编号范围进行相应编码。它的编码规则是这样的:
对于UTF-8单字节的编码,该字节最高位设为0,剩余位填入字符的Unicode编号,对于Unicode编号在0x00000000~0x0000007F的字符,UTF-8编码只要一个字节,兼容ASCII编码。对于N字节的编码,第一字节最高位开始,前N位置为1,第N+1位设0,剩余字节最高位设为10,这N个字节的其余空位填充该字符的Unicode编号,高位补0。具体可见下表:
| UTF8-1 | 0x00-0x7F |
| UTF8-2 | 0xC2-0xDF 0x80-0xBF |
| UTF8-3 | 0xE0 0xA0-0xBF 0x80-0xBF 0xE1-0xEC 0x80-0xBF 0x80-0xBF 0xED 0x80-0x9F 0x80-0xBF 0xEE-0xEF 0x80-0xBF 0x80-0xBF |
| UTF8-4 | 0xF0 0x90-0xBF 0x80-0xBF 0x80-0xBF 0xF1-0xF3 0x80-0xBF 0x80-0xBF 0x80-0xBF 0xF4 0x80-0x8F 0x80-0xBF 0x80-0xBF |
解码时,看第一个字节
0开头:单字节解码;
110开头:双字节解码;
1110开头:三字节解码;
11110开头:四字节解码;
UTF-8编码的时候,汉字一般是占三个字节的
3.4.5乱码原因
综上所述,不同字符编码/解码规则不一样,字节范围也不一样,如果随便指定byte数组进行编码然后解码,则最终结果不一定如预期
[12, -74, -121, -119, 12]中-74,-121,-119连在一起不符合utf-8规范,因而将其置为了默认值-17, -65, -67。如果需要传输字节数组,业界一般采用base64编码后进行传输,或者可直接用ByteArrayOutputStream写出数据
4.base64编码
4.1Base64介绍
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。可查看RFC2045~RFC2049,上面有MIME的详细规范。
Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。采用Base64编码具有不可读性,需要解码后才能阅读。
Base64由于以上优点被广泛应用于计算机的各个领域,然而由于输出内容中包括两个以上“符号类”字符(+, /, =),不同的应用场景又分别研制了Base64的各种“变种”。为统一和规范化Base64的输出,Base62x被视为无符号化的改进版本
base64的初衷,是为了满足电子邮件中不能直接使用非ASCII码字符的规定.现在最常用的应用场景就是在http协议上传输较长的文本信息。它是将用户输入的二进制数据,打包成一种安全格式,将其作为http首部字段的值发送出去,而无须担心其中包含会破坏HTTP分析程序的冒号、换行符或二进制值。
除此以外,也有其他重要的意义:
a)所有的二进制文件,都可以因此转化为可打印的文本编码,使用文本软件进行编辑;
b)能够对明文文本进行简单的处理,只能防肉眼,就是一个君子加密方式。
最重要的特点
1.便于网络传输。
2.不可见性
4.2Base64原理
Base64要求把每三个8Bit的字节转换为四个6Bit的字节(3*8 = 4*6 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
关于这个编码的规则:
- 把3个字节变成4个字节
- 每76个字符加一个换行符
- 最后的结束符也要处理
- 其实还有一个垫字的"=",实际上是65个字符
Table 1: The Base64 Alphabet
| 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 |
| 0 | A | 17 | R | 34 | i | 51 | z |
| 1 | B | 18 | S | 35 | j | 52 | 0 |
| 2 | C | 19 | T | 36 | k | 53 | 1 |
| 3 | D | 20 | U | 37 | l | 54 | 2 |
| 4 | E | 21 | V | 38 | m | 55 | 3 |
| 5 | F | 22 | W | 39 | n | 56 | 4 |
| 6 | G | 23 | X | 40 | o | 57 | 5 |
| 7 | H | 24 | Y | 41 | p | 58 | 6 |
| 8 | I | 25 | Z | 42 | q | 59 | 7 |
| 9 | J | 26 | a | 43 | r | 60 | 8 |
| 10 | K | 27 | b | 44 | s | 61 | 9 |
| 11 | L | 28 | c | 45 | t | 62 | + |
| 12 | M | 29 | d | 46 | u | 63 | / |
| 13 | N | 30 | e | 47 | v | ||
| 14 | O | 31 | f | 48 | w | ||
| 15 | P | 32 | g | 49 | x | ||
| 16 | Q | 33 | h | 50 | y |
例子
举一个具体的实例,演示英语单词Man如何转成Base64编码。
| Text content | M | a | n | |||||||||||||||||||||
| ASCII | 77 | 97 | 110 | |||||||||||||||||||||
| Bit pattern | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| Index | 19 | 22 | 5 | 46 | ||||||||||||||||||||
| Base64-Encoded | T | W | F | u | ||||||||||||||||||||
第一步,"M"、"a"、"n"的ASCII值分别是77、97、110,对应的二进制值是01001101、01100001、01101110,将它们连成一个24位的二进制字符串010011010110000101101110。
第二步,将这个24位的二进制字符串分成4组,每组6个二进制位:010011、010110、000101、101110。
第三步,在每组前面加两个00,扩展成32个二进制位,即四个字节:00010011、00010110、00000101、00101110。它们的十进制值分别是19、22、5、46。
第四步,根据下图,得到每个值对应Base64编码,即T、W、F、u。
因此,Man的Base64编码就是TWFu。
如果字节数不足三,则这样处理:
a)二个字节的情况:将这二个字节的一共16个二进制位,按照上面的规则,转成三组,最后一组除了前面加两个0以外,后面也要加两个0。这样得到一个三位的Base64编码,再在末尾补上一个"="号。
比如,"Ma"这个字符串是两个字节,可以转化成三组00010011、00010110、00010000以后,对应Base64值分别为T、W、E,再补上一个"="号,因此"Ma"的Base64编码就是TWE=。
b)一个字节的情况:将这一个字节的8个二进制位,按照上面的规则转成二组,最后一组除了前面加二个0以外,后面再加4个0。这样得到一个二位的Base64编码,再在末尾补上两个"="号。
比如,"M"这个字母是一个字节,可以转化为二组00010011、00010000,对应的Base64值分别为T、Q,再补上二个"="号,因此"M"的Base64编码就是TQ==
4.3使用
private static Base64.Encoder BASE64_ENCODE = Base64.getEncoder();
private static Base64.Decoder BASE64_DECODE = Base64.getDecoder();
public static void main(String[] args) {
// 转成字符串
byte[] manByte = "Man".getBytes();
byte[] maByte = "Ma".getBytes();
byte[] mByte = "M".getBytes();
System.out.println(Arrays.toString(manByte));
System.out.println(Arrays.toString(maByte));
System.out.println(Arrays.toString(mByte));
// 编码
String manStr = BASE64_ENCODE.encodeToString(manByte);
String maStr = BASE64_ENCODE.encodeToString(maByte);
String mStr = BASE64_ENCODE.encodeToString(mByte);
System.out.println(manStr);
System.out.println(maStr);
System.out.println(mStr);
// 解码
System.out.println(Arrays.toString(BASE64_DECODE.decode(manStr)));
System.out.println(Arrays.toString(BASE64_DECODE.decode(maStr)));
System.out.println(Arrays.toString(BASE64_DECODE.decode(mStr)));
}结果
[77, 97, 110]
[77, 97]
[77]
TWFu
TWE=
TQ==
[77, 97, 110]
[77, 97]
[77]
5.url编码
5.1URL编码介绍
url编码是一种浏览器用来打包表单输入的格式。浏览器从表单中获取所有的name和其中的值 ,将它们以name/value参数编码(移去那些不能传送的字符,将数据排行等等)作为URL的一部分或者分离地发给服务器。不管哪种情况,在服务器端的表单输入格式样子象这样:
theName=Ichabod+Crane&gender=male&status=missing& ;headless=yes
使用 URL 在整个因特网中定位资源,就需要满足在不同协议间都相互兼容的能力。因此需要一种统一的 URL 命名规范,以避免 URL 在传输过程发生丢失数据的问题。比如一些特殊的字符,如果部分协议不识别,那么该部分内容就会丢失。为了避免这种情况,URL 设计了一种编码规则
5.2URL编码规则
URL编码遵循下列规则: 每对name/value由&;符分开;每对来自表单的name/value由=符分开。如果用户没有输入值给这个name,那么这个name还是出现,只是无值。任何特殊的字符(就是那些不是简单的七位ASCII,如汉字)将以百分符%用十六进制编码,当然也包括象 =,&;,和 % 这些特殊的字符。其实url编码就是一个字符ascii码的十六进制。不过稍微有些变动,需要在前面加上“%”。比如“\”,它的ascii码是92,92的十六进制是5c,所以“\”的url编码就是%5c
5.3使用
public static void main(String[] args) {
String encode = URLEncoder.encode("theName=Ichabod+Crane&gender=male&status=missing& ;headless=yes");
System.out.println(encode);
System.out.println(URLDecoder.decode("theName%3DIchabod%2BCrane%26gender%3Dmale%26status%3Dmissing%26%20%3Bheadless%3Dyes%0A"));
}结果
theName%3DIchabod%2BCrane%26gender%3Dmale%26status%3Dmissing%26+%3Bheadless%3Dyes
theName=Ichabod+Crane&gender=male&status=missing& ;headless=yes















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









