









训练数据集来自李航的《统计学习方法》特征选择一章,决策树的生成采用ID3或者C4.5算法,决策树剪枝暂未实现。
决策树的实现还是比较容易的,主要思路如下:
1. 先计算整体类别的熵
2. 计算每个特征将训练数据集分割成的每个子集的熵,并将这个熵乘以每个子集相对于这个训练集的频率,最后将这些乘积累加,就会得到一个个特征对应的信息增益。
3. 选择信息增益最大的作为最优特征分割训练数据集
4. 递归上述过程
5. 递归结束条件:训练集的所有实例属于同一类;或者所有特征已经使用完毕。
信息增益比的概念:对于特征A,信息增益和特征A的值得熵的比值。特征A的值的熵,就是特征A分割的每个子集对应于当前训练集生成的熵。
首先是文件开头加入如下两行,便于后面相应的调用
from math import log
import operator首先是实现熵的计算。
def calShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVect in dataSet:
currentLabel = featVect[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = labelCounts[key] / numEntries
shannonEnt -= prob * log(prob, 2)
return shannonEnt分割训练数据集。这里需要注意append和extend的用法。
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet生成训练数据集。四个标签分别为:年龄,有无工作,有无自己的房子,信贷情况。
def createDataSet():
dataSet = [['youth', 'no', 'no', 'just so-so', 'no'],
['youth', 'no', 'no', 'good', 'no'],
['youth', 'yes', 'no', 'good', 'yes'],
['youth', 'yes', 'yes', 'just so-so', 'yes'],
['youth', 'no', 'no', 'just so-so', 'no'],
['midlife', 'no', 'no', 'just so-so', 'no'],
['midlife', 'no', 'no', 'good', 'no'],
['midlife', 'yes', 'yes', 'good', 'yes'],
['midlife', 'no', 'yes', 'great', 'yes'],
['midlife', 'no', 'yes', 'great', 'yes'],
['geriatric', 'no', 'yes', 'great', 'yes'],
['geriatric', 'no', 'yes', 'good', 'yes'],
['geriatric', 'yes', 'no', 'good', 'yes'],
['geriatric', 'yes', 'no', 'great', 'yes'],
['geriatric', 'no', 'no', 'just so-so', 'no']]
labels = ['age', 'work', 'house', 'credit']
return dataSet, labels上面一个按照ID3算法选择每次特征选择时信息增益最大的特征。如果使用C4.5算法应该选择下面一个函数,即对于信息增益比的选择。
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueValue = set(featList)
newEntropy = 0.0
for value in uniqueValue:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / len(dataSet)
newEntropy += prob * calShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeaturedef chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calShannonEnt(dataSet)
bestInfoGainRatio = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueValue = set(featList)
newEntropy = 0.0
choosedFeatEnt = 0.0
for value in uniqueValue:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / len(dataSet)
newEntropy += prob * calShannonEnt(subDataSet)
choosedFeatEnt -= prob * log(prob, 2)
infoGain = baseEntropy - newEntropy
infoGainRatio = infoGain / choosedFeatEnt
if infoGainRatio > bestInfoGainRatio:
bestInfoGainRatio = infoGainRatio
bestFeature = i
return bestFeature当出现特征A已经被全部遍历完毕后,应该采用majorityvote策略,选择当面训练集中实例数最大的类。
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]用字典的形式构造一棵决策树。
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
# 训练集所有实例属于同一类
if classList.count(classList[0]) == len(classList):
return classList[0]
# 训练集的所有特征使用完毕,当前无特征可用
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree测试分类结果
myDat, labels = createDataSet()
myTree = createTree(myDat, labels)
print(myTree)ID3分类结果如下:
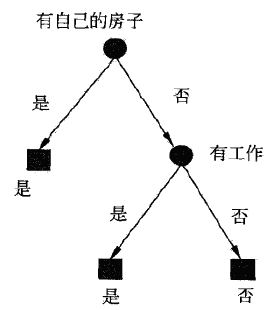
{‘house’: {‘yes’: ‘yes’, ‘no’: {‘work’: {‘yes’: ‘yes’, ‘no’: ‘no’}}}}















 2179
2179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









