






两年前,Kinvolk(https://kinvolk.io/) 优秀人士对 Linkerd 和 Istio 的性能进行了基准测试(https://kinvolk.io/blog/2019/05/performance-benchmark-analysis-of-istio-and-linkerd),结果显示,只有 Linkerd 消耗了更多的数据平面 CPU 之外,Linkerd 在其他方面表现都比 Istio 明显更好。最近,我们使用这两个项目的最新版本重复了这些实验。我们的结果显示,「Linkerd 不仅仍然比 Istio 快得多,而且现在消耗的数据平面内存和 CPU 也少了一个数量级」。这些结果甚至在吞吐量水平超过 Kinvolk 评估的3倍情况下仍可保持,你也可以自己进行测试。
背景介绍
2019 年,Kinvolk 发布了Linkerd 与 Istio 的公开基准数据比较(https://linkerd.io/2019/05/18/linkerd-benchmarks/) ,该测试提供了一个开源服务网格基准测试工具(https://github.com/kinvolk/service-mesh-benchmark),任何人都可以使用这个工具进行重复测试。这个测试工具之所以引人注目,是因为它模仿了"现实生活"的场景:它通过一个简单的微服务应用程序发送持续的流量,同时使用了 gRPC 和 HTTP 调用,并在内存和 CPU 消耗以及延迟的角度测量了使用服务网格的成本。最关键的是,延迟是从客户的角度来测量的,产生面向用户的数据,而不是通过内部代理实现。
Kinvolk 产生的第二件事是 Linkerd 和 Istio 在2019年左右的实际基准测试结果。这些数据显示,Linkerd 的速度明显更快,而且在所有考虑的因素中,Linkerd 的资源消耗也明显更小,除了一个方面:Linkerd 的数据平面(即它的代理)在最高负载水平下比 Istio 消耗更多的 CPU。
在这两个项目的多次版本更新发布两年后的今天,我们决定重新进行这些测试实验。
实验设置
在这些实验中,我们将 Kinvolk 基准测试工具应用于两个项目的最新稳定版本:Linkerd 2.10.2(默认安装)和 Istio 1.10.0(最小配置)。我们使用 Lokomotive Kubernetes 发行版的 Kubernetes v1.19 集群上运行了最新版本的基准测试工具。基准测试在 Equinix Metal(https://www.equinix.com/) 向 CNCF 项目提供的裸机硬件上运行。
首先是在 Equinix Metal 内找到一个测试环境,该环境可以在不同的运行中提供一致的结果。我们尝试的许多环境在不同的运行之间产生了巨大的延迟变化,包括在没有服务网格的情况。例如,在我们尝试的一个环境中,对于无服务网格的情况,基准报告的最大延迟从26ms到159ms不等!
我们最终在Equinix Metal dfw2数据中心找到了一个集群,它产生了一致的行为,每次运行之间的差异很小。该集群包含 6 个s3.xlarge.x86配置的工作节点(Intel Xeon 4214,具有 24 个物理内核 @2.2GHz 和 192GB内存)组成,基准应用程序在其上运行,加上一个相同配置的负载生成器节点,以及一个 c2.medium.x86 配置的 K8S 主节点。
接下来,我们需要关注测试的相关参数。虽然最初的 Kinvolk 工作评估了每秒 500 个请求 (RPS) 和 600 RPS 的性能,但我们想尝试一个更广的范围:我们评估了 20 RPS、200 RPS 和 2,000 RPS 的网格。在每个级别中,我们针对 Linkerd、Istio 和无服务网格的情况分别进行了6次独立运行,每次持续10分钟的负载。在两次运行之间,所有的基准测试和网格资源都进行了重新安装。对于每个级别,我们丢弃了具有最高延迟的单个运行结果,留下另外5个运行结果。查看我们的原始数据地址(https://docs.google.com/spreadsheets/d/1x0QXFAvL0nWOIGL5coaaW1xwsju5EmSjsqjw6bwHMlQ/)
请注意,Kinvolk 框架以一种非常特定的方式来测量服务网格的行为:
它测量控制平面和数据平面最高点的内存使用情况。换句话说,在运行中的任何时候,控制平面(作为一个整体,即任何子组件聚合在一起)的最高内存使用量被报告为该运行的控制平面内存消耗。
同样,任何单个数据平面代理的最高内存使用量报告为运行中的数据平面消耗量。
它以类似的方式测量 CPU 使用率,使用 CPU 时间作为测量标准。
它从客户端(负载生成器)的角度来测量延迟,其中包括集群网络上的时间、应用程序中的时间、代理中的时间等等。延迟是以分布的百分位数来提供报告的,例如 p50(中位数)、p99、p999(第 99.9%)等。
还要注意是,这个基准测试报告的数据是服务网格和设备及其环境的函数。换句话说,这些不是绝对的得分,而是相对的分数,只能与在相同环境和相同方式下测量的其他选择进行评估。
测试了哪些服务网格功能?
尽管每个服务网格都提供了大量功能,但是我们这里只测试了其中一部分功能:
两个服务网格都启用了 mTLS,并且所有应用程序 Pod 之间加密流量和验证身份。
两个服务网格都在跟踪指标,包括 L7 指标,尽管这些指标在本次实验中没有被消耗。
两个服务网格都默认在 INFO 级别记录各种日志,我们没有配置日志记录。
两种服务网格都能够添加重试和超时,以及以各种方式进行转移流量,但在本实验中没有明确使用这些功能。
没有启用分布式追踪、多集群通信或其他mesh-y功能。
结果
我们的实验结果如下图所示,图中的每个点都是五次运行的平均值,误差线代表该平均值的一个标准差。柱状图本身代表 Linkerd(蓝色)、Istio(橙色)和无服务网格的基线(黄色)。
20RPS 的延迟
从相对稳定的 20RPS 级别开始,我们已经看到了面向用户的延迟有很大差异。Linkerd 的中位延迟为17ms,比6ms的基线高11ms。相比之下,Istio 的中位延迟为26ms,几乎是 Linkerd 延迟的两倍。在最大延迟方面,Linkerd 最多在17ms的延迟基线上增加了53ms,而 Istio 的最大延迟则增加了188ms,是 Linkerd 延迟的三倍。
从百分位数来看,我们发现 Istio 的延迟分布在第99个百分位数时急剧上升到了200ms,而 Linkerd 则将较高的百分位数逐渐增加到70毫秒。

200RPS 的延迟
200RPS 这个延迟报告和上面的结果非常相似,中位数延迟的时间几乎相同,Linkerd 的中位延迟时间为17ms,比基线中位延迟的6ms高出11ms,而 Istio 的中位延迟时间为25ms,超过了19ms。在最大值上,Istio 的221ms延迟比23ms的基线要高200ms,而 Linkerd 最大延迟为92ms,高出约70ms,比Istio少2.5倍。我们看到 Istio 的延迟在第99个百分位时候发生了同样的跳跃,几乎达到了200ms的延迟,而 Linkerd 在第99.9个百分位时达到了近90毫秒的水平。

2,000RPS 的延迟
在2,000RPS 时,我们的评估结果超过了 Kinvolk 的三倍,我们再次看到了相同的情况:在中位数,Linkerd 在6ms的基线上多了额外的9ms延迟,而 Istio 则增加了15ms。在最大值下,Linkerd 在25ms的基线之上增加了47ms的额外时间,而 Istio 增加了5倍的额外时延 ~ 253ms。一般来说,在报告的每个百分位数上,Istio 都比 Linkerd 多了大概40%至400%的延迟。

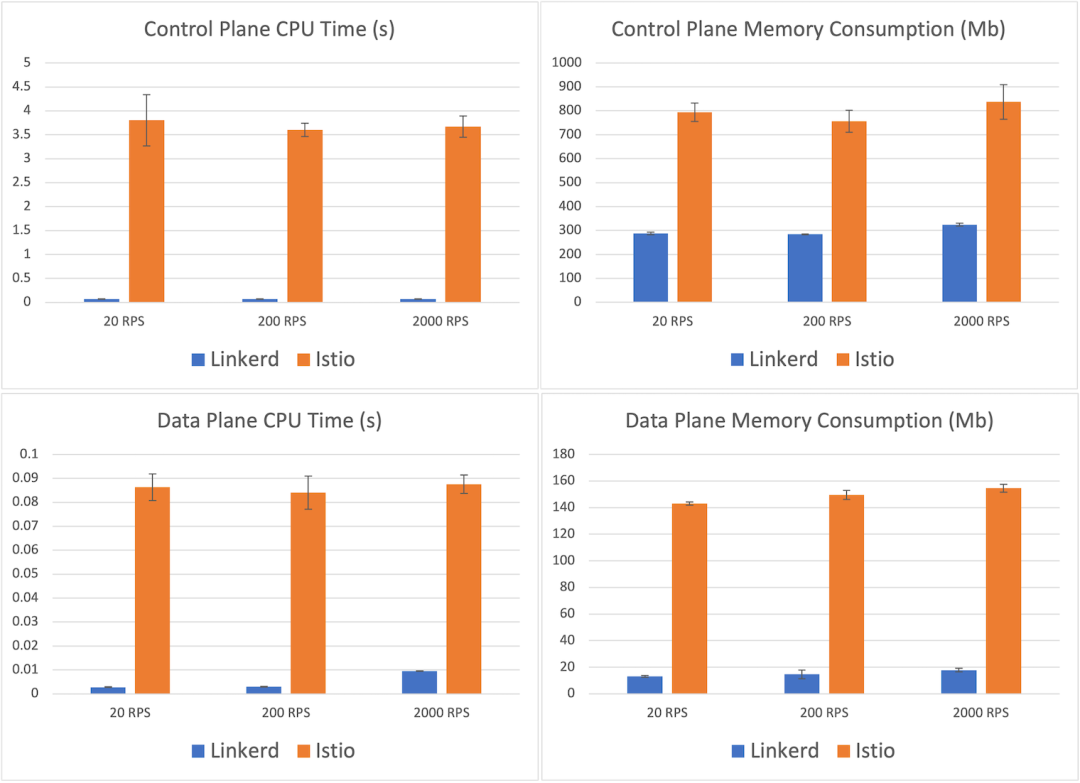
资源消耗
接下来我们来看看资源的使用情况。下图显示了每个服务网格的 CPU 和内存消耗。这些数据在所有吞吐量级别上是相当一致的,因此我们将重点关注最高负载的的2,000RPS 情况。
从控制平面开始,我们看到 Istio 的控制平面平均使用为837mb,约为 Linkerd 控制平面内存消耗 324mb 的2.5倍。Linkerd 的 CPU 使用率要小几个数量级,与 Istio 的3.7s相比,控制平面的 CPU 时间为71ms。
比控制平面更重要的是数据平面。毕竟,这是网格的一部分,必须随应用程序扩展。在这里,我们看到了另一个巨大的差异:Linkerd 代理消耗的最大内存平均为17.8mb,而 Istio 的 Envoy 代理消耗的最大内存为154.6mb(是8倍)。类似地,Linkerd 的最大代理 CPU 时间是10毫秒,而 Istio 的是88毫秒 - 几乎相差一个数量级。
总结与讨论
在这些基准测试中,我们看到 Linkerd 的性能明显优于 Istio,同时在关键的数据平面层面保持的资源成本要小很多个数量级。在最高吞吐量下,我们看到 Linkerd 在数据平面上消耗了1/9的内存和1/8的CPU,同时提供了 Istio 的 75%的中位延迟和不到1/5的额外最大延迟。
在这些实验中,我们选择使用了已经发布的 Kinvolk 的基础框架。在未来的工作中我们可能会做一些变化例如:
衡量累积的而不是最大的资源消耗更能反映真实的成本。
根据消耗的内核而不是 CPU 时间来衡量,可能更类似于衡量内存的方式。
计算所有运行数据的延迟百分位数,而不是取单个运行的百分位数的平均值,在统计上会更准确。
此外,我们的实验比 Kinvolk 的2019年实验简单得多,该实验涉及30分钟的持续流量、不同的集群、不同的数据中心以及用于控制可变硬件或网络的其他技术。在我们的案例中,我们明确使用一个变化较低的环境来运行测试。
为什么 Linkerd 这么快又轻呢?
Linkerd 和 Istio 在性能和资源成本上的巨大差异主要归结为一件事:Linkerd 的基于 Rust 的微代理 Linkerd2-proxy(https://linkerd.io/2020/12/03/why-linkerd-doesnt-use-envoy/)。这种微型代理为 Linkerd 的整个数据平面提供了动力,而这个基准测试在很大程度上反映了其性能和资源消耗。
我们已经写了很多关于 Linkerd2-proxy 的信息,以及我们在2018年采用Rust的动机。有趣的是,构建 Linkerd2-proxy 的主要原因不是性能,而是出于运维原因:运维像 Istio 这样基于 Envoy 的服务网格,往往需要你成为运维 Envoy 的专家,这是我们不愿意强加给 Linkerd 的用户的。
令人高兴的是,选择构建 Linkerd2-proxy 还可以显著提高性能和效率,通过解决仅作为一个服务网格 Sidecar 代理这一非常具体的问题,我们可以在数据平面层面上非常高效。通过在 Rust 中构建 Linkerd2-proxy,我们可以在该生态系统中获得令人难以置信的技术投资:像Tokio、Hyper和Tower这样的库是世界上一些最好的系统思维和系统设计。
Linkerd2-proxy 不仅仅具有令人难以置信的快速、轻便和安全性,它还代表了整个 CNCF 领域中一些最前沿技术。
未来的工作
奇怪的是,尽管Linkerd在这些基准测试中表现出色,但我们还没有集中精力对代理进行性能调优。我们期望在未来通过提高性能以带来额外的收益。
我们也热切地关注着SMP(https://smp-spec.io/)项目作为基准性能测试的标准。理想情况下,这些基准测试将由中立的第三方运行。
如何重现这些结果
如果您想自己复制这些实验,可以按照基准测试说明进行操作(https://github.com/linkerd/linkerd2/wiki/Linkerd-Benchmark-Setup)。如果您尝试这样做,请参考上面有关实验方法。关键是你要找到一个能够提供一致结果的环境,特别是对于像是对延迟比较敏感的场景,这些场景对网络流量、资源争夺等非常敏感。另外需要记住,你产生的数据将是相对的,而不是绝对的。
推荐
kubectl debug | 调试Kubernetes的最简方法
















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









