本文先介绍生成模型(generative model)和判别模型(discriminative model)的区别,然后重点介绍生成模型中的两个例子:高斯判别分析(Gaussian discriminant analysis)和朴素贝叶斯方法(Naive Bayes)
生成模型和判别模型
监督学习一般学习的是一个决策函数:
y=f(x)('.replaybtns').click(function(e){
或者是条件概率分布:
p(y|x)
判别模型直接用数据学习这个函数或分布,例如Linear Regression和Logistic Regression。
生成模型是用数据先学习联合概率分布
p(x,y)
预测数据x的时候,当
p(y|x)
这里用了期望风险最小化准则(Empirical Minimization Principle),具体可以查看《统计学习方法》的chapter4.1.2。
1.Gaussian Discriminant Analysis
在生成模型中,我们需要知道的就是p(x|y))。
如果我们观察到样本的X大致服从多维正态分布,那么这时候我们可以使用GDA模型来预测数据。
1、首先在GDA中假设:
yx|y=0x|y=1∼Bernoulli(ϕ)∼N(μ0,Σ)∼N(μ1,Σ)
也就是:
p(y)p(x|y=0)p(x|y=1)=ϕy(1−ϕ)1−y=12πn/2|Σ|1/2exp(−12(x−μ0)TΣ−1(x−μ0))=12πn/2|Σ|1/2exp(−12(x−μ1)TΣ−1(x−μ1))
\begin{align}p(y)&=\phi^y(1-\phi)^{1-y}\\
这里的x是所有特征
x1,x2,⋅⋅,xn。
2.极大似然估计4个参数:ϕ,μ0,μ1,Σ
对数化似然函数
ℓ=log∏i=1mp(x(i),y(i))=log∏i=1mp(x(i)|y(i))p(y(i))=∑i=1m[y(i)logϕ+(1−y(i))log(1−ϕ)−12(x−μy(i))TΣ−1(x−μy(i))+log12πn/2|Σ|1/2]
\begin{align} \ell&=log\prod_{i=1}^mp(x^{(i)},y^{(i)})\\ &=log\prod_{i=1}^mp(x^{(i)}|y^{(i)})p(y^{(i)})\\ &=\sum_{i=1}^m\left[y^{(i)}log\phi+(1-y^{(i)})log(1-\phi)\\-\frac12(x-\mu_{y^{(i)}})^T\Sigma^{-1}(x-\mu_{y^{(i)}})+log\frac1{{2\pi}^{n/2}|\Sigma|^{1/2}}\right]
(1)对于ϕ
令∇ϕℓ=0
(2)对于μ0:
∇μ0ℓ=∇μ0∑i=1m([−12(x(i)−μ0)TΣ−1(x(i)−μ0)]1{y(i)=0})=∑i=1m([12Σ−1(x(i)−μ0)]1{y(i)=0})
\begin{align}\nabla_{\mu_0}\ell&=\nabla_{\mu_0}\sum_{i=1}^m\left(\left[-\frac12(x^{(i)}-\mu_0)^T\Sigma^{-1}(x^{(i)}-\mu_0)\right]1\{y^{(i)}=0\}\right)\\
令
∇μ0ℓ=0,得
0μ0=∑i=1m((x(i)−μ0)1{y(i)=0})=∑mi=11{y(i)=0}x(i)∑mi=11{y(i)=0}(直观解释是y=0类中x的平均值)
\begin{align}0&=\sum_{i=1}^m\left((x^{(i)}-\mu_0)1\{y^{(i)}=0\}\right)\\
(3)同理得μ1
(4)对于Σ:
∇Σℓ=∇Σ∑i=1m(−12(x(i)−μy(i))TΣ−1(x(i)−μy(i))+log12πn/2|Σ|1/2)=∑i=1m((x(i)−μy(i))(x(i)−μy(i))TΣ−2−Σ−1)
\begin{align}\nabla_\Sigma\ell&=\nabla_\Sigma\sum_{i=1}^m\left(-\frac12(x^{(i)}-\mu_{y^{(i)}})^T\Sigma^{-1}(x^{(i)}-\mu_{y^{(i)}})+log\frac1{{2\pi}^{n/2}|\Sigma|^{1/2}}\right)\\
令
∇Σℓ=0,得
∑i=1m(x(i)−μy(i))(x(i)−μy(i))T=mΣΣ=1m∑i=1m(x(i)−μy(i))(x(i)−μy(i))T
\sum_{i=1}^m(x^{(i)}-\mu_{y^{(i)}})(x^{(i)}-\mu_{y^{(i)}})^T=m\Sigma\\
至此我们得到了参数ϕ,μ0,μ1,Σ来预测新数据。最终GDA模型可见下图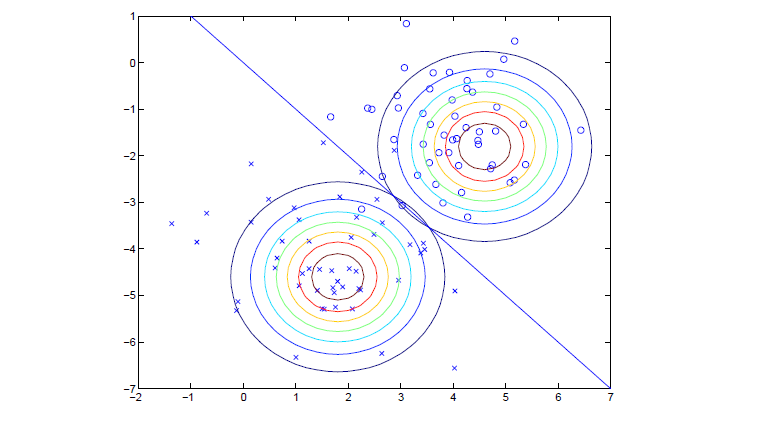
2.GDA and Logistic Regression
高斯判别和LR属于两种不同的模型,但却有着很大的关系。我们可以将GDA的p(y=1|x),由此我们可以看到GDA是可以转化为LR的。为什么呢?
因为在GDA我们假设X是服从高斯分布,Y服从伯努利分布,而在LR中我们只假设了Y是伯努利分布,所以强假设必然是可以推出弱假设的。事实上只要X服从指数分布族,我们都可以推导出LR;相反,LR没法推导出GDA,因为LR本身是不知道X的真实分布的。(回忆LR的推导,我们是通过指数分布族来找到X到Y的映射函数,然后再进行学习参数θ;也就是说,其实不管x是什么分布,我们都可以通过指数分布族变换得到logistic function来进行映射)。
那么什么时候用GDA,什么时候用LR呢?当我们知道X的分布时,GDA明显是更好的选择,因为它做了更强的假设,实际中,即使数据很少,GDA也会有很好的效果;然而,大部分时候我们都是不知道X的分布的,所以LR会有更好的健壮性。
3.Naive Bayes
朴素贝叶斯模型也是生成模型中的一种。
在GDA中,我们假设X是连续的,服从高斯分布;NB中我们假设X是离散的,服从多项分布(包括伯努利)。GDA的X可以用多维高斯分布表示,但是在NB中我们却不能直接使用多项分布。我们用垃圾邮件分类器来阐述NB的思想。
在这个分类器中我们可以用单词向量作为输入特征,具体的,我们的单词书中如果一共有50000个词,那么一封邮件的x向量可以是
x=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢100⋅⋅1⋅⋅0⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥aaardvarkaardwolf⋅⋅buy⋅⋅zen
x是一个50000维的向量,在这封邮件中如果存在字典中的词,那该词所在的位置设置为1;否则为0。
如果要直接用多项分布对
p(x|y)个参数使参数和为1,对如此多的参数进行估计是不现实的,所以我们做一个强假设来简化概率模型。
3.1 建模
1.假设
在NB中,我们假设x的每一维特征(也就是每一个词)都是条件独立的:即每个词在邮件中都独立出现,互不影响。而现实中有些词是很可能同时出现的,比如nike和sport,所以这就是naive bayes中naive的由来。尽管如此,NB对于大部分问题还是有很好的效果。根据这个假设可以得到
p(x1,⋅⋅⋅,x50000|y)=p(x1|y)p(x2|y,x1)p(x3|y,x1,x2)⋅⋅⋅p(x50000|y,x1,⋅⋅⋅,x49999)=p(x1|y)p(x2|y)p(x3|y)⋅⋅⋅(x50000|y)=∏j=1np(xj|y)
p(x_1,\cdot\cdot\cdot,x_{50000
第一个等式使用了条件概率链式法则,第二个等式利用了条件独立假设。这时候模型就可以用
ϕj|y=1,ϕj|y=0,ϕy。
注意
xj是输入x中的第j个特征(第j个单词)。
2.极大似然估计
对数化似然函数
ℓ=log∏i=1mp(x(i),y(i))=log∏i=1mp(x(i)|y(i))p(y(i))=log∏i=1m⎛⎝∏j=1np(x(i)j|y(i))⎞⎠p(y(i))=∑i=1m⎛⎝logp(y(i))+∑j=1nlogp(x(i)j|y(i))⎞⎠=∑i=1m⎡⎣y(i)logϕy+(1−y(i))log(1−ϕy)+∑j=1n(x(i)jlogϕj|y(i)+(1−x(i)j)log(1−ϕj|y(i)))⎤⎦
\begin{align} \ell&=log\prod_{i=1}^mp(x^{(i)},y^{(i)})\\ &=log\prod_{i=1}^mp(x^{(i)}|y^{(i)})p(y^{(i)})\\ &=log\prod_{i=1}^m\left(\prod_{j=1}^np(x_j^{(i)}|y^{(i)})\right)p(y^{(i)})\\ &=\sum_{i=1}^m\left(logp(y^{(i)})+\sum_{j=1}^nlogp(x_j^{(i)}|y^{(i)})\right)\\
(1)对于ϕj|y=0,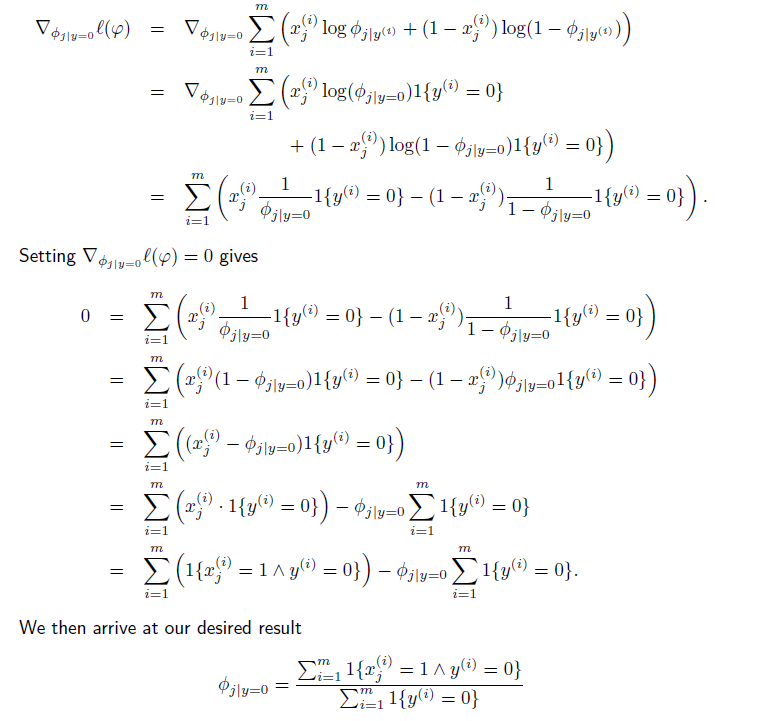
这个估计的直观解释就是所有y=0的样本中有单词xj的邮件数量除以y=0样本个数
(2)同理得
ϕj|y=1=∑mi=11{x(i)j=1∧y(i)=1}∑mi=11{y(i)=1}
这个估计的直观解释就是所有y=1的样本中有单词
xj的邮件数量除以y=1样本个数
(3)对于ϕy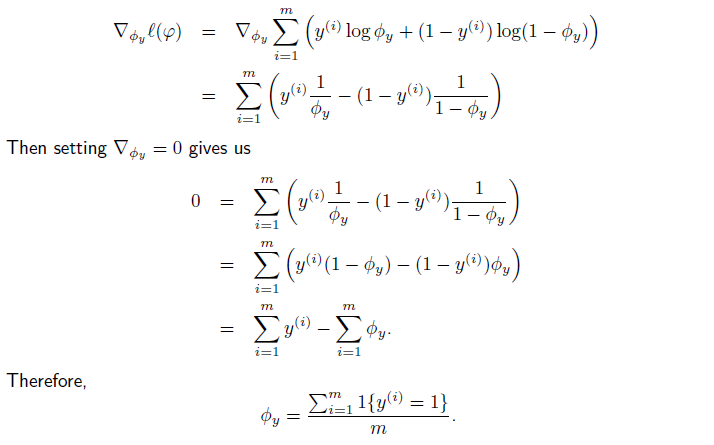
3.预测
利用training_set,我们可以估计出ϕi|y=1,ϕi|y=0,ϕy来分类垃圾邮件。
3.2 Laplace smoothing
不过这样建模是有问题的,假设NIPS这个单词是字典中的第23333个词,那它对应的参数是ϕ23333|y,这时极大似然估计明显是不合理的一种估计。所以我们用贝叶斯估计来解决这个问题。
条件概率p(x|y)
后验概率p(y)
当λ=1时,我们叫这种估参处理方法为laplace smoothing,邮件分类器中的参数估计自然就变成
ϕj|y=1=∑mi=11{x(i)j=1∧y(i)=1}+1∑mi=11{y(i)=0}+2ϕj|y=0=∑mi=11{x(i)j=1∧y(i)=0}+1∑mi=11{y(i)=0}+2ϕy=∑mi=11{y(i)=1}+1m+2
\phi_{j|y=1}=\frac{\sum_{i=1}^m1\{x_j^{(i)}=1\wedge y^{(i)}=1\}+1}{\sum_{i=1}^m1\{y^{(i)}=0\}+2}\\\phi_{j|y=0}=\frac{\sum_{i=1}^m1\{x_j^{(i)}=1\wedge y^{(i)}=0\}+1}{\sum_{i=1}^m1\{y^{(i)}=0\}+2}\\
这样就不会出现0的情况了,事实上这也是贝叶斯估计和极大似然估计的差别。
3.3 应用
邮件分类器中我们的输入x仅仅是一个伯努利分布,xi∈{0,1},然后用多项分布来建模。
在有些情况下,我们的x不能很好被GDA,我们就可以尝试离散化数据,比如在房价预测问题中,离散化处理房子面积数据,然后就可以使用NB来预测了。 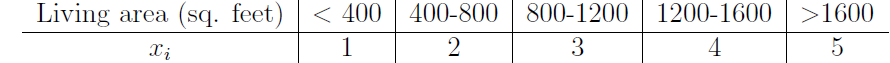
4.文本分类事件模型
在前面叙述的邮件分类模型中,我们假设x是二项分布的,显然这种模型没有考虑到单词出现次数对邮件分类的影响程度。所以我们有了multinomial event model。还是和原来模型一样,有一份字典含有50000个单词,一份邮件以“The NIPS is ……”开头,在multinomial event model中,这封邮件的x可以表示为
x=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢3555523333133331⋅⋅⋅45555⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥TheNIPSisa⋅⋅⋅welcome
x的维数由邮件中的单词数量决定。
这种事件模型的对数似然函数为
ℓ=log∏i=1mp(x(i),y(i))=log∏i=1mp(x(i)|y(i))p(y(i))=log∏i=1m⎛⎝∏j=1nip(x(i)j|y(i))⎞⎠p(y(i))
\begin{align} \ell&=log\prod_{i=1}^mp(x^{(i)},y^{(i)})\\ &=log\prod_{i=1}^mp(x^{(i)}|y^{(i)})p(y^{(i)})\\
这里的
ni对于每个样本都是不一样的。
所以参数估计就是
ϕk|y=1=∑mi=1∑nij=11{x(i)j=k∧y(i)=1}+1∑mi=11{y(i)=0}ni+50000ϕk|y=0=∑mi=1∑nij=11{x(i)j=k∧y(i)=0}+1∑mi=11{y(i)=0}ni+50000ϕy=∑mi=11{y(i)=1}+1m+2
\phi_{k|y=1}=\frac{\sum_{i=1}^m\sum_{j=1}^{n_i}1\{x_j^{(i)}=k\wedge y^{(i)}=1\}+1}{\sum_{i=1}^m1\{y^{(i)}=0\}n_i+50000}\\\phi_{k|y=0}=\frac{\sum_{i=1}^m\sum_{j=1}^{n_i}1\{x_j^{(i)}=k\wedge y^{(i)}=0\}+1}{\sum_{i=1}^m1\{y^{(i)}=0\}n_i+50000}\\
参考资料:
【1】cs229 by Andrew Ng from 网易公开课.
【2】《统计学习方法》李航























 1万+
1万+


 到【灌水乐园】发言
到【灌水乐园】发言









1个评论
看了这么多网页,你写的是最清楚的,能看得明白
2015-08-21 09:40:23回复