







本文主要介绍生成模型(generative model)和判别模型(discriminative model)的区别,并重点讲生成学习模型最重要的两个例子:高斯判别分析(Gaussian discriminant analysis)和朴素贝叶斯方法(Naive Bayes)。
一、生成学习模型和判别模型
我们原来一直讨论的诸如逻辑回归,线性回归等方法都是判别学习算法(discriminative learning algorithms)的例子,这些算法主要是模型为P(y|x)或者找h(x)∈{0,1}两种方式。
而生成学习算法(generative learning algorithms)指的是模型为P(x|y)的方式。
下面举一个例子来分析一下两种模型的区别:
假设需要基于一些特征区分大象(y = 1)和狗(y = 0),给定训练集。对于诸如逻辑回归或者感知器算法的
判别学习算法
,它们试图找到一条直线(决策边界decision bound)来区分开狗和大象,当有一个新的动物出现时,只要检查新动物的特征在决策边界的哪边来决定这种动物的种类。下面对于
生成学习算法
,我们换一个角度。首先建立一个模型来建模大象的特征p(x,y=1),再建立一个狗的特征模型p(x,y=0),出现了一个新动物,只要判断新动物和哪种模型更像就可以。这种方法不是直接区分0或1。在得到了p(y)和p(x|y)
之后,根据贝叶斯规则得到(其中p(x)等于
p(x) = p(x|y= 1)p(y= 1) + p(x|y=0)p(y= 0) ):

在预测新数据时,最大化p(y|x)得到此时y:

二、Gaussian Discriminant Analysis(高斯判别分析)
首先介绍第一个生成学习模型:GDA,这里假设p(x|y)是服从多维正态分布的。
1、简单介绍一下multivariate Gaussian distribution。
可以写成'N (µ,Σ)',µ为均值,Σ为协方差矩阵,Σ要求为symmetric(对称)和positive semi-definite(半正定)的。定义:

其中“|Σ|”表示Σ的determinant(行列式)。
对于一个随机变量X均值可以表示为:

对于矢量(vector-valued)随机变量Z,Cov(Z)=E[(Z−E[Z])(Z−E[Z])T],也可以写成Cov(Z) =
E[Z*ZT]−(E[Z])(E[Z])T
若X∼N(µ,Σ),则:

这里有一个注意的地方,协方差矩阵度量的是维度之间的相似性,而不是样本之间的相似性,
2、The Gaussian Discriminant Analysis model(高斯判别模型)
当我们遇到一个分类问题,输入特征x是一个连续随机变量,这时就可以利用GDA方法用一个多维高斯分布来建模p(x|y)。
首先:假设y服从伯努利分布,x|y服从多元正态分布

也就是

接着:
由上面生成学习算法关于p(y|x)的求解方式可以得知,数据的对数似然函数(log-likelihood)为(这里我是参考别人的写的,开始我感觉这个其实就是在利用前面的公式最大化后验概率P(y|x)而不是在求似然函数,不过后来发现这里的目的实际上是在求参数,就是似然函数,这里好像是频率学派和贝叶斯学派的不同观点,不是太明白。这里弄明白一点了,开始理解错了,其实这个就是简单的在已知输入但参数未知的情况下想要求参数而已,没有利用前面的概率公式) :

求解最大化似然函数的方法:分别对每个参数最大化L,我们可以利用训练数据(这是利用了经验风险最小化Empirical Minimization Principle)得到最大似然估计得到结果(具体计算方法参见http://blog.csdn.net/sz464759898/article/details/44342923):

这样我们就可以根据训练数据得到的参数,通过前面说过的公式![]() 来预测新数据。整个算法的图示如下:
来预测新数据。整个算法的图示如下:
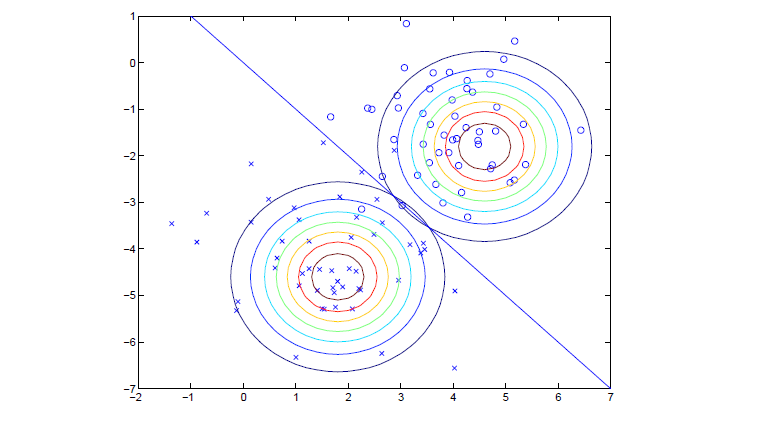
图中表示的是训练集的图示,如两个高斯分布等高线(contours)拟合了两类,由于有相同的协方差矩阵,所以两个看着很相似,只是均值造成的位置不同,可以看到中间的直线,表达的是p(y=1|x)=0.5。
总结一下GDA过程,首先给定一组训练集我们要拟合出P(x|y)和P(y)通过![]() 这四个参数。然后就构造出
这四个参数。然后就构造出![]() 这个表达式,对每个新数据得到了p(y|x)就可以得出所属类别。
这个表达式,对每个新数据得到了p(y|x)就可以得出所属类别。
当我们知道X的分布时,GDA明显是更好的选择,因为它做了更强的假设,实际中,即使数据很少,GDA也会有很好的效果;然而,大部分时候我们都是不知道X的分布的,所以逻辑回归(LR)会有更好的健壮性(鲁棒性)。
三、Navie Bayes模型
(一)理论基础
在GDA中,输入特征向量x是连续的实值向量;而在NB中X是离散的。理解贝叶斯模型的基础是贝叶斯公式

贝叶斯公式的推导过程为:

其中P(Y)称为先验概率,P(Y|X)叫做后验概率,P(Y,X
)叫做联合概率
大概说一下先验和后验概率的用途,根据一些发生的事实(如训练集),分析结果产生的最可能的原因(也就是最大置信度)(如标签)。
我们的目的是通过带标签训练数据得到除了后验概率的概率值,再对测试数据求使得其后验概率最大值的标签作为结果。
(二)朴素贝叶斯
上面讲的实际上是贝叶斯模型。我们常用的朴素贝叶斯模型是指条件独立假设的模型(在分类中这里指的是特征之间相互独立,这里的独立是指在y的条件下特征是独立的P(X1|y) = P(X1|y,X2),而不是P(X1) = P(X1|X2)
)
。用一个公式可以表达成:

类似NB这种概率模型往往在进行语义处理的时候比较好用,因为可以把一句话进行分词后计算出现某类词的时候这句话属于什么类型(比如是不是广告)。但是朴素贝叶斯由于假设词语之间是独立的所以对,“我司可办理正规发票”与“正规发票可办理我司”是相同的,虽然在语义分析可能不是很好用,但是在垃圾邮件分类等使用环境下是很好用的。
这个模型的参数为 ,
,
 和
和
在给定了训练集
 后,联合似然函数可以变为
后,联合似然函数可以变为
,和
在给定了训练集
后,联合似然函数可以变为

最大化参数得到对应的似然估计参数:

(这里的假设xi之间是相互独立的,而且是离散的属性,在许多的介绍中都写的是:为了计算P(xi|y=1),可以通过计算在y=1的情况下属性为xi的数量除以y=1类的数量,而先验概率也就是y=1通过y=1的数量除以训练的总元组数。也就是把上面的公式直接表达出来了)
对于一个新的样本我们只要计算下面的式子就可以了,大于百分之五十为正样本小于则为负样本:

(三)Laplace平滑
这里还会出现一种情况,就是测试样本中有的词在训练集中没有出现过,这时 和
和 为0,也就造成
为0,也就造成 出现了0/0的情况。为了解决这一问题,我们可以不考虑这个词语,但是这也导致很多信息浪费掉了。我们也可以给一个 很小的概率值,方法是在参数估计的分子上加1,分母加上m(m为类别的数量,这里我们为2)
出现了0/0的情况。为了解决这一问题,我们可以不考虑这个词语,但是这也导致很多信息浪费掉了。我们也可以给一个 很小的概率值,方法是在参数估计的分子上加1,分母加上m(m为类别的数量,这里我们为2)
和为0,也就造成出现了0/0的情况。为了解决这一问题,我们可以不考虑这个词语,但是这也导致很多信息浪费掉了。我们也可以给一个 很小的概率值,方法是在参数估计的分子上加1,分母加上m(m为类别的数量,这里我们为2)

(四)连续值属性
这里为了主要是论述的离散属性和简单的贝叶斯方法,下面对连续属性也做一个介绍:
前面说过,特征属性为离散值时,只要很方便的统计训练样本中各个划分在每个类别中出现的概率就可以估计P(xi|y)而对于连续值,通常需要知道连续的属性值服从的分布。通常假设为高斯分布,即:

因此
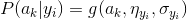
只要计算出训练样本的均值和标准差,带入上面的公式就可以得到估计值了。
(五)朴素贝叶斯应用的流程
朴素贝叶斯其实本质上就是根据训练集得到先验概率,然后在已经有的先验概率的基础上,对于一个新来的数据求解在各个类别中概率最大的那个就好了。这里说的很好。
后面会利用python进行实际的编码操作
参考:















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









