






为什么要有slub?
- 提供小内存。内核管理页面使用了2个算法:伙伴算法和slub算法,伙伴算法以页为单位管理内存,但在大多数情况下,程序需要的并不是一整页,而是几个、几十个字节的小内存。于是需要另外一套系统来完成对小内存的管理,这就是slub系统。slub系统运行在伙伴系统之上,为内核提供小内存管理的功能。
- 针对经常分配并释放的对象,它也用作一个缓存,以提高分配和释放的效率:slub分配器将释放的内存块保存在一个内部列表中,并不马上返回给伙伴系统。当请求为该类对象分配一个新的实例时,会使用最近释放的内存块。

slub的框架结构
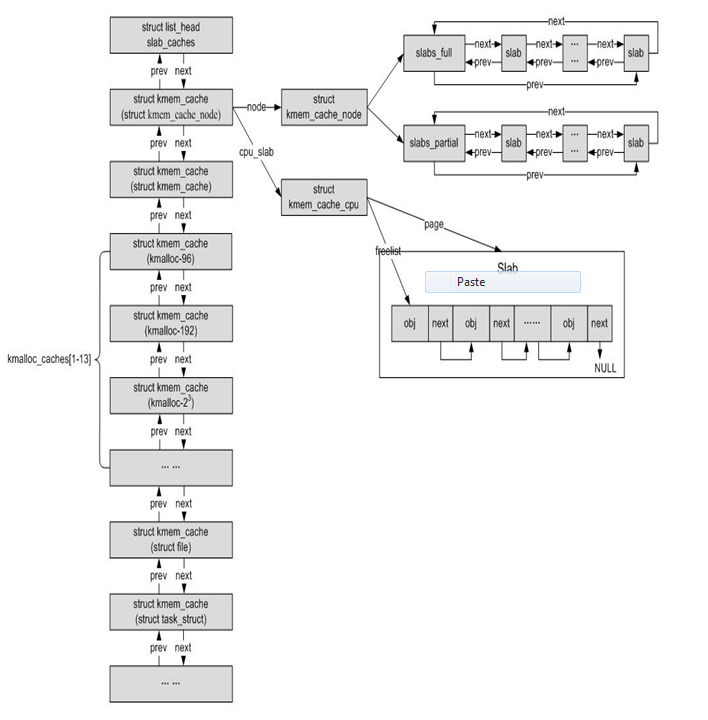
slub相关的结构体
1. kmem_cache_node:里面有partial和full两个域,所有的半满slub形成一个双链表,所有的full slub也形成了一个双链表。partial和full就分别指向这两个双链表的表头。
2. kmem_cache_cpu:里面有freelist和page两个域,page指向的是当前用的slub的第一个page页的地址,而freelist指向的是slub中第一个空闲的object的首地址;
3. kmem_cache:即slub缓存。kmem_cache_node和kmem_cache_cpu都是属于kmem_cache结构体的。kmem_cache_node的数目取决于内存节点的个数,而kmem_cache_cpu是每个cpu有一个这样的结构体。
打个比方,一个slub缓存就像是一个经销商,它只能卖特定大小的内存给用户。而kmem_cache_node就像是一个大仓库,里面存放着很多slub。这些slub就是kmem_cache_node这个大仓库里面的小仓库,里面储存着用过的以及没用过的特定大小的内存。kmem_cache_cpu就像是前台,每个cpu都有一个这样的前台。这个前台最多只保留一个slub,也就是一个小仓库的货。如果货卖光了,那么它就去大仓库里拿一个小仓库的货过来。buddy system则像是供应商。如果连大仓库里面都没有货的话,那么slub缓存这个经销商就要像buddy system这个供应商申请供货,然后拿到前台去卖。
讲到这里,读者可能有一个问题:slub的建立需要kmem_cache_node和kmem_cache_cpu结构体,而kmem_cache_node和kmem_cache_cpu从图上来看也需要有slub缓存来进行分配,那么它们究竟谁先出现呢?这是一个鸡生蛋和蛋生鸡的问题。linux中是这样处理的:
- 首先通过buddy system来获得free pages,在free pages上分配一个初始的kmem_cache_node结构体变量。注意这些free pages不是slub,这么大的空间上只分配了一个初始变量;
- 以这个变量作为参数,向buddy system申请slub,由后面的描述我们知道,这时候buddy system会分配一些free pages作为slub给kmem_cache_node的kmem_cache;
- 现在,已经有slub可以独立的分配kmem_cache_node了,linux再向slub申请一个kmem_cache_node的对象,并且将步骤1中那个初始的变量复制到这个新分配的对象中;
- 此时步骤1中初始的变量已经没有什么用了,linux将其释放,相应的,步骤1中分配的free pages也会被释放。
此外,从图中还可以看出,所有的slub缓存都是通过双向链表表头slab_caches串连起来的。宏观上来看,slub可以分成两大类:
1. 一类是建立slub系统所必需的缓存。比如kmem_cache_node和kmem_cache的缓存(不需要kmem_cache_cpu的缓存,因为per cpu的变量有专门的地方分配),以及kmalloc_caches数组。kmalloc_caches这个数组里面的每一个元素对应了一个特定大小的内存,如8字节,16字节等。
2. 第二类是slub用户建立的缓存。比如file, task_struct结构等。
slub中对象的组织方式
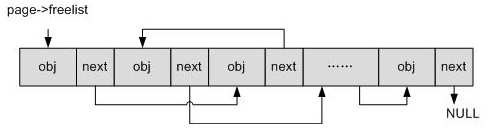
但是,并不是所有的next指针都放在obj对象后面的。事实上,根据next指针存放的位置,对象可以分成内置式和外置式两种。
- 外置式
- 内置式
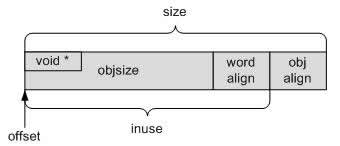
那么怎么选择内置还是外置式呢?很简单,如果对象处于空闲状态时存储空间被使用了,就不能使用内置式指针,而只能用外置式。存储空间被使用的情况有:使用了调试标记位,比如为了调试的需要,把对象存储空间全部初始化为固定的值;还有就是当对象有构造函数时,调用构造函数也可能使对象的存储空间被初始化。
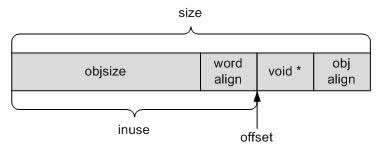
在上面的图中我们看到了objsize,offset,inuse,size这几个变量,事实上这也是kmem_cache结构体中的变量,它们的关系如下:
- objsize是对象的实际大小;
- Inuse = objsize+word align; word align是字节对齐,其目的是为了提高memory存取的效率。对32位系统上,word align是4个字节。也就是说,如果objsize的大小无法被4整除,就要补足;
- offset处存放的是下一个object的地址。对于kmem-128, kmem-256等kmem_cache来说,下一个object的地址都是存放在objsize的起始四个字节处,所以offset为0;但对于UDPV6等动态分配的kmem_cache来,offset = inuse。
- (size-offset)这一部分是为了补足cache L1对齐而填充的字节。目前L1是64字节对齐的。

slub的分配和释放算法
- 向slub申请object
- 从Kmem_cache_cpu中分配一个object给用户;
- 当kmem_cache_cpu中没有空闲的objects时,会将freelist指向的slub放到kmem_cache_node的满链链尾上;然后从kmem_cache_node的partial链表表头中取下一个半满的slub放到kmem_cache_cpu的freelist上,然后从中分配一个object给用户;
- 当kmem_cache_node中没有半满的slub时,需要伙伴系统分配一个新的slub,并将这个slub放到kmem_cache_cpu的freelist上,再从中分配一个object给用户;
- 往slub中释放object
- object属于kmem_cache_cpu的freelist指向的slub。直接把空闲object放到slub中就可以了;
- object属于kmem_cache_node的full链表中的slub。该full slub将会变成partial slub,挂到partial链表的链尾;
- object属于kmem_cache_node的partial链表中的slub。产生这个现象的原因是之前已经有属于该slub的object被释放了。简单的把空闲object放到slub中就可以了。但是,如果slub变成了空的,那么还需要将该slub释放。除非这里的nr_partial(链表长度)小于kmem_cache里面的min_partial。
与slab的主要区别
- slab中维护full,partial和free三个链表。而slub中只维护了partial这一个链表(full链表只在调试时使用);
- 原先的SLAB是为每个CPU提供了array_cache结构来缓存对象。并且对象在array_cache结构中的组织形式跟它在slab中的组织形式是不一样的,每次array_cache中填充的是slab中空闲对象的地址。而slub则都是通过slub结构体来管理对象的,并且直接把整个slub提供给kmem_cache_cpu,从而简化了逻辑。
- slab中用了额外的控制结构来管理slab,slub中去掉了它,通过一些域的复用来自己管理自己;
- 去掉了slab的着色特性;
- 增加了缓存复用的特性。也就是说,当创建新的对象池时,如果发现原先已经创建的某个kmem_cache的size刚好等于或略大于新的size,则新的kmem_cache不会被创建,而是复用这个大小差不多kmem_cache。















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









