







恶毒评论分类报告
一、问题的定义
1.1、项目概述
讨论你关心的事情是很困难的。网络上的虐待和骚扰的威胁意味着许多人停止表达自己,放弃寻求不同的意见。平台很难有效地促进对话,导致许多社区限制或完全关闭用户评论。
对话人工智能团队是Jigsaw和谷歌(都是Alphabet的一部分)共同发起的一个研究项目,目前正致力于开发帮助改善在线对话的工具。一个重点领域是对负面网络行为的研究,比如有毒评论(即粗鲁、无礼或可能让人离开讨论的评论)。到目前为止,他们已经建立了一系列通过透视图API服务的公开可用模型,包括毒性模型。但是,目前的模型仍然存在错误,并且不允许用户选择他们感兴趣的毒性类型(例如,一些平台可能容忍亵渎行为,但对其他类型的毒性内容却不能容忍)。
1.2、问题陈述
在该项目中,我们需要对于网络社区部分恶毒评论进行区分鉴别,需要建立一个可以区分不同类型的言语攻击行为的模型,该赛题一共提供了toxic,severe_toxic,obscene,threat,insult,identity_hate这六种分类标签,需要根据提供的训练数据进行模型训练学习。
该问题是一个文本多分类问题,每一个文本可能存在0个或1个以上的标签。
1.3、评价指标
该项目中,数据存在严重的不平衡,虽然我选择TextCNN模型,但如果使用f1等作评价指标,各个分类的评分差别有可能会比较大,这时导致综合评分无法计算;尽可能将评论正确分类是最重要的,因此在这里我使用ROC-AUC作为评价指标,这也符合项目的要求预测的结果是概率。
ROC-AUC在考虑“真正例率”和“假正例率”:
T
R
P
=
T
P
T
P
+
F
N
TRP=\frac{TP}{TP+FN}
TRP=TP+FNTP,
F
P
R
=
F
P
T
N
+
F
P
FPR=\frac{FP}{TN+FP}
FPR=TN+FPFP;
如果模型是“随机猜测”,那么始终有TRP=FPR,于是AUC=0.5,这是评价度量。
二、分析
2.1、数据的探索
该项目使用的数据是带有标签的用户评论。要做恶毒评论分类,那必须要有评论,这个评论就是用户的评论了,还有就是分类,该分类问题已经确定了六种分类标签,那就不能使用聚类等非监督学习方法了,使用临督学习方法,数据需要带有标签,所以使用带有标签的用户评论数据是最好的。
带有标签的用户评论数据,用户评论很容易获取得到,而标签可以人工上标签,对15w+的数据进行分类标签,还是可以做到的。
train数据共有159571条样本,样本中没有空值,标签1代表是,0代表不是,样本中存在极小数的日文、中文和随机字母或符号。
2.2、探索性可视化
2.2.1、各类别的评论数分布
train_lable = train.drop(["comment_text","id"],axis=1);
train_lable.sum().plot(kind="bar")
plt.show()

如上图所示,属于toxic类别的样本有15k+,而属于threat类别只有几百,数据存在严重的不平衡;
2.2.2、多类别评论数分布
train_lable.sum(axis=1).value_counts().plot(kind="bar")
plt.show()

如上图所示,样本可以是多种分类,甚至可能同时属于6种类别,也有可能不属于作何分类。[1]
从test.csv数据文件中可以看到,绝大多数的用户评论是英文的,个别的评论中带有中文、日文或韩文等其它文字,还是一些是用户随便打的英文字母;如何从文本数据中获取特征,现在已经有很多方法了,而且在运用上已经很成熟,例如bow、tfidf、N-gram,还有很多词向量模型。
2.3、算法和技术
在该项目中,为了提高kaggle上的Private Score,我使用了模型融合的方法对三个模型的结果进行融合,这三个模型分别是tfidf+LR、TextCNN和双向RNN。
2.3.1、 tfidf+LR模型
第一个模型是tfidf+LR。用户评论是带有感情的,想要准确地获取数据的特征,那就要关注文本的上下文,使用tfidf获取文本数据的特征,不但能计算词频,还能计算词在评论中的重要度。该项目和数据有以下特点:1、项目的最终提交结果是评论归为某个分类的的概率;2、属于toxic类别的样本有15k+,而属于threat类别只有几百,数据存在严重的不平衡;3、样本可以是多种分类,甚至可以同时属于6种类别,也有可以不属于作何分类。使用LR模型分别对每个分类进行建模、训练和预测,可以有效地解决以上3个问题。[2]
该模型使用随机梯度下降法最优化参数,train样本数据有15w,使用随机梯度下降法可以有效地提高训练速度。
2.3.2、textCNN模型
第二个模型是crawl-300d-2M.vec + CNN。TextCNN是利用卷积神经网络对文本进行分类的算法,卷积神经网络具有局部特征提取的功能,所以使用CNN可以提取文本中n-gram的关键信息。先来看看textCNN的网络配图:[3]

网络评论一般不会太长,一个评论中词的种类自然也不会太大,这里设置了200,绝大部分的评论数据足以满足这个要求;分词后使用预训练的词向量,将词使用向量的形式表达,同时能过滤掉一些停用词和非英文字符。
卷积层使用了四种过滤器,每种32个过滤器,为了提取文本中n-gram的关键信息,过滤器的大小分别是(1,200)、(2,200)、(3,200)、(5,200)。训练数据总共约有15w条,为了提高训练速度SpatialDropout1D设置了0.4,多次运行证明0.4是个很好的选择。
最大池化层降低计算复杂度,防止过拟合;Flatten后只剩下128个参数了,全连接层输出六个分类的概率,所以可以不要Dropout层,最后解决项目问题。
模型的优化器选择了Adam优化器,6个类别的样本量相差较大,使用Adam做到参数微调。
2.3.3、textRNN模型
第三个模型是glove.840B.300d.txt + 双向RNN。RNN是处理序列数据的神经网络,文本数据就是序列数据,前面的LR和textCNN模型都是将词、字符或者词语作为特征的,但与特征的序列无关,我们知道“我看天”和“天看我”是不一样的意思,但在LR和textCNN中是一样的,而RNN就能处理这种情况,将文本的序列提取到特征中。下面是GRU和RNN的网络结构图:[4]


数据的处理和textCNN一样,唯一不同的是使用了glove.840B.300d.txt作为预训练的词向量。使用GRU提取了评论数据的序列特征,同时将词的维度降到了128,这里使用双向的RNN将记录评论前向和反向序列的特征,然后使用过滤器大小为3的一维过滤器对特征进行卷积,对卷积结果进行了平均池化层和最大池化层,将平均池化层和最大池化层的结果连接在一起,最后使用全连接层得出6个分类结果。该模型也是使用Adam作为优化器。
2.4、基准模型
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(C=1.0,solver=‘sag’)
使用该模型作为基准模型,该模型下的基准阈值为0.9805 。该模型是在使用网络搜索得出的最佳模型,网络搜索参数如下:
{‘solver’:[‘liblinear’,‘sag’,‘saga’],‘C’:[0.1, 0.5,1.0]}。
最佳模型的参数C=1.0,solver=‘sag’,模型在kaggle的Private Score为0.9805。
三、方法
3.1、数据预处理
该项目的输入空间是文本数据,数据中以英文为主,少数的其它文字以及字符,一般在做NLP都需要对文本数据做以下处理:1、空值处理;2、大小写统一;3、非英文字符处理;4、去掉停用词;5、拼写纠错等。在该项目的数据中没有空值,所以就不需要做空值处理了;大小写字母统一成小写字母,在tfidf和Tokenizer都可以做到。
对于tfidf+LR模型,需要对变量进行tfidf特征变换,特征空间应该是test.csv和train.csv中comment_text的总和;train数据只有159571个,样本量较大,评论内容以英文为主,英文中大多数单个单词就能表明其意思,所以我们只需要单个单词的TF-IDF即可,这样也能减少训练时间;在网络中,经常有些网民会使用额外的字符来代表某个单词或意思,所以我们还要获取字符的TF-IDF,并将该两个TF-IDF合并,当作当前样本的特征。在不断的验证中,证明了添加字符的TF-IDF能明显地提高模型的AUC评分。
对于TextCNN和RNN,会使用到预训练的词向量,这样就可以过滤掉其它字符和去掉停用词了;网络评论中经常有用户会拼写错误,但同时也有一些单词简写,所以拼写纠错不作处理了。因此只要对评论数据进行分词,然后使用预训练的词向量对评论中的词进行向量化。
3.2、执行过程
3.2.1、LR执行过程
在上述数据探索可视化中,我们知道样本数据在各个分类中的样本量存在着严重的不平衡,同时评论与标签是一对多的关系,所以在使用LR模型时,我们需要对各分类单独进行建模、训练和预测。
将评论和标签切分开来;对于train数据,切分开评论和标签,标签赋值给train_targets,对评论进行tfidf特征获取并赋值给train_feature;对test数据进行tfidf特征获取并赋值给test_feature;记录所有标签到数组class_names,最后分别对各标签进行建模训练,并将预测结果保存到DataFrame中:
Input:train_feature,train_targets,test_feature
Output:submission.csv
For class_name in class_names:
train_teature = train_targets[class_name]
model = LogisticRegression()
model.fit(train_feature, train_teature)
submission[class_name] = model.predict_proba(test_features)
submission.to_csv(“submission.csv”)
3.2.2、textCNN执行过程
在上述的算法与技术2.3.2中已经给出了CNN的网络图,执行过程就是分词、词向量化、模型构造、训练、预测和保存结果到文件中。
分词,使用Tokenizer分词器,拟合了训练集和测试集和数据后,分别sequences训练集和测试集数据,最后统一评论长度。
词向量化,使用预训练的词向量将词向量化,这里我选择了crawl-300d-2M.vec词向量。
模型构造,逻辑就像上面CNN网络图的那样,总共四层,分别是Conv2D层、MaxPool2D层、Flatten层和Dense层。
3.2.3、RNN执行过程
在上述的算法与技术2.3.3中已经给出了GRU和RNN的网络图,执行过程跟textCNN一样,但预训练词向量使用了glove.840B.300d.txt。
模型构造上,使用GRU提取序列特征并降低维度,然后使用双向RNN保存双向的序列特征,接着是Conv1D层、GlobalAveragePooling1D层、GlobalMaxPooling1D层、concatenate层和Dense层。
3.3、完善
3.3.1、完善LR模型
初始模型是默认参数的LR模型,参数C=1.0,solver=‘liblinear’,模型的auc平均评分约0.9832;使用网络搜索得出最佳模型,网络搜索参数如下:
{‘solver’:[‘liblinear’,‘sag’,‘saga’],‘C’:[0.1, 0.5,1.0]}。
最佳模型的参数C=1.0,solver=‘sag’,模型在kaggle的Private Score为0.9805。
3.3.2、完善textCNN模型
在上述CNN网络图的基础上,调整一些参数,有SpatialDropout1D的rate参数、Conv2D中提取n-gram关键信息、Dropout的rate参数,以及拟合数据时batch_size、epochs参数。
SpatialDropout1D的rate参数在0.2与0.4之间选择,rate参数不能太大,否则数据损失过多,容易出现欠拟合;rate参数也不能太小,否则容易出现过拟合,同时会导致训练速度过慢;在多次运行结果后,选择了0.4,不但速度提高了,AUC评分也比0.2的高。
n-gram选取,1-gram是必须的,这是单个词的特征提取;2-gram,提取两个词之间的关联信息,但2-gram终是太小,需要3-gram和5-gram来提高评论的特征提取。
Dropout的rate参数在0.1和0中选择,Flatten后有128个参数,选择0.1可以有效地防止过拟合和提高速度。
拟合数据时,训练集中threat类的样本大约有500个,总样本数有15w,150000/500=300,为了让每个batch尽可能地都有threat类,所以batch_size设置了512,同时train_size大小设置为0.96;epochs的值设置了3,因为在epochs=2时,模型已经比较好了,epochs=3时模型提高的不大,为了减少模型的训练时间,设置epochs为3是最好的。
该模型在kaggle上Private Score为0.9807。
3.3.3、完善RNN模型
RNN模型的网络结构图在2.3.3中已经给出,参数调整过程跟textCNN差不多,都是经过多次修改运行后根据AUC评分来选择的。GRU的输出维度选择了128;Conv1D层过滤器的大小选择了3,过滤器数量64。
该模型在kaggle上Private Score为0.9831。
四、结果
4.1、模型的评价与验证
该项目中,数据存在严重的不平衡,如果使用f1等作评价指标,各个分类的评分差别有可能会比较大,这时导致综合评分无法计算;尽可能将评论正确分类是最重要的,因此在这里我使用ROC-AUC作为评价指标,这也符合项目的要求预测的结果是概率。
ROC-AUC在考虑“真正例率”和“假正例率”:,;
如果模型是“随机猜测”,那么始终有TRP=FPR,于是AUC=0.5,这是评价度量。[3]
4.1.1、LR模型评价与验证
使用3折交叉验证进行模型选择,这里使用5折、10折也是可以的,但是3折已经能够获取到0.98以上的评分了,为了能够减少验证时间,使用3折无疑是最好的。最终模型的参数C=1.0,solver=‘sag’,该模型的Private Score为0.9805,说明该模型稳健可靠、合理;train数据共有159571条样本,样本量比较大,使用sag进行模型优化,这很合理。

4.1.2、textCNN模型评价与验证
在训练集中拆分出0.04作为验证集,验证集不宜过大,否则数据无法允分得到训练,也不能过小,为尽量确保验证集中各分类的类别都有,0.4是最好的,因为500/150000=0.033 。该模型的Private Score为0.9807,评分超过了评价度量,说明该模型稳健可靠并且合理。

4.1.3、RNN模型评价与验证
RNN模型在kaggle的Private Score为0.9831,评分远超过了评价度量0.9805,该模型也是可靠合理的。

4.2、合理性分析
该项目的样本数据中输入空间只[‘comment_text’],使用tfidf和预训练词向量化都是合理的。输出空间有 [‘toxic’, ‘severe_toxic’, ‘obscene’, ‘threat’, ‘insult’, ‘identity_hate’],对于LR模型,分别对各个分类进行单独建模、训练和预测,而textCNN和RNN可以统一训练,然后中输出6个分类的概率。该模型最终是对数据进行各类别的预测,预测结果是概率,满足项目的需求,同时也能通过概率来判断评论是否归属某个分类,如果在某个分类上,预测的概率大于0.5,则代表该评论归属该分类,概率越大归属性越大。
最终的提交结果是LR、textCNN、RNN三个模型预测结果的加权平均,模型(LR,textCNN,RNN)对应的权重是(3,2,5),得到的结果在kaggle上的Private Score是0.9853,比单模型高出很多,Public Score是0.9857,这两个评分相差不大,说明了该结果是合理的,同时也解决了问题。

五、项目结论
5.1、结果可视化
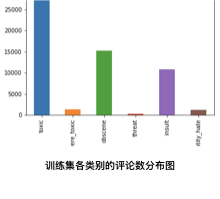
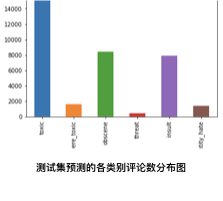
如上图,是训练集各类别的评论数分布图和测试集预测的各类别评论数分布图,可以看出两个分布图相差不大,所以最优模型预测的结果可靠性比较大。接下来看看详情的数据,在训练集数据中,各类别的评论数占比如下:

最优模型预测的测试集结果中,各类别的评论数占比如下:

从上面的数据上对比可以看出,最优模型预测的结果跟样本数据的比较确实相差不大,所以得出这个结果是合理的。
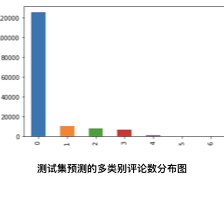
再来看看多类的分布:
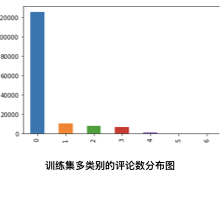
在训练集数据中,多类别的评论数占比如下:

最优模型预测的测试集结果中,多类别的评论数占比如下:

从上面的分布图和数据表可以看出,预测的多类别比例也是正常的。
5.2、对项目的思考
恶毒评论分类,该项目想在在kaggle上取得好成绩,使用单模型是远远不够了。之前一直都是使用单模型去提交,但在Private Score的成绩从来没有达到过0.0984,后来使用了加权平均,在三个模型的加权平均下终于训练出了0.9853的分数,模型融合的方法有很多,有Boosting、AdaBoost、Stacking、平均法、加权平均法和投票法等等,这里我想对三个模型的结果进行融合,而平均法、加权平均法和投票法中,加权平均法的提升效果相对较好,所以最后选择了加权平均法。
对于单模型,该项目最大的问题是如何提取评论中的特征和模型构造,然后是模型的选择与调参,我选择的模型有LR、TextCNN和RNN。
首先是tfidf_LR模型。该项目的样本数据拿只有一个输入变量,和六个输出变量,还有一个id自变量。输入变量是comment_text,文本分析的方法有几种,如词袋模型、TF-IDF模型、SVD、NNLM、word2vec、GloVe等等,我选择TF-IDF模型,原因很简单,因为我只熟悉词袋模型和TF-IDF模型,但词袋模型只是计算单词出现的频数,显然特征提取过于简单,会遗漏语意,对于评论情感分类明显不够好,所以我选择了TF-IDF模型。TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF(Term Frequency,词频),词频高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。经过数据简单的分析,数据中不存在空值或异常值,所以不需要对数据进行预处理,
因此直接对文本进行TF-IDF特征提取,在训练TF-IDF模型时一定要使用训练集和测试集中comment_text数据合并后的数据进行训练,因为如果只使用训练集的数据进行训练TF-IDF模型,那在测试集中提取训练集没有的特征时就会报错。评论内容大部分都是英文,所以stop_words=‘english’,然后是ngram_range的选择了,一开始的我设置了(1, 4),但是除了时间长外,对模型的优化并没有什么作用,所以最后选择了(1, 4),这个很好理解,因为英文中大多数单个单词就能表明其意思了,不像中文那样,词语跟词可能意思就差了很多。在网络中,经常有些网民会使用额外的字符来代表某个单词或意思,所以我们还要获取字符的TF-IDF,并将该两个TF-IDF合并,当作当前样本的特征。在不断的验证中,证明了添加字符的TF-IDF能明显地提高模型的AUC评分。然后是模型的选择,分类可以使用LR、朴素贝叶斯、决策树、SVM、深度神经网络等,一开始我是想使用SVM的,但是训练时间太长了,然后我改用LR模型。最后就是调参了,在决定几个可能需要调的参数后,我使用网络搜索进行参数选择,最后的模型只比基准模型评分高0.01%,但也达到了我的期望,同时使用该模型作为基准模型。使用TF-IDF特征提取时,只使用了训练集和测试集的数据,训练的LR模型也是根据TF-IDF提取的特征进行训练的,所以该模型不能在通用的场景下解决这些类型的问题。
然后是textCNN模型。文本分析的方法有几种,如词袋模型、词向量模型、TF-IDF模型、SVD、NNLM、word2vec、GloVe等等,我选择词向量模型,TextCNN配合词向量使用可以很好地提取特征,在选择n-gram中,1-gram是必须的,这是单个词的特征提取;2-gram,提取两个词之间的关联信息,但2-gram终是太小,需要3-gram和5-gram来提高评论的特征提取。分词时会对英文统一小写,使用预训练的词向量可以过滤掉非英文字符和停用词,而评论数据中没有NaN值,所以在分词前不需要做数据处理,分词的词空间是训练集和测试集中comment_text数据合并后的总和,因为如果只使用训练集的数据进行训练Tokenizer分词器,那在测试集中提取训练集没有的特征时就会报错。分词后需要统一评论sequences化的长度,为后面训练CNN做准备,这里选择了200作为sequences化的长度,因为网络评论不会太长,那词的类别也不会很多。然后是卷积神经网络的构造,上面已经介绍过CNN网络结构,该网络结构很简单,一层卷积层、一层最大池化层、最后是全连接层,评论数据本来就不大,少层数不但能提高训练速度,同时也能得出很好的结果。为了防止过拟合,也使用了随机丢弃,经过不断地去调参,最后得到了最优的结果0.9894,比基准模型评分0.9853高,达到了我的期望。该模型只使用了训练集和测试集的数据,训练的卷积神经网络也是根据训练集和测试集获得的词向量进行训练的,所以该的模型不能在通用的场景下解决这些类型的问题。
最后是RNN模型,相对于textCNN来说,RNN的优点是可以提取序列特征,但因为该模型也是只使用了训练集和测试集的词向量进行训练,所以该模型也不能在通用的场景下解决这些类型的问题。
最终的提交结果是三个模型的加权平均,以上三个模型都不能解决通用场景下这些类型的问题,使用了加权平均后自然也不能解决。
5.3、需要作出的改进
该最终结果是在项目提供的数据下得到的,所以可以通过不断提交,使用额外的数据去测试模型,然后不参尝试各参数的组合,最后得到更好的模型。
如果以该结果作为新的基准阀值,我认为还能有更好的解决方法,因为有很多参数还有调整的空间,其它的融合方法可能可以做到更好,而且可能还存在更好的模型适合这个项目。
参考文献
[1]https://github.com/udacity/cn-machine-learning/tree/master/toxic-comment-classification
[2]https://www.kaggle.com/tunguz/logistic-regression-with-words-and-char-n-grams
[3]https://www.kaggle.com/yekenot/textcnn-2d-convolution
[4]https://www.kaggle.com/eashish/bidirectional-gru-with-convolution
[5]周志华《机器学习》















 1822
1822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









