







维基百科对深度学习的精确定义:“一类通过多层非线性变换对高复杂性数据建模算法的合集”。深度学习两个重要的特性:多层和非线性。
一.深度学习与深层神经网络
二.损失函数的定义
三.反向传播算法及实现
四.神经网络的优化
一.深度学习与深层神经网络
1.线性变换
线性模型的最大特点是任意线性模型的组合仍是线性模型。y=∑wx+b。
线性模型的局限性:能够解决的问题是有限的。

2.激活函数实现去线性化
将每一个神经元(神经网络中的节点)的输出通过一个非线性函数(即激活函数),则整个神经网络模型不再是线性。

神经网络结构加上激活函数和偏置项之后的前向传播算法的数学定义:

改变有二:(1)新公式增加了偏置项(bias);
(2)每个节点取值不再是单纯的加权和,有一个非线性变换。
下图是几种常用的非线性激活函数。

这些激活函数的函数图像都不是一条直线,所以通过这些激活函数,每一个节点不再是线性变换,因此整个神经网络模型不再是线性。
目前TensorFlow提供了7种不同的非线性激活函数,tf.nn.relu、tf.sigmoid和tf.tanh是常用的几个。
3.多层网络解决异或运算(多层变换)
神经网络的理论模型由Warren McCulloch和Walter Pitts在1943年首次提出,并在1958年由Frank Rosenblatt提出了感知机(perceptron)模型,从数学上完成了对神经网络的精确建模。感知机可以简单理解为单层神经网络(图4-5所示),感知机先将输入进行加权和,再通过激活函数最后得到输出,该结构是一个没有隐藏层的神经网络。在1969年,Marvin Minsky和Seymour Papert在Perceptrons:An Introduction to Computational Geometry一书种提到感知机无法模拟异或运算。
二.损失函数定义
神经网络模型的效果以及优化的目标是通过损失函数(loss function)来定义的。
1.分类问题和回归问题的经典损失函数
分类问题希望解决的是将不同的样本分到事先定义好的类别中。比如判断一个零件是否合格就是一个二分类问题。
神经网络解决多分类问题最常用的方法是设置n个输出节点,其中n为类别的个数。对于每一个样例,神经网络可以得到的一个n维数组作为输出结果,数组中的每一个维度(即输出节点)对应一个类别。
如何判断一个输出向量和期望的向量有多接近?——交叉熵(cross entropy)。
交叉熵刻画了两个概率分布之间的距离,它是分类问题中使用比较广的一种损失函数。
1.1交叉熵

即任意事件发生的概率都在0和1之间,且总有某一个事件发生(概率和为1)。
如何将前向传播算法得到的结果变成概率分布?——Softmax回归。
1.2 Softmax回归
Softmax回归本身可以作为一个学习算法来优化分类结果,但在TensorFlow中,Softmax回归的参数被去掉了,它只是一层额外的处理层,将神经网络的输出变成一个概率分布。


当交叉熵作为神经网络得损失函数时,p代表的是正确答案,q代表的是预测值,交叉熵刻画的是两个概率分布的距离,也就是说交叉熵值越小,两个概率分布越接近。
TensorFlow实现交叉熵:
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,le-10,1.0)))tf.clip_by_value函数的实现案例:(将一个张量中的数值限制在一个范围内)
import tensorflow as tf
v = tf.constant([[1.0,2.0,3.0],[4.0,5.0,6.0]])
v1 = tf.clip_by_value(v,2.5,4.5)
with tf.Session() as sess:
#print(sess.run(v1)) #都可运行
print(v1.eval(session=sess))tf.log函数的实现案例:(对张量中所有元素依次求对数)
import tensorflow as tf
v = tf.constant([1.0,2.0,3.0])
v2 = tf.log(v)
with tf.Session() as sess:
#print(sess.run(v2))
print(v2.eval(session=sess))import tensorflow as tf
v1 = tf.constant([[1.0,2.0],[3.0,4.0]])
v2 = tf.constant([[5.0,6.0],[7.0,8.0]])
v3 = v1 * v2 #元素直接相乘
v4 = tf.matmul(v1,v2) #矩阵乘法
with tf.Session() as sess:
print(v3.eval(session=sess))
print(v4.eval(session=sess))import tensorflow as tf
v = tf.constant([[1.0,2.0,3.0],[4.0,5.0,6.0]])
v1 = tf.reduce_mean(v)
with tf.Session() as sess:
print(v1.eval(session=sess))cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y,y_)1.3回归问题
回归问题解决的是对具体数值的预测。如房价预测、销量预测。这些问题需要预测的不是一个事先定义好的类别,而是一个任意实数。
解决回归问题的神经网络一般只有一个输出节点,这个节点的输出值就是预测值。
对于回归问题,最常用的损失函数是均方误差(MSE,mean squared error)。定义如下:

mse = tf.reduce_mean(tf.square(y_-y))2.自定义损失函数
以预测商品销量问题为例。在预测商品销量时,如果预测多了(预测值比真实销量大),商家损失的是生产商品的成本;如果预测少了,损失的是商品的利润。下面公式给出了一个当预测多于真实值和预测少于真实值时有不同损失系数的损失函数:

通过对这个自定义损失函数的优化,模型提供的预测值更有可能最大化收益。
TensorFlow实现上述损失函数:
loss = tf.reduce_sum(tf.select(tf.greater(v1,v2),(v1-v2)*a,(v2-v1)*b))import tensorflow as tf
v1 = tf.constant([1.0,2.0,3.0,4.0])
v2 = tf.constant([4.0,3.0,2.0,1.0])
sess = tf.InteractiveSession()
v3 = tf.greater(v1,v2)
v4 = tf.where(v3,v1,v2) #输tf.select会报错,查阅了下,用tf.where替代
with tf.Session() as sess:
print(sess.run(v3))
print(sess.run(v4))
import tensorflow as tf
from numpy.random import RandomState
batch_size = 8
#两个输入节点 回归问题一般只有一个输出节点
x = tf.placeholder(tf.float32,shape=(None,2),name='x-input')
y_ = tf.placeholder(tf.float32,shape=(None,1),name='y-input')
#定义一个单层神经网络前向传播过程,这里是简单加权和
w1 = tf.Variable(tf.random_normal([2,1],stddev=1,seed=1))
y = tf.matmul(x,w1)
#定义预测多了和预测少了的成本
loss_less = 10
loss_more = 1
loss = tf.reduce_mean(tf.where(tf.greater(y,y_),
(y-y_) * loss_more,
(y-y_) * loss_less))
train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
#随机数生成一个模拟数据集
rdm = RandomState(1)
dataset_size = 128
X = rdm.rand(dataset_size,2)
#设置回归的正确值为两个输入的和加上一个随机量。之所以要加上一个随机量是为了
#加入不可预测的噪音,否则不同损失函数的意义就不大了,因为不同损失函数都会在能
#完全预测正确的时候最低。一般来说噪音为一个均值为0的小量,所以这里的噪音设置为
#-0.05~0.05的随机数
Y = [[x1 + x2 +rdm.rand()/10.0-0.05] for (x1,x2) in X]
#训练神经网络
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 5000
for i in range(STEPS):
start = (i * batch_size) % dataset_size
end = min(start+batch_size, dataset_size)
sess.run(train_step,
feed_dict={x:X[start:end],y_:Y[start:end]})
print(sess.run(w1))上述代码得到的预测函数是x1+x2,这比1.02x1+1.04x2大,因为在损失函数中指定预测少了的损失更大(loss_less>loss_more)。若将loss_less的值调整为1,loss_more的值调整为10,模型会更加偏向于预测少一点。而若使用均方误差作为损失函数,会尽量让预测值离标准答案更近。
该案例表明,对于相同的神经网络,不同的损失函数会对训练得到的模型产生重要影响。
三.神经网络优化算法(反向传播算法backpropagation和梯度下降算法gradient decent)
1.梯度下降算法优化参数取值的过程



2.梯度下降算法的缺点和解决方案
四.神经网络的进一步优化
1.学习率
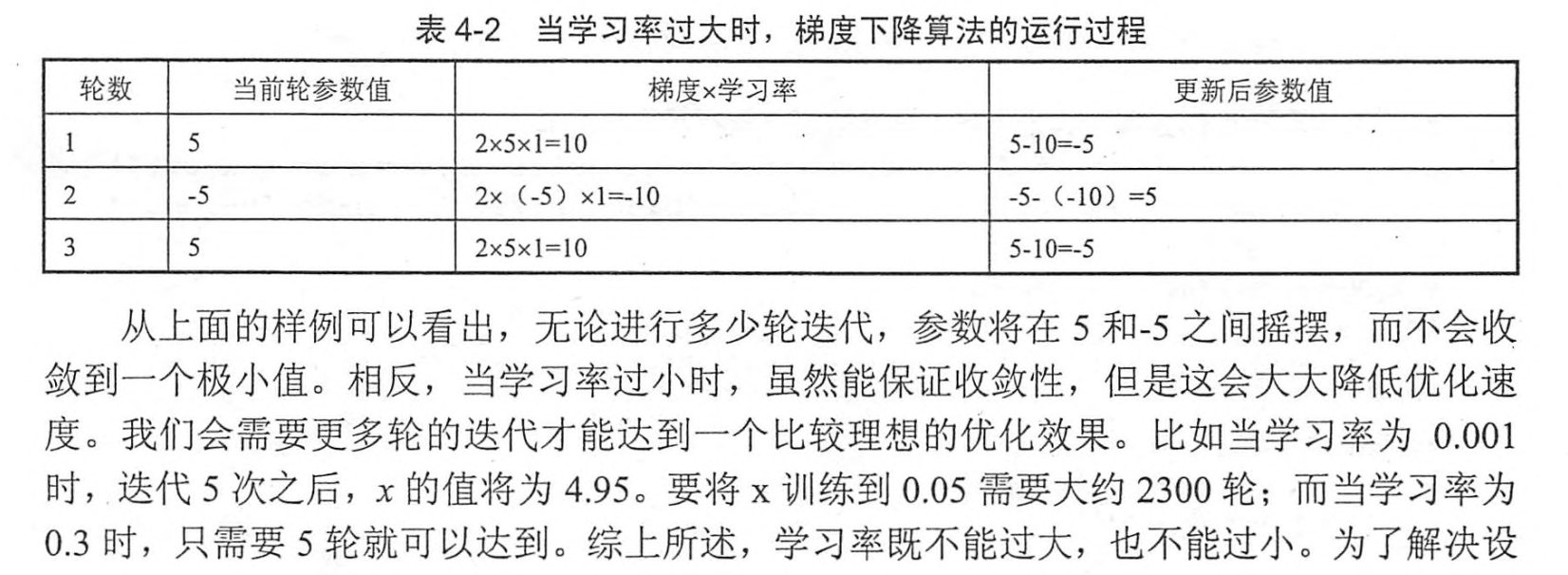
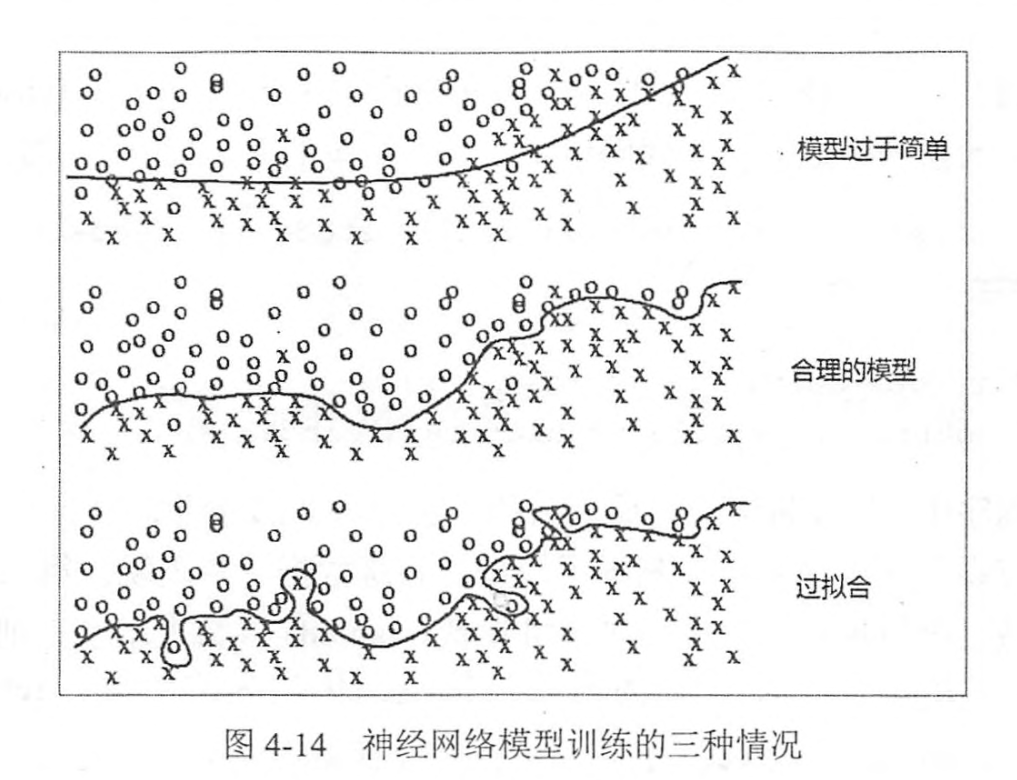
2.过拟合
















 2818
2818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









