







 本文介绍了TensorFlow中神经网络的激活函数,如relu、sigmoid和tanh,以及分类和回归任务的损失函数,如交叉熵和均方误差。此外,讨论了优化算法,包括梯度下降、随机梯度下降和批量梯度下降,并提到了指数衰减学习率。最后,探讨了正则化技术,如L1和L2正则化,以防止过拟合。
本文介绍了TensorFlow中神经网络的激活函数,如relu、sigmoid和tanh,以及分类和回归任务的损失函数,如交叉熵和均方误差。此外,讨论了优化算法,包括梯度下降、随机梯度下降和批量梯度下降,并提到了指数衰减学习率。最后,探讨了正则化技术,如L1和L2正则化,以防止过拟合。
本文是TensorFlow学习笔记的第二部分,这部分主要介绍神经网络中的激活函数、损失函数、优化算法和正则项。
1.激活函数
激活函数可以将线性变换转换为非线性变换,神经元可以表示为:z=f(wx+b),其中wx+b得到的是一个对输入x的一个线性变换,映射函数f就是激活函数,f可以将wx+b的结果映射到一个指定范围内的值,从而达到非线性变换的功能。加入激活函数之后的神经元可以学习更为复杂的特征。
目前TensorFlow提供了7种不同的非线性激活函数,比较常用的激活函数有:tf.nn.relu、tf.sigmoid和tf.tanh三种,这三种激活函数的图像如下所示:
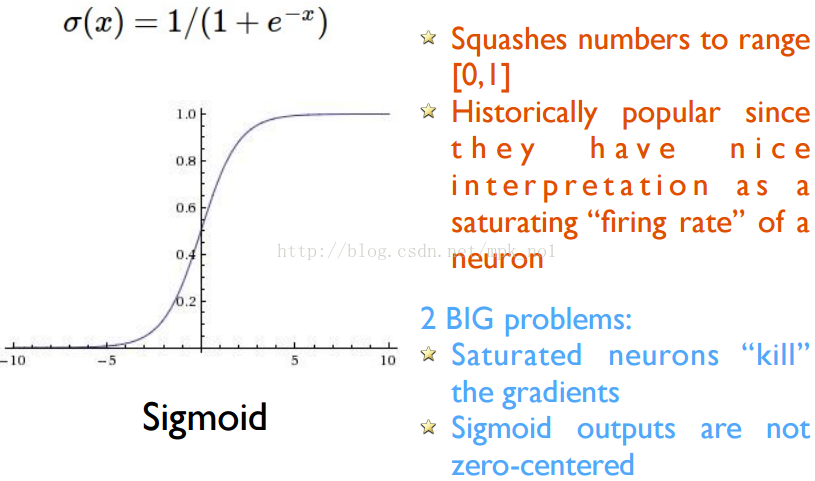
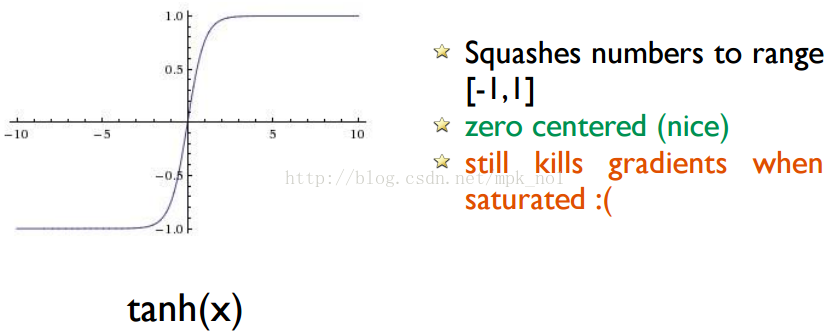

2.损失函数
常见的用于分类的损失函数有:交叉熵
交叉熵的定义公式为: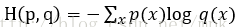
交叉熵刻画的是两个概率分布的距离,也就是说交叉熵值越小,两个概率分布越接近。
TensorFlow中交叉熵的可以用以下代码实现:
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
其中,y_代表正确结果,y代表预测结果。通过tf.clip_by_value函数可以将一个张量中的数值限制在一个范围之内,这样可以避免一些运算错误(比如log0是无效的)。tf.log函数是逐元素计算log值,*代表两个矩阵相乘,是元素之间的直接相乘,不是矩阵乘法。
常见的用于回归的损失函数有:均方误差(MSE)
均方误差的定义公式为:
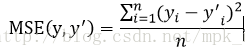
TensorFlow中实现军方无产的代码为:
mse = tf.reduce_me
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









