






import pandas as pd
#把字典转换为dataFrame
data={"name":["Jaide","Aaron","Adam"],"Age":[12,34,98]}
dataFrame=pd.DataFrame(data)
print(dataFrame)

#把数据写入Excel
dataFrame.to_excel("test.xlsx",index=False)

按列或者行赛选数据
print(dataFrame["name"].tolist())

打印第第一行第一列
print(dataFrame["name"][0])


dataFrame.index #访问索引,也就是行号
dataFrame.columns #访问列名
#取前面多少行,默认前5行,head里面写10,就是前10行
print(data.head()) #取后边多少行,默认后5行,tail里面写10,就是后10行 print(data.tail())
#展现Excel有多少行,多少列 print(data.info())
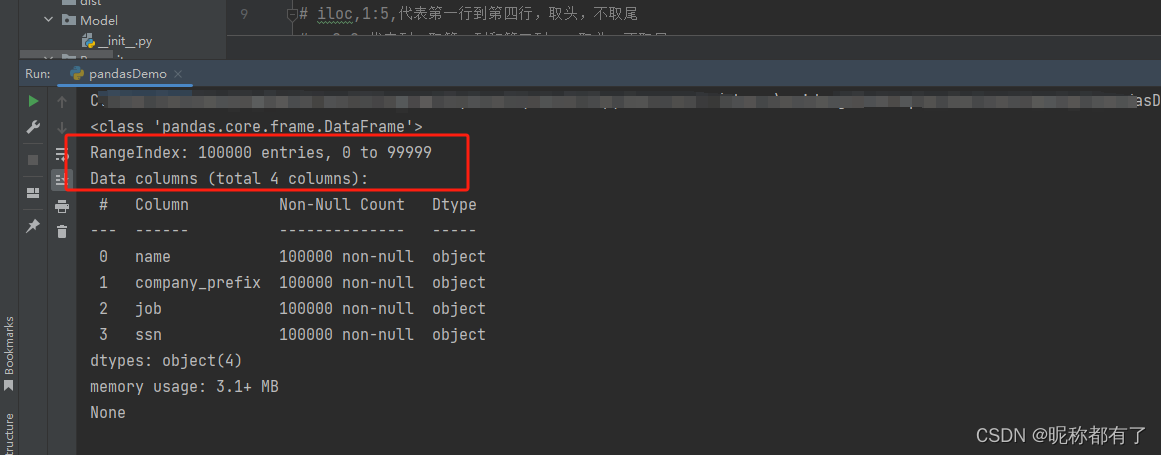
print(data.describe())
describe:describe方法返回有关DataFrame中数字数据的一些有用统计信息,例如均值,标准偏差,最大值和最小值以及一些百分位数。

x = data.at[0, 'company_prefix'],获取第一行,列名为:company_prefix的值
df.at和df.iat是pandas库中用于访问和修改DataFrame中特定元素的两种方法。
df.at是通过指定行和列的标签来访问和修改元素的方法。它的用法是df.at[row_label, column_label]。例如,要访问DataFrame中第3行第2列的元素,可以使用df.at[2, 'column_name']。
df.iat是通过指定行和列的索引来访问和修改元素的方法。它的用法是df.iat[row_index, column_index]。例如,要访问DataFrame中第3行第2列的元素,可以使用df.iat[2, 1]。
需要注意的是,df.at和df.iat方法都是用于访问和修改单个元素的,而不适用于访问和修改多个元素的情况。如果想要操作多个元素,可以使用其他方法,如切片操作df.loc或df.iloc。
df.T #转置

print(dataFrame.loc[0:2]),读取第一行到第三行 print(dataFrame.iloc[0:2]),读取第一行和第二行,左开右闭合
DataFrame的索引index(行标签 row lable)。
DataFrame的索引是一系列标识每一行的标签。标签可以是整数、字符串或任何其他可散列类型。索引用于基于标签的访问和对齐,可以使用此属性进行访问或修改。
loc是按照行进行检索(ioc可以填写行的名称和索引,),iloc只是是按照index进行检索。
注意:
dataFrame.index=list('abc'),如果设置了行名称,
dataFrame.loc只能按照行进行检索,不能写行的下标,
dataFrame.iloc可以使用索引
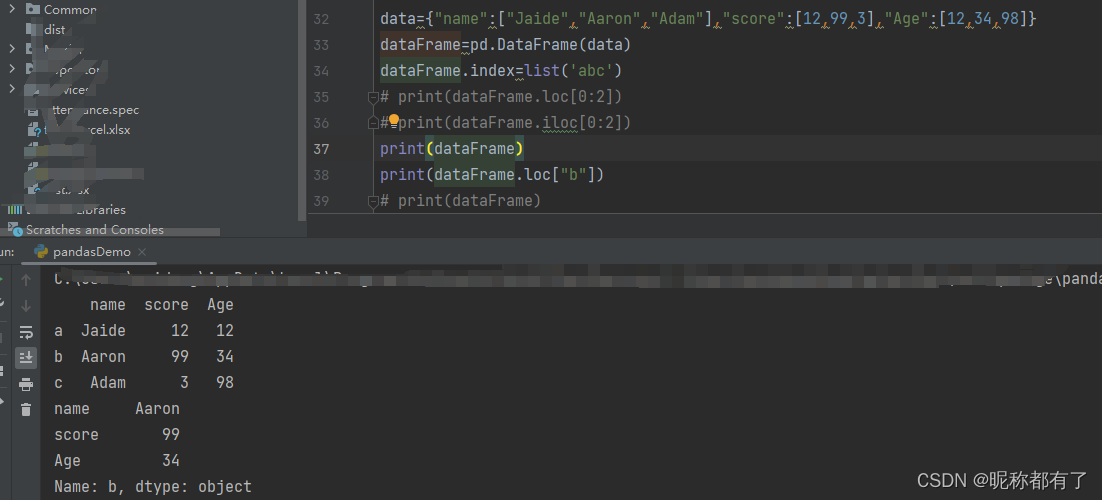
print(dataFrame.iloc[0:2]) #实际读取第一行和第二行,0可以省略

print(dataFrame.iloc[:,1:]) #读取第一列之后的所有行数据

print(dataFrame.iloc[0:1,1:]) #读取第一列之后的第一行数据

总结 dataFrame.iloc[索引,列]) 第一个参数代表取多少行,第二个参数取那些列
普通这样是读取行列,df['列']['行标签']
Syntax: dataframe.max(axis)
where,
- axis=0 specifies column
-
data={"name":["Jaide","Aaron","Adam"],"score":[12,99,3],"Age":[12,34,98]} dataFrame=pd.DataFrame(data) - #获取每一列的最大值,如果不写列名称
-
print(dataFrame.max(axis=0))
- 获取指定列的最大值
- dataframe[‘column_name’].max()

-
dataFrame["Age"].max() 输出:98 ,输出最da的年龄
-
print(dataFrame["Age"].min()) 输出:12 ,输出最xiao的年龄 print(dataFrame["Age"].mean()) 输出:12 ,输出最平均值的年龄














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









