






为了帮助入门的小伙伴快速上手pandas操作Excel,写了一篇文章进行记录常用操作,以下是一些常用的pandas处理Excel文件的方法:
- 读取Excel文件
import pandas as pd
data = pd.read_excel('file.xlsx')
- 写入Excel文件
data.to_excel('new_file.xlsx', index=False)
- 选择特定的列
selected_data = data[['column1', 'column2']]
#选择单列也可以这样
selected_data = data[['column1']]
selected_data = data['column1']
data.iloc[:,1] #通过下标
data.locdf.loc[:,"NAME"] #通过列明- 原始的exdel
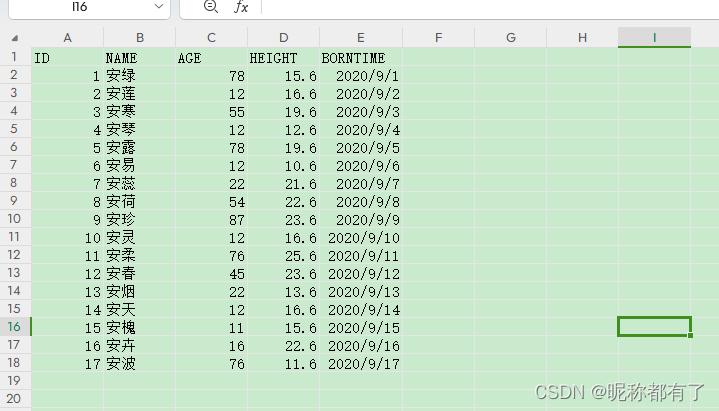
通过下面的对面添加了一个新列,然后进行数据输出
import numpy as np
df=pd.read_excel('20231114.xlsx')
# print(r.head(5))
# r["hoppy"]
hoppys=['pingpang','basketball','football','badminton','baseball']
newhoppy=[]
for r in (range(17)):
# print(random.choice(hoppys))
newhoppy.append(random.choice(hoppys))
df['hoppy']=newhoppy
print(df.head(100))
- 过滤数据,过滤出来身高大于20的数据
filterdata=df[df["HEIGHT"]>20]

print(df[(df.NAME.str.contains('珍'))&(df["HEIGHT"]>21)]),复合条件筛选

print(df[df['NAME'].isin(['安荷', '安卉'])]) 在指定的范围筛选

data['new_column'] = data['column1'] + data['column2']
- 删除列
#inplace=true 不创建新的对象,直接对原始对象进行修改
data.drop(['column1', 'column2'], axis=1, inplace=True)
#下面两种方式都可以删除列
print(df.drop(["hoppy","AGE"],axis="columns"))
print(df.drop(["hoppy","AGE"],axis=1))- 合并Excel文件
data1 = pd.read_excel('file1.xlsx')
data2 = pd.read_excel('file2.xlsx')
merged_data = pd.concat([data1, data2])













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









