







背景和需求
整合Tick数据是PA交易的回测与实盘基本需求。多数交易回测框架往往缺乏对大规模Tick数据直接而全面的支持。Tick数据因其体量庞大(例如,某棕榈油主力合约四年间的数据达8GB)为结合价格趋势与PA分析带来挑战,凸显了实时动态数据源的重要性。实时数据不仅能应对数据规模问题,还能减少因数据时序差异引发的回测或实盘错误,确保分析准确性。
这里提及的8GB棕榈油合约Tick数据已转存MySQL数据库格式,并在文末以笔者整理后的SQL导出文件形式提供下载,数据仅供研究与测试,勿用作商业用途。
概述
在探索Backtrader时,我注意到将其与Tick数据集成至回测流程颇为简便,故撰写系列笔记以记录并分享这一过程。本笔记基于当前版本Backtrader编写。未来或许有更优框架或Backtrader自身改进Tick数据处理方式,目前而言,本系列文章提供的Tick数据与K线结合的免费解决方案,是非常易于上手的免费选择之一。
本系列《BackTrader如何使用实时tick数据和蜡烛图》预计将分成上中下三篇:
- 上篇:本文,较水,对背景和DataFeed做出介绍,同时介绍tick数据如何读取到回测策略流程中。完整读完后可以做到将tick数据加入到BackTrader策略中。
- 中篇:待完成,主要介绍如何将tick结合KBar同时读取到回测策略流程中。
- 下篇:待完成,主要介绍跨周期回测,可看做Multiple Timeframes结合tick的实操记录。
《BackTrader如何使用实时tick数据和蜡烛图》系列小文,属于PA交易和量化交易文集。PA交易和量化交易文集将会主要专注于低频Python实现。对于一些高频部分目前暂不涉及。鉴于高频本身对于网络和硬件要求较高,多数朋友(包括笔者)可能都没有交易所托管或者购买高性能计算的计划,并且目前笔者也没有转向高频C++的计划和需求。
PS:题外话:笔者十多年艹C艹经验都懒得用C艹。
笔者交易市场主要为国内商品期货市场,个人平时主要做农产品基本面分析,后续计划考虑进行对包括油厂、美农、拉尼娜等各类数据进行一些因子挖掘工作。个人精力有限,有相关爱好的朋友有缘可以寻找合作机会。
BackTrader
之所以选择BackTrade主要原因有以下几点:
- 相比于pyAlgoTrade:目前Gabriel Becedillas大神已经全面转到 basana 开发,不再更新pyAlgoTrade。巴萨那主要专注于加密币,担心代码中一些跟币圈相关的词汇会迷惑。
- 相比于vnpy:VeighNa封装过多,缺乏灵活性。使用其集成平台那就会失去灵活性,图省事的话不如使用其他一些集成平台了。另外,记得林园大佬说过一句话,一家公司发生减持,管他什么原因呢,不买就是了。同理,vnpy.cn还是vnpy.com分不清就都不用了吧。
本文适合已经至少完成了BackTrade的Quickstart Guide - Backtrader有需求的朋友阅读,如果还对BackTrader一窍不通,可以花上15分钟简单阅读以下官方的文档,并实操一下,简单单步调试一下源码。
DataFeed
BackTrader的数据源主要由Data Feeds - Backtrader模块进行处理, 其中大量使用了元编程技巧。底层实现中元类(metaclasses)。DataFeed底层主要核心数据通过LineBuffer进行封装。LineBuffer数据由LineRoot持有,自LineRoot以下的继承关系如下图所示:

其中代码逻辑比较简单的是PandasData,我们可以把它看做一个自定义DataFeed的示例,根据这个类的实现自己定制数据源。
Lines
DataFeed中数据是通过LineBuffer和策略模块进行共享,在上层OHLC中定义了7个标准的数据LineBuffer:
class OHLC(DataSeries):
lines = ('close', 'low', 'high', 'open', 'volume', 'openinterest',)
class OHLCDateTime(OHLC):
lines = (('datetime'),)
因为类hierarchy的限制,我们拓展DataFeed需要从AbstractDataBase或者DataBase层面进行集成,否则将会面临大量底层逻辑代码的重复实现。如上类图所见,包括PandasData在内的绝大多数BackTrader内置数据源类型都是继承于DataBase。
下面我们首先基于class PandasData(feed.DataBase)实现一个基础的tick数据加入到策略运行过程的示例,之后使用动态tick数据。这个实现实现非常简单,并不需要太多高深的编程技能。
测试CSV
为简化测试开发流程, 便于说明理解,使用我上传的CSV文件DCE.m2501.tick.202402,大小2M,比较适合框架开发过程的测试:https://download.csdn.net/download/u012677852/89460596?spm=1001.2014.3001.5503![]() https://download.csdn.net/download/u012677852/89460596?spm=1001.2014.3001.5503
https://download.csdn.net/download/u012677852/89460596?spm=1001.2014.3001.5503
这个文件是笔者采集的实盘豆粕合约数据,因为不是主力合约,数据量较小适合测试开发使用。
对于如何验证网络实盘tick数据,可以参考我的文章:【PA交易】前端根据内盘商品期货Tick数据合并日线Bar-CSDN博客
下文及后文如有需要,一律直接使用该文件名,不再特殊说明。
静态读入tick数据
如前所述,为了能够支持策略运行过程中使用tick数据源,首先定义一个数据类继承自bt.feed.DataBase。因为我们此步骤仅仅使用静态数据进行调通,所以类定义如下:
class MyDataFeedStatic(bt.feed.DataBase):因为我们是tick数据,其中的数据字段是类继承结构上层OHLC中没有定义的Line,所以我们需要使用一个tuple声明他们:
lines = (('price', 'vol', 'amount', 'ccl', 'bid', 'bidVol', 'ask', 'askVol'))之后为了简便起见,直接将测试CSV读取的DF保存在类中,并且指定一个_idx表示当前读取到的DF的行索引, 如下所示:
class MyDataFeedStatic(bt.feed.DataBase):
lines = (('price', 'vol', 'amount', 'ccl', 'bid', 'bidVol', 'ask', 'askVol'))
def __init__(self, df):
super(MyDataFeedStatic, self).__init__()
self.df = df
self._idx = 0
之后需要重载_load方法, 该方法由AbstractDataBase的load方法调用, 具体相关调用逻辑可以参考BackTrader源码。我们这里简单的逐行使用读取DF数据的方式实现这个方法:
def _load(self):
if self._idx >= len(self.df):
# exhausted all rows
return False
for datafield in self.getlinealiases():
if datafield == 'tickdt':
continue
if datafield in TICK_DATA_COLUMNS:
line = getattr(self.lines, datafield)
line[0] = self.df[datafield].iloc[self._idx]
# print(f'load {datafield} success')
# -------------------------------------------
# 添加日期时间
tstamp = self.df['tickdt'].iloc[self._idx]
self.lines.datetime[0] = date2num(tstamp)
self._idx += 1
return True
注意测试文件中的datatime使用的是tickdt作为列名,在BackTrader底层中会依赖datatime字段,这里因为数据中本来没有dataname字段,所以必须填充这个Line。
此时,一个简单的基于tick的数据源已经实现了,我们来使用它。首先装载过程,只需要预先读取一个DF,并传入即可:
df = pd.read_csv('./datas/DCE.m2501.tick.202402.csv')
df['tickdt'] = pd.to_datetime(df['tickdt'])
data_feed = sfeed.MyDataFeedStatic(df)
cerebro.adddata(data_feed)之后在策略构造函数中,为了后续使用方便,可以给每条管线起一个别名:
class TestStrategy(bt.Strategy):
def __init__(self):
# Ticks 字段
self.tickdt = self.datas[0].datetime
self.price = self.datas[0].price
self.vol = self.datas[0].close
self.amount = self.datas[0].amount
self.ccl = self.datas[0].ccl
self.bid = self.datas[0].bid
self.bidVol = self.datas[0].bidVol
self.ask = self.datas[0].ask
self.askVol = self.datas[0].askVol
self.local_tz = get_localzone()
之后在next方法中就可以访问到具体每个Tick的数据了:
def log(self, txt, dt=None):
''' 本地化时间输出 '''
utc_datetime = self.datetime if dt is None else dt
date = utc_datetime.date(0, tz=self.local_tz)
time = utc_datetime.time(0, tz=self.local_tz)
print('%s %s: %s' % (date, time, txt))
def next(self):
self.log('Tick price, %.2f' % self.price[0], self输出:
2024-02-01 17:00:00.059001: Tick price, 3127.00
2024-02-01 17:00:00.558999: Tick price, 3126.00
2024-02-01 17:00:01.058996: Tick price, 3126.00
2024-02-01 17:00:01.557997: Tick price, 3126.00
.....实时运行
当我们运行策略时,会发现策略的next方法并不是紧跟着数据源的_load方法运行。这是因为当前的策略运行不是实时模式。还需要在数据源类MyDataFeedStatic中Override一个方法:
class MyDataFeedStatic(...):
def islive(self):
return True这样策略将以实时模式运行,_load()函数中打印日志可以看到每次load运行之后才会运行策略的next函数。
题外话
这里的DF读写仅仅是一个模拟数据逐条实时传入的方式。考虑到数据源的复杂性,作为分享,这是我所使用的基础架构:
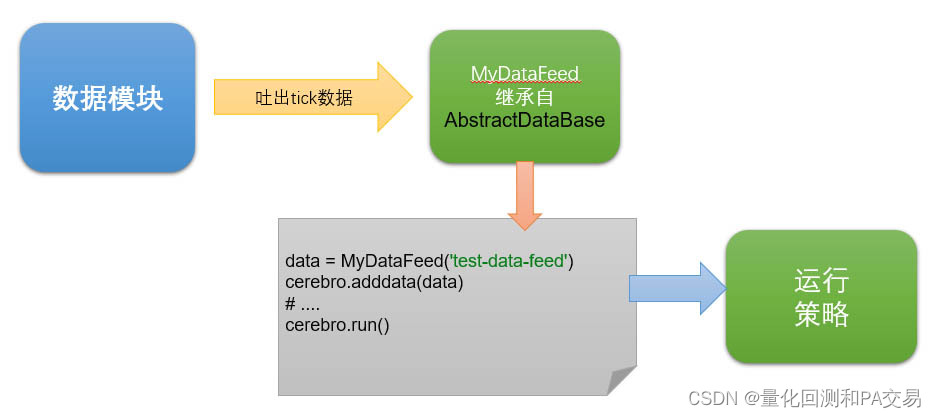
架构中抽象出一个数据模块,这个模块负责全部的数据处理,无论数据来自于CSV、数据库还是CTP。而MyDataFeed实际充当了一个数据模块和策略运行之间的Bridge角色(adapter)。MyDataFeed会在_load函数中向数据模块索要数据,如果数据没有就绪,则会阻塞操作(可以在当前示例代码中添加sleep(0.5)模拟CTP)。这样无论回测还是实盘,在数据管理都实现了一致性,即:一个策略的书写可以兼容不同场景,当我们回测夏普优秀,SimNow模拟回报丰厚的时候,我们可以通过切换数据模块参数的方式将策略快速无缝切换到实盘。
继续阅读
下篇文章将会首先将本文中的简单读取DF改为一个模拟上述架构中的简单的数据读取器。之后实现Tick和K Bar同时传递到策略中。
更多测试数据:
如果需要更多测试数据,可以下载这里的tic数据文件,已经整理成MySQL表,这里是导出的SQL,后续会更新更多其他测试数据:
内盘期货棕榈, 主力1、5、9月合约2020年到2024年TICK数据:
链接:https://pan.baidu.com/s/1UTt9Ei0dSaQ971Iq-YPIGA?pwd=j7hq
提取码:j7hq
(仅限测试开发学习使用, 请勿商用)
















 1796
1796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









