







 本文是机器学习的基础教程,涵盖了机器学习的定义、三要素、基本流程、核心应用场景,以及监督学习和无监督学习的分类。深度学习作为机器学习的一个分支,强调从数据中学习连续的表示层。机器学习的三要素包括数据、模型和算法,学习过程旨在找出数据的潜在规律。文章还介绍了模型评估和选择方法,如数据拟合、过拟合、偏差与方差的平衡,以及常用的性能度量指标。
本文是机器学习的基础教程,涵盖了机器学习的定义、三要素、基本流程、核心应用场景,以及监督学习和无监督学习的分类。深度学习作为机器学习的一个分支,强调从数据中学习连续的表示层。机器学习的三要素包括数据、模型和算法,学习过程旨在找出数据的潜在规律。文章还介绍了模型评估和选择方法,如数据拟合、过拟合、偏差与方差的平衡,以及常用的性能度量指标。
导言
最近有小半年由近半数工作和生活时间在机器学习技术(ML)的学习与工程实践中,感觉自己阅读了几本ML方面好书,找到了一些更好的学习网站,所以重新梳理了一下自己理解的的ML基础知识。
相关参考摘录书籍及网站如下
- 《机器学习实战:基于Scikit-Learn、Keras和TensorFlow》(第2版)
- 《Python深度学习》(第2版)
- 网站:https://www.showmeai.tech/
一、机器学习概述
1、什么是机器学习
人工智能(Artificial intelligence)
简而言之,人工智能可以被描述为试图将通常由人类完成的智力任务自动化。因此,人工智能是一个综合领域,不仅包括机器学习和深度学习,还包括更多不涉及学习的方法。
机器学习(Machine learning)
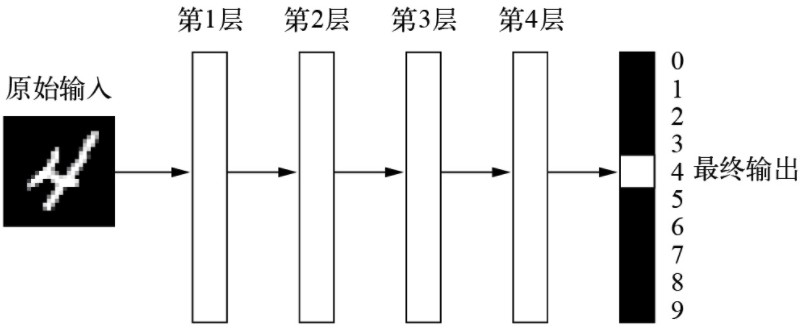
让计算机有效工作的常用方法是,由人类程序员编写规则(计算机程序),计算机遵循这些规则将输入数据转换为适当的答案。如下图所示——经典的程序设计

机器学习把这个过程反了过来:机器读取输入数据和相应的答案,然后找出应有的规则,如下图所示——机器学习。机器学习系统是训练出来的,而不是明确地用程序编写出来的。将与某个任务相关的许多示例输入机器学习系统,它会在这些示例中找到统计结构,从而最终找到将任务自动化的规则。

机器学习与数理统计相关,但二者在几个重要方面有所不同
- 与统计学不同,机器学习经常要处理复杂的大型数据集(比如包含数百万张图片的数据集,每张图片又包含数万像素),用经典的统计分析来处理这种数据集是不切实际的。因此,机器学习(尤其是深度学习)呈现出相对较少的数学理论(可能过于少了),从根本上来说是一门工程学科。
- 与理论物理或数学不同,机器学习是一门非常注重实践的学科,由经验发现所驱动,并深深依赖于软硬件的发展。
机器学习大概在上世纪80年代开始蓬勃发展,诞生了一大批数学统计相关的机器学习模型。
机器学习的定义
其中一个工程化的概念
一个计算机程序利用经验E来学习任务T,性能是P,如果针对任务T的性能P随着经验E不断增长,则称为机器学习。 比如一个电商领域的应用
- T:将用户可能购买的商品推荐给用户;
- E:用户查看、忽略或购买了某商品;
- P:用户成功购买商品的比率;
机器学习算法
对于一项数据处理任务,给定预期输出的示例,机器学习系统可以发现执行任务的规则。
- 输入数据。如果任务是语音识别,那么输入数据可能是记录人们说话的声音文件。如果任务是为图像添加标签,那么输入数据可能是图片。
- 预期输出的示例。对于语音识别任务来说,这些示例可能是人们根据声音文件整理生成的文本。对于图像标记任务来说,预期输出可能是“狗”“猫”之类的标签。
- 衡量算法效果的方法。其目的是计算算法的当前输出与预期输出之间的差距。衡量结果是一种反馈信号,用于调整算法的工作方式。这个调整步骤就是我们所说的学习。
机器学习模型将输入数据变换为有意义的输出。简而言之,机器学习就是指在预先定义的可能性空间中,利用反馈信号的指引,在输入数据中寻找有用的表示和规则。
什么是表示?
~
这一概念的核心在于以一种不同的方式来查看数据(表征数据或将数据编码)。比如彩色图像可以编码为RGB(红−绿−蓝)格式或HSV(色相−饱和度−明度)格式,这些是对同一数据的两种表示。机器学习模型旨在为输入数据寻找合适的表示(对数据进行变换),使其更适合手头的任务。
深度学习
深度学习是机器学习的一个分支领域:它是从数据中学习表示的一种新方法,强调从连续的层中学习,这些层对应于越来越有意义的表示。
~
深度学习之“深度”是指一系列连续的表示层,数据模型所包含的层数被称为该模型的深度(depth)。现代深度学习模型通常包含数十个甚至上百个连续的表示层,它们都是从训练数据中自动学习而来的。与之相对,其他机器学习方法的重点通常是仅学习一两层的数据表示(例如获取像素直方图,然后应用分类规则),因此有时也被称为浅层学习(shallow learning)。
~
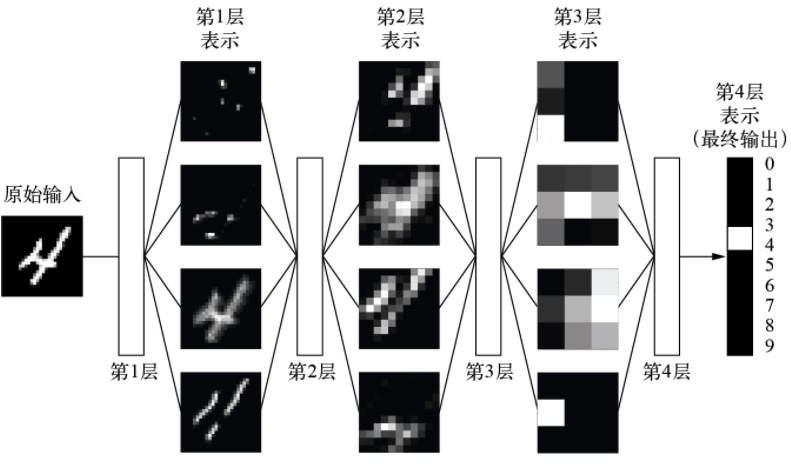
在深度学习中,这些分层表示是通过叫作神经网络(neural network)的模型学习得到的。神经网络的结构是逐层堆叠。如下图所示——用于数字分类的深度神经网络
这个神经网络将数字图像变换为与原始图像差别越来越大的表示,而其中关于最终结果的信息越来越丰富。你可以将深度神经网络看作多级信息蒸馏(information distillation)过程:信息穿过连续的过滤器,其纯度越来越高(对任务的帮助越来越大)。如下图所示——数字分类模型学到的数据表示
2、机器学习三要素
机器学习三要素包括数据、模型、算法。这三要素之间的关系,可以简单示意如下:
data + Algorithm ——> model
数据
AI中的“数据驱动”是通过数据实现“智能”的体现——通过数据获取、数据分析,基于算法和模型形成数据应用、数据反馈的闭环。
算法
指学习模型的具体计算方法。统计学习基于训练数据集,根据学习策略,从假设空间中选择最优模型,最后需要考虑用什么样的计算方法求解最优模型。通常是一个最优化的问题。
模型
在AI数据驱动的范畴内,模型指的是基于数据X做决策y的假设函数,可以有不同的形态,计算型和规则型等。
3、机器学习基本流程
机器学习工作流(WorkFlow)包含数据预处理(Processing)、模型学习(Learning)、模型评估(Evaluation)、新样本预测(Prediction)几个步骤。
- 数据预处理:输入(未处理的数据 + 标签)→处理过程(特征处理+幅度缩放、特征选择、维度约减、采样)→输出(测试集 + 训练集)。
- 模型学习:模型选择、交叉验证、结果评估、超参选择。
- 模型评估:了解模型对于数据集测试的得分。
- 新样本预测:预测测试集。
4、机器学习的核心应用场景
- 分类:应用以分类数据进行模型训练,根据模型对新样本进行精准分类与预测。
- 聚类:从海量数据中识别数据的相似性与差异性,并按照最大共同点聚合为多个类别。
- 回归:根据对已知属性值数据的训练,为模型寻找最佳拟合参数,基于模型预测新样本的输出值。
- 异常检测:对数据点的分布规律进行分析,识别与正常数据及差异较大的离群点。
| 应用场景示例 | |
|---|---|
| 分类 | 用户画像、情感分析、用户行为预测、图像识别 |
| 聚类 | 市场细分、模式识别、空间数据分析、图像处理与分析 |
| 回归 | 趋势预测、价格预测、流量预测 |
| 异常检测 | 日常运行监控、风险识别、舞弊检测 |
二、机器学习的基本名词
- 监督学习(Supervised Learning)【有特征有标签】:提供数据并提供数据对应结果的机器学习过程,学习方式有分类和回归。
从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人工标注的。常见的监督学习算法包括回归分析和统计分类。
- 无监督学习(Unsupervised Learning)【有特征无标签】:提供数据但不提供数据对应结果的机器学习过程,学习方式有聚类和降维。
与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有生成对抗网络(GAN)、聚类。
- 强化学习(Reinforcement Learning)【有延迟和稀疏的反馈标签】:通过与环境交互并获取延迟反馈进而改进行为的机器学习过程。
通过观察来学习做成如何的动作。每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
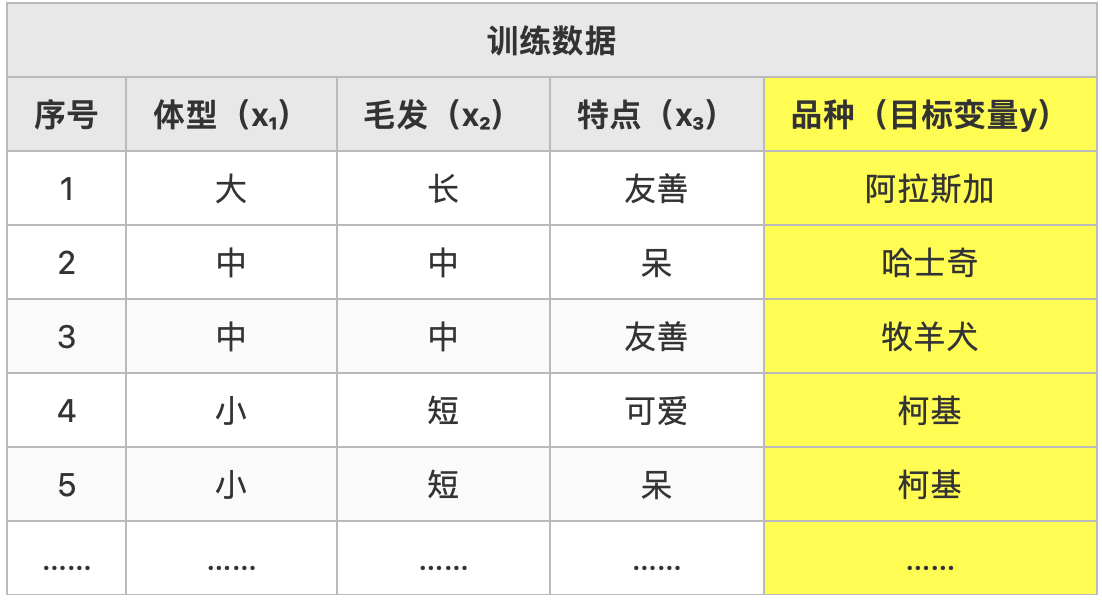
- 示例/样本:上表中数据集中的一条(行)数据。
- 属性/特征:「体型」「毛发」等。
- 属性空间/样本空间/输入空间x:由全部属性形成的空间。
- 特征向量:空间中每个点对应的一个坐标向量。
- 标签:关于示例结果的信息,如((体型=大,毛发=长,特点=友善),阿拉斯加),其中「阿拉斯加」称为标签。
- 分类:若要预测的是离散值,如「阿拉斯加」,「哈士奇」,此类学习任务称为分类。
- 假设:学习模型对应了关于数据的某种潜在规律。
- 真相:潜在规律自身。
- 学习过程:是为了找出或逼近真相。
- 泛化能力:学习模型适用于新样本的能力。一般来说,训练样本越大,越有可能通过学习来获得具有强泛化能力的模型。
三、机器学习的算法分类
机器学习算法从数据中自动分析获得规律,并利用规律对未知数据进行预测。
机器学习算法依托的问题场景
- 分类:从若干离散值中做选择;
- 回归:预估输出连续值结果;
- 聚类:发现与挖掘数据分布的聚集特性;
监督学习
1、分类问题
分类问题是机器学习非常重要的一个组成部分。它的目标是根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类。分类问题可以细分如下:
- 二分类问题:表示分类任务中有两个类别,新的样本属于其中之一,比如邮件中的正常邮件和垃圾邮件。
- 多类分类(Multiclass classification)问题:表示分类任务中有多种类别,比如数字识别。
- 多标签分类(Multilabel classifica
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









