







注:本文中所有公式和思路来自于李航博士的《统计学习方法》一书,我只是为了加深记忆和理解写的本文。
朴素贝叶斯(naive bayes)是基于贝叶斯定理和特征条件独立假设的分类器,对于给定的训练数据集,首先基于特征条件独立假设学习输入\输出的联合概率分布;然后基于此模型,输入x,利用贝叶斯定理求出最大后验概率y。
朴素贝叶斯这个名字乍一看感觉蛮奇怪的,何为“朴素”呢?因为朴素贝叶斯有两个很强的假设:一是特征之间条件独立,二是特征之间权重相同,因此得名。于是我们可以用下面的公式表达这个假设:
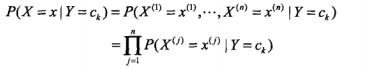
其中X为样本空间X={x1,x2,x3..xn},Y为标记空间Y={c1,c2,c3...ck},这里边的c说白了就是类别,如果是垃圾邮件系统就是1(垃圾邮件)、0(非垃圾邮件),如果是论坛评论1(垃圾)、0(非垃圾),j表示x的取值,可以是本字典,也可以是当前系统的词集,仅此而已。
朴素贝叶斯是生成模型,因为本质是学习了生成数据的机制,条件独立假设就意味着如果给定了条件,那么分类的特征就是相互独立的,虽然使得模型简单了一些,但是会损失一定的准确率,就像我说“机器”那么下个词说“学习”的概率是很大的,是不独立的,在朴素贝叶斯法中我们视为独立的。
输入x,通过学习的模型来计算后验概率P(Y=ck | X=x),将后验概率最大的类输出,公式为:
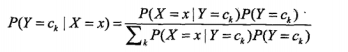
那么将第一个公式带入第二个公式则有:
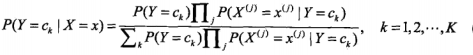
这是朴素贝叶斯的基本公式,那么朴素贝叶斯分类器就可以表示为:
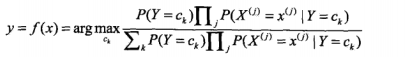
但是在由于我们只是分类而不输出实际的后验概率的话,就可以去掉分母,因为对于求最值来说,分母都一样,没必要留着,于是可以简化成下边的公式:
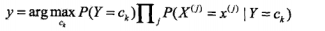
是不是特别简单,对的,就是这么的简单,而且在垃圾邮件分类或论坛留言过滤还是很有效的。
但是需要注意几个地方:
1. 如果有10000个词,每个词条件概率又很小,那么连乘的话早就下溢出了,如何破?
答:可以取对数
2. 如果J中的词有的没出现过,那么就是0,一乘可就全部为0了?
答: 可以使用拉普拉斯平滑,如果用n1表示一词在某分类中的词典出现的次数,n表示该类的总词数,J为所有类别总词数,那么可以以(n1+1)/(n+J)
3. 如果一个词在文中出现多次和一个词只出现一次的词向量相同怎么办?
答: 改01为计数
4. 如何判断两个文档的距离?
答:夹角余弦
5. 如何确定分类器的正确率?
答:交叉验证
朴素贝叶斯优缺点:
优点:
对小规模的数据表现很好,适合多分类任务,适合增量式训练。
缺点:
对输入数据的表达形式很敏感(离散、连续,值极大极小之类的)















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









