







注:本文中所有公式和思路来自于邹博先生的《机器学习升级版》,我只是为了加深记忆和理解写的本文。
最大熵模型可能好多朋友听过但是没有真正的看见过他的实际应用,其实最大熵模型和Logistic回归、Softmax回归是属于广义上的同种模型,一会我们推导就可以得出这个结论,另外最大熵模型和最大似然估计也是存在着有趣的联系,我们一步步来看。
说到最大熵模型,首先就得说说什么是熵,说到熵就的说一说信息量。
简单来说:我们常常说一件事情发生的概率越小,那么它的信息量是越大的,如果一件事情发生的概率为1,那么信息量为0,等于说这是一句废话,我们可以这么来定义信息量:
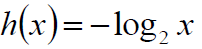
我们接着对一个随机事件求期望,那么就是熵的定义:
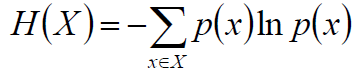
如果是两点分布,那么熵可以这么表示:
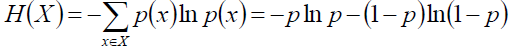
我们可以将两点分布的熵的变化图画出来:
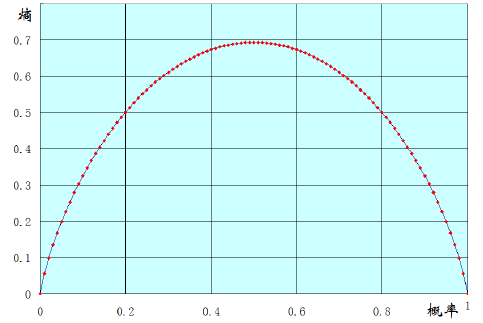
看得出来,两点分布的话,如果发生概率都是0.5那么熵最大,概率为0/1熵为0.
那么三点分布呢、多项分布呢?
如果推广到多点分布,那么概率相等也就是均匀分布的熵是最大的。
从上边这些推理中,我们可以知道,熵其实就是随机事件不确定性的度量,不确定性越大,熵越大,如果是随机分布的话,均匀分布的熵最大,如果给定方差和均值的前提下,高斯分布的熵最大(推导过程就细说了,用拉格朗日乘子法来做,比较简单)。
(额外说一句,我还记得高中化学学习的上度量的就是混乱程度,与数学上的是没有冲突的)
但是通常情况下随机事件经常是联合发生或者有前提条件,那么就应该用联合熵和条件熵来衡量了。
联合熵的表示:H(X,Y)
条件熵的表示:H(X | Y) = H(X,Y) - H(Y)
其中条件熵我们可以这么来解释:X,Y已发生的联合熵减去Y发生熵,也就是在Y发生的前提下,X发生带来新的熵。
那么我们沿着条件的定义式,进行一下推到探索:
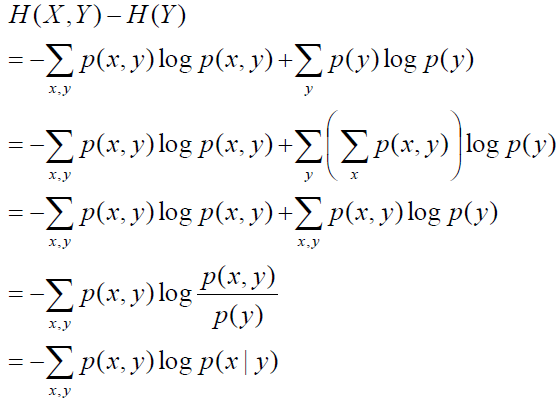
得到的结果挺奇怪的,为什么不是对称的p(x | y)logp(x | y)呢?那么按照这个结论的话,如果given X呢?
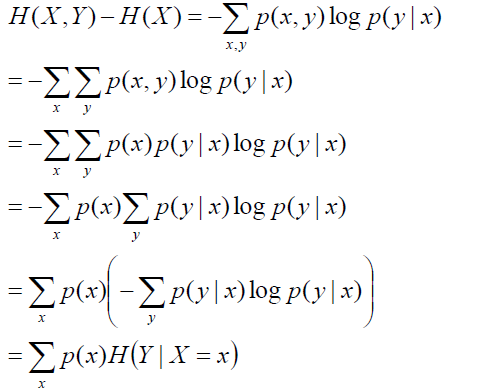
最终我们可以得到,条件熵其实是在给定X=x的前提下Y发生的条件熵再对p(x)求期望。
相对熵:又称互熵、交叉熵、鉴别信息、Kullback熵、Kullback-Leible散度。。。。
定义:设p(x)和q(x)是X取值中的两个概率分布,则p(x)对q(x)的相对熵是:
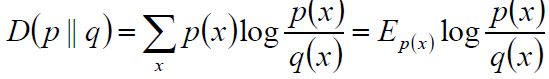
关于相对熵也就是kl散度的介绍请看我之前的一篇文章:变分法,里边有详细的介绍。
互信息:两个随机变量X、Y的互信息,定义为X、Y的联合分布和独立分布乘积的相对熵:
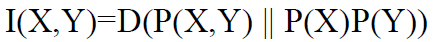
或:
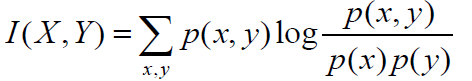
我们将条件熵的定义展开计算一下:
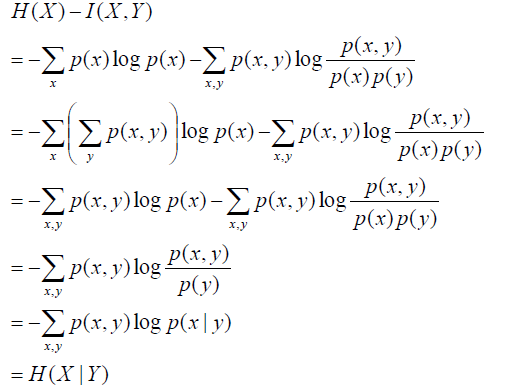
根据上边着公式,我们可以整理得到一些等式:
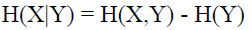
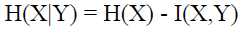
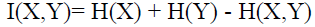
不知道大家看到这些公式会不会脑袋嗡的一下,说实话,我第一次接触这些东西的时候,其实是拒接的,然后来静下心来,耐這性子取细琢磨每一个推导,其实根本不难,就是纸老虎而已。
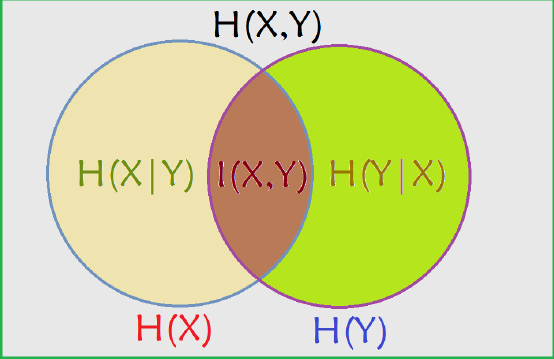
我们还可以接触Venn图来表示这些,这就清楚多了:
Maxent
一般模型:
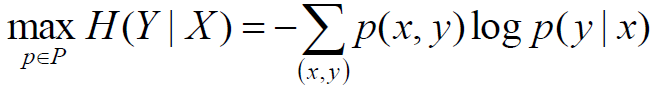
那么该模型满足什么条件呢?
st. ∑p(y | x) = 1
p(y | x)p(x) = p(x,y) ---------p(y | x)是我们待求的,p(x)是样本分布,p(x, y)是样本的联合概率,这个条件的意思就是我们待求的条件概率与样本的分布的乘机应该等于联合分布的这么一个事实。
我们将一般模型加上拉格朗日乘子:
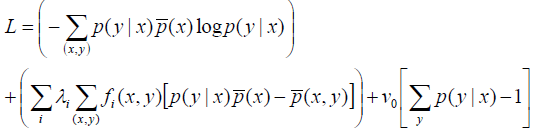
其中f(x,y)可以理解为特征,也就是说在所有特征上满足。
我们对p(x)求偏导:
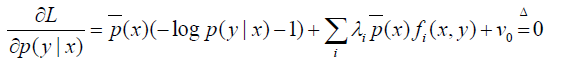
令:
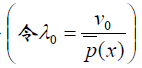
可得:
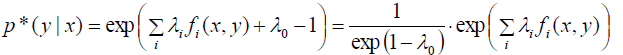
其中λ和v只是相差常系数,后边可以直接用λ代替v。
上边的公式其实是没有归一化的我们扔掉前边的系数部分,因为不影响结果。接着做一个归一化处理:
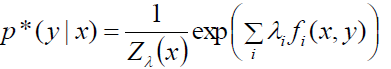
这是什么???怎么着像Softmax回归呢!!!!!
我们不妨看看Logistic回归和Softmax回归的后验概率:
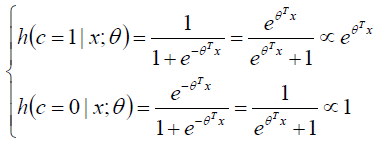
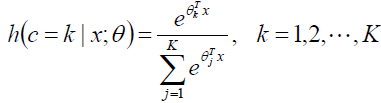
这简直就是一个一个妈生的,实在太像了!!!!
到此,最大熵模型就介绍完了,后边将会介绍一个最大熵模型的一个应用:ICA















 9187
9187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









