







上周去参加一个深度学习实习的面试,总的来说,比较惨,虽然也答出来不少,但是很多东西自己没有认真关注过,所以就很狼狈,所以在这里记录下,能回忆起的一点东西吧。接下来的几个问题都是自己根据查阅的博客以及资料总结的,所以如果有任何错误,希望能够批评指正!
1、关于损失函数的
写出cross entropy的计算公式
因为交叉熵一般会与softmax回归一起用,这里也把softmax函数顺带提一下
对应的函数:cross_entroy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(y_, 1), logits=y)
2、关于激活函数的
ReLU函数与sigmoid的区别:
sigmoid会导致梯度弥散,而且计算耗时,ReLU解决了部分梯度弥散问题,而且收敛速度快。
3、关于卷积网络参数计算
一个是卷积层的计算,例如,卷积之后输出矩阵的尺寸大小以及深度
使用全0填充时:
不使用全0填充
至于输出的深度,与卷积核的个数相同。
计算卷积层的参数个数:通道数*卷积核个数+卷积核个数
池化层的输出尺寸大小计算方法与卷积层一样,而不会改变深度
4、写出SGD的计算公式
这个熟练的话可以直接写出来,不熟练的话推导一下也是很简单的,推导的时候建议画一个两层网络的图,这样可以防止书写的时候写错符号。
接下来就该悲催了,因为本人都是自己摸索的一点东西,其实并没有系统的进行学习,所以很多东西都是听过见过没用过,答不上来。
5、LSTM中input Gate、output Gate、forget Gate、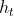 、cell更新等的计算公式
、cell更新等的计算公式
因为没有用过LSTM所以理解并不深刻,对公式推导也没很深的去研究,所以,当时一脸迷茫,现在赶紧补。
forget gate:
input gate:
cell:
output gate:

具体的推导https://www.cnblogs.com/pinard/p/6519110.html
6、FaceNet的损失函数并简述下网络结构
闭门造车的最严重后果就是。。。我对近几年的新网络了解的真很少。这个也没写出来,虽然很简单,也不能发表更多自己的见解,汗颜。
网络结构简述的话,前半部分为卷积神经网络,然后使用L2归一化,接下来是嵌入层,最后使用三元组损失函数。根据面试官的问题,再展开回答就好了。
其实还有很多问题,但是因为大多数没听过没见过,也就记不住了,就先记录到这,还需要加倍努力!















 3418
3418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









