







出处:ACL 2018
一、摘要
论文探索了在智能个人数字助理领域(IPDA)将用户口语输入映射到domain这个任务。主流的IPDA有很多第三方开发的domain,这在第一方domain的基础上大大提高了domain的丰富度。论文提出一种可以共享编码器且融合注意力机制的可扩展神经网络模型来解决这个问题,模型融合了个性化信息,并且可以高效适应不断增长的第三方domain,比完全重训取得2个量级上的加速。论文参照真实的工业系统,考虑了内存约束和延时。最后证明了,融合个人信息可以显著增加domain分类的准确率。
二、 介绍
背景: 第三方开发者极大丰富了domain的数量,比如亚马逊的Alexa有4万个技能,每个技能都可以看做一个domain。
难点: 1. 技能数量太多,因此找到最符合用户需求的技能难度很大;2.新技能以每周100+的速度快速增长,IPDA应该能在不损伤效果的前提下融合新增技能;3.第一方domain被很好的设计成彼此没有重叠,但是第三方技能的domain却是彼此重叠的,比如可能有50个技能同时和用户的需求匹配。
三、 数据生成
因为domain总量非常大,所以人工构建训练样本不可能,因此论文采用一种弱监督的方法构建样本。数据构建包括两部分,一部分是生成,一部分是过滤噪声。
生成: 首先人工建立一些生成用户表达的函数(就是query模板),比如"Ask {Uber} to {get me a car}",这里get me a car是用户表达u,Uber是技能s,因此query模板就是"Ask {s} to {u}",然后去匹配用户真实日志,这样可以得到很多有噪声的正样本。
噪声过滤: 上面步骤生成的数据有很多噪声数据,因此定义了一系列噪声过滤函数(规则)去删除不合理样本。规则示例:
- 用户表达u长度短于3个词的丢掉
- 丢掉低于一定词共现阈值的样本
- 丢弃从泛化能力太强的query模板生成的样本
- 丢掉有多重意图的样本
四、模型
整体模型结构图如下:

4.1 共享编码
如图彩色部分为用户表达编码器,采用字词混合的层次LSTM模型,字向量纬度25,词向量纬度50。字的LSTM输入输出纬度为25,双向LSTM输出50纬向量与词向量拼接成100纬向量。词的LSTM输入纬度100输出纬度为50,双向LSTM输出100纬向量,取所有隐藏层求和的结果为用户表达向量h。
4.2 注意力机制
作者证明,只对用户订阅的domain(即论文中指的个性化信息)分类比对所有IPDAs支持的domain分类的准确率有非常大的提高。因此作者使用1bit的标记位来表明domain是否为用户订阅的,并和用户表达向量h拼接起来送入domain分类器。此外作者证明,使用用户表达向量h作为key,用户订阅的domain向量(100纬)作为context,求attention(内积形式)之后得到向量att,然后和用户表达h一起拼接起来送入domain分类器,能显著提高对有重叠domain的辨识度,作者认为这是因为attention信息有一些补充特征,并且学到了domain之间的共现信息。
4.3 domain分类器
论文提到多类别softmax对性能消耗很大,因此作者提出每个domain分别分类的方式,避开多类别softmax操作。每个分类器的输入是用户表达向量h,1bit的标记位和100纬的attention向量att,输出纬度为2,因此参数量为201*2,参数较少,带来速度内存的提升。当样本的domain跟该分类器代表的domain一致时,使用输出的第一个纬度计算损失,不一致时使用第二个纬度值计算损失。公式如下:

注意,这里σ不是sigmod函数,而是SeLU函数,详见附录。公式中IND表示分类器命中了domain,取z的第一个纬度,OOD相反。
损失函数包括命中实际domain的分类器的损失(只有1个,因为在数据去重噪声时过滤了多domain的表达),对没有命中domain的分类器取平均损失。

4.4 新domain扩展
首先根据已经训练好的当前模型,拿到已有的domain向量d和domain里面的用户历史表达向量h,计算该domain下所有历史表达向量h的平均值havg。定义矩阵U,使用最小二乘法作为损失函数,计算使得U·havg和d最接近的U。即
U*=arg min||U·havg - d||, ∀d 属于D,D为所有已有的domain向量。
然后计算新domain所有表达的平均值,跟U矩阵相乘得到的值作为新domain的向量表示,然后使用新domain的用户表达重新训练该domain分类器对应的201*2个参数即可。
在此过程中固定共享编码器部分参数,因为作者发现新domain的用户表达有95%的词汇都在已有的词汇列表中,因此用户表达部分不需要重新训练。作者证明这种方法,可以在基本保证精度不损失的前提下,将完全重新训练的时间缩短2个数量级。
五、 TODO
- 多头attention,并且改进用户表达编码器
- 更好的编码用户个性化信息
附录
SeLU函数的表达式如下:
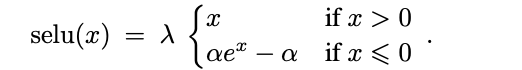
其中
α = 1.6732632423543772848170429916717
λ = 1.0507009873554804934193349852946
函数图像为:
















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









