








摘要
最近的实时视图合成技术在保真度和速度方面取得了迅速的进步,现代方法能够以交互式帧速率渲染近乎逼真的场景。与此同时,在适合光栅化的显式场景表示和基于光线行进的神经场之间出现了紧张关系,后者的先进实例在质量上超过了前者,而对于实时应用程序来说却非常昂贵。我们引入了 SMERF,这是一种视图合成方法,可在占地面积达 300 m 的大型场景中实现实时方法中最先进的精度,体积分辨率为 3.5 mm。我们的方法建立在两个主要贡献之上:一种是分层模型分区方案,它增加了模型容量,同时限制了计算和内存消耗,另一种是蒸馏训练策略,同时产生了高保真度和内部一致性。我们的方法可以在网络浏览器中实现完整的六自由度导航,并在商品智能手机和笔记本电脑上实时渲染。大量实验表明,我们的方法在标准基准测试中比实时新颖视图合成中最先进的方法高出 0.78 dB,在大场景中比 1.78 dB 高出 1.78 dB,渲染帧的速度比最先进的辐射场模型快三个数量级,并在包括智能手机在内的各种商品设备上实现实时性能。我们鼓励读者在我们的项目网站上以交互方式探索这些模型:https://smerf-3d.github.io。
引言
辐射场已成为一种功能强大、易于优化的表示形式,用于重建和重新渲染逼真的真实世界 3D 场景。与网格和点云等显式表示相比,辐射场通常存储为神经网络,并使用体积光线行进进行渲染。这既是表示的最大优势,也是最大的弱点:神经网络可以简洁地表示复杂的几何形状和视图相关的效应,前提是有足够大的计算预算。作为体积表示,渲染图像所需的操作数量以像素数而不是基元(例如三角形)的数量进行缩放,性能最好的模型 [Barron 等人,2023 年] 需要数千万次网络评估。因此,实时辐射场在质量、速度或表示大小方面做出了让步,它们是否可以与高斯溅射等替代方法竞争是一个悬而未决的问题。
我们的工作肯定地回答了这个问题。我们提出了一种可扩展的方法,以比以前更高的保真度实时渲染大型空间。我们的方法不仅在标准基准测试中接近较慢、最先进的模型的质量,而且是第一个令人信服地在商用硬件上实时渲染无界多房间空间的方法。至关重要的是,我们的方法在不影响图像质量或渲染速度的情况下,以独立于场景大小的内存预算实现了这一点。
我们使用内存效率辐射场 (MERF) [Reiser 等人,2023 年]的变体,这是一种用于实时视图合成的紧凑表示,作为核心构建块。我们构建了一个由独立的 MERF 子模型组成的分层模型架构,每个子模型专门用于场景中的一个视点区域。这大大增加了模型容量,同时限制了资源消耗,因为渲染任何给定相机只需要一个子模型。具体来说,我们的架构使用子模型对场景进行平铺以提高空间分辨率,并对每个子模型区域内的参数进行平铺,以更准确地对与视图相关的效果进行建模。我们发现模型容量的增加是一把双刃剑,因为我们的架构缺乏最先进的离线模型的归纳偏差,这些模型鼓励合理的重建。因此,我们引入了一种有效的新蒸馏训练程序,该程序提供了对颜色和几何形状的丰富监督,包括对新视点的泛化和相机运动下的稳定结果。这两项创新能够实时渲染大型场景,其规模和质量与现有最先进的作品相似。
具体而言,我们的两个主要贡献是:
• 用于实时辐射场的平铺模型架构,能够在从智能手机到台式工作站的硬件上以高保真度表现大型场景。
• 辐射场蒸馏培训程序,可产生高度一致的子模型,具有准确但计算量大的教师的泛化能力和归纳偏差。
相关工作
Neural Radiance Fields 取得了爆炸性进展,这使得全面审查具有挑战性。在这里,我们只审查与我们工作直接相关的论文,无论是作为构建块,还是作为明智的替代方案。请参阅 Tewari et al. [2022] 了解全面概述。
提高 NeRF 的速度。尽管 NeRF 产生了令人信服的结果,但它在速度方面严重不足:训练模型需要数小时,渲染图像需要长达 30 秒 [Mildenhall 等人,2020 年]。从那时起,人们就投入了大量精力来加速 NeRF 的训练和推理。
许多作品通过将 NeRF 的视图相关颜色和不透明度预计算(即烘焙)为稀疏的体积数据结构来实现实时渲染 [Garbin 等人,2021 年;Hedman 等人,2021 年;Yan 等人,2023 年;Yu 等人,2021 年]。其他工作表明,通过参数化具有密集的辐射场,可以显着加速渲染和/或训练 [Sun 等人,2022 年;Wu 等人,2022a;Yu 等人,2022 年]、哈希 [Müller 等人,2022 年]或低秩体素网格参数化 [Chan 等人,2022 年;Chen 等人,2022 年],小型 MLP 网格 [Reiser 等人,2021 年],或神经纹理的“多边形汤”[Chen 等人,2023 年]。或者,可以通过减少样本预算来加速渲染,同时仔细分配体积样品以保持质量 [Gupta 等人,2023b;Kurz 等人,2022 年;Neff 等人,2021 年;Wang 等人,2023 年]
通常,渲染时间和内存消耗之间存在紧张关系。这在 MERF [Reiser 等人,2023 年]中进行了探索,它结合了稀疏和低秩体素网格表示,以在有限的内存预算内实现无界场景的实时渲染 [Reiser 等人,2023 年]。我们以 MERF 为基础,并将其扩展到更大的环境,同时保持实时性能并遵守商用设备的严格内存限制。
提高 NeRF 的质量。同时,社区以多种方式提高了 NeRF 的质量,例如消除混叠 [Barron 等人,2021 年;胡等人,2023 年],引入高效的模型架构 [Müller 等人,2022 年],对无界场景进行建模 [Barron 等人,2022 年],并消除漂浮物 [Philip 和 Deschaintre 2023]。其他工作提高了对其他挑战的鲁棒性,例如不准确的相机姿势 [Lin 等人,2021 年;Park 等人,2023 年;Song 等人,2023 年],有限监督 [Niemeyer 等人,2022 年;Roessle 等人,2023 年;Wu 等人,2023a;Yang 等人,2023 年],或异常值,包括照明变化、瞬态物体 [Martin-Brualla 等人,2021 年;Rematas et al. 2022]和运动 [江 et al. 2023;Park 等人,2021 年]。
与我们的工作最相关的是 Zip-NeRF [Barron 等人,2023 年],它使用多重采样来实现基于网格的快速表示的抗锯齿,并生成大型环境的准确重建,同时保持易于训练和渲染。尽管 Zip-NeRF 目前在已建立的基准测试中实现了最先进的质量,但单个高分辨率帧需要数秒钟的渲染,并且该方法不适用于实时渲染应用。因此,我们采用将高保真 Zip-NeRF 模型提炼成一组基于 MERF 的子模型的方法,从而在实时帧速率下实现与 Zip-NeRF 相当的质量。我们还结合了上面列出的几项质量改进,例如用于照明变化的潜在代码 [MartinBrualla 等人,2021 年] 和用于去除漂浮物的梯度缩放 [Philip 和 Deschaintre 2023],对渲染速度没有影响。更多细节可以在应用程序F中找到。
基于光栅化的视图合成。虽然 NeRF 使用每像素光线行进来合成视图,但另一种范式是利用专用 GPU 硬件的原始光栅化。早期的这种视图合成方法使用三角形网格近似几何,并使用图像混合来模拟与视图相关的外观 [Buehler 等人,2001 年;Davis 等人,2012 年;Debevec 等人,1998 年]。后来的方法通过神经外观模型提高了质量 [Hedman 等人,2018 年;Liu 等人,2023 年;Martin-Brualla 等人,2018 年]或神经网重建 [Philip 等人,2021 年;Rakotosaona 等人,2023 年;Rojas 等人,2023 年;Wang 等人,2021 年;Yariv 等人,2023a]。最近的方法通过栅格化重叠网格并解码 [Wan et al. 2023] 或合成 [Chen et al. 2023] 结果来对详细几何进行建模。对于有限的观看体积,可以使用分层表示(例如多平面图像)对半透明进行建模 [Flynn 等人,2019 年;Mildenhall 等人,2019 年;Penner 和 Zhang 2017;周等人,2018]。
GPU 硬件还可以加速基于点的表示的渲染。这可以通过使用 U-Net 解码稀疏点云来合成视图 [Aliev 等人,2020 年;Rückert 等人。2022;Wiles 等人,2020 年]。虽然输出视图在相机运动下往往不一致,但这可以通过将每个点扩展到圆盘中来解决 [Pfister 等人,2000 年;Szeliski 和 Tonnesen 1992],配备软重建内核 [Zwicker et al. 2001]。最近的研究表明,这些基于软点的表示适用于基于梯度的优化,并且可以有效地模拟半透明以及与视图相关的外观 [Kopanas 等人,2021 年;Zhang 等人,2022 年]。
与我们的工作最相关的是 3D 高斯溅射 [Kerbl et al. 2023] (3DGS),它提高了视觉保真度,简化了初始化,减少了基于软点的表示的运行时间,并代表了当前实时视图合成的最新技术。虽然 3DGS 在许多场景中都能产生高质量的重建,但优化仍然具有挑战性,并且需要精心选择的启发式方法来分配点。这在大型场景中尤为明显,因为许多区域缺乏足够的点密度。为了实现实时训练和渲染,3DGS 进一步依赖于特定于平台的功能和底层 API。虽然最近的观众在商品硬件上展示 3DGS 模型 [Kellogg 2024;郭 2023;Červený 2023],这些依靠近似值来排序顺序和视图依赖性,其对质量的影响尚未得到评估。并行工作 [Fan 等人,2023 年;Lee 等人,2023 年]的视觉保真度略有降低,从而显着减小了模型尺寸。在我们的实验中,我们直接将跨平台网络查看器与最新版本的官方 3DGS 查看器进行比较。
大型 NeRF。尽管 NeRF 模型擅长再现场景的对象和局部区域,但它们很难扩展到更大的场景。对于以对象为中心的捕获,可以通过将场景的无界背景区域重新参数化为有界域来改善这种情况 [Barron 等人,2022 年;Zhang 等人,2020 年]。通过将抗锯齿技术应用于散列网格支持的辐射场,可以对更大的多房间场景进行建模 [Barron 等人,2023 年;Xu 等人,2023 年]。另一种方法是将场景拆分为多个区域,并为每个区域训练单独的 NeRF [Rebain 等人,2019 年;Turki 等人,2022 年;Wu 等人,2023b]。这个想法还有助于对象 [Reiser 等人,2021] 和房间规模场景 [Wu 等人,2022b] 的实时渲染。然而,扩展到城市街区或整个城市环境等超大型场景需要根据摄像机位置划分为冗余、重叠的场景体积 [Meuleman 等人,2023 年;Tancik 等人,2022 年]。我们将基于相机的分区思想扩展到实时视图合成:虽然现有模型需要来自多个子模型的昂贵渲染和图像混合,但我们只需要一个子模型来渲染给定的相机,并在训练期间利用正则化来鼓励相互一致性。
蒸馏和NeRF。深度学习中一个强大的概念是蒸馏——训练一个更小或更有效的学生模型,以近似一个更昂贵或更繁琐的教师的输出 [Gou 等人,2021 年;Hinton 等人,2015 年]。这个想法已成功应用于各种情况下的 NeRF,例如 (i) 将大型 MLP 提炼成微小 MLP 网格 [Reiser 等人,2021 年],(ii) 将昂贵的 NeRF MLP 提炼成限制密度的小型“建议”MLP [Barron 等人,2022 年],或 (iii) 将昂贵的二次光线反射提炼成轻量级模型进行反向渲染 [Srinivasan 等人,2021 年]。蒸馏也被用于通过将整个 NeRF 场景转换为光场模型来避免昂贵的光线行进并促进实时渲染 [Attal 等人,2022 年;Cao 等人,2023 年;Gupta等人,2023a;Wang 等人,2022 年]或表面表示 [Rakotosaona 等人,2023 年]。
在这项工作中,我们将一个大型、高质量的 Zip-NeRF 模型的外观和几何形状提炼成一个类似 MERF 的子模型系列。同时,HybridNeRF [Turki et al. 2023] 也采用蒸馏进行实时视图合成,尽管是针对有符号距离场。
模型
尽管像 MERF 这样的实时视图合成方法在局部环境中表现良好,但它们通常无法扩展到大型多房间场景。为此,我们提出了一个分层架构:首先,我们将整个场景的坐标空间划分为一系列块,其中每个块都由其自己的类似 MERF 的表示进行建模。其次,我们在每个模块中引入了一个空间锚定网络参数网格,用于对视图相关效应进行建模。最后,我们引入了一种门控机制,用于调制对位置特征表示的高分辨率和低分辨率贡献。我们的整体架构可以看作是一个三级层次结构:基于相机原点,(i) 我们选择一个合适的子模型,然后在子模型中 (ii) 我们通过插值计算延迟外观网络的参数,然后在局部体素邻域内,(iii) 我们通过特征门控确定位置的特征表示。
这大大增加了模型的容量,而不会降低渲染速度或增加内存消耗:即使总存储需求随着子模型数量的增加而增加,渲染给定帧也只需要一个子模型。因此,当在图形加速器上实现时,我们的系统可以保持与 MERF 相当的适度资源需求。
坐标空间分区:虽然 MERF 提供了足够的容量来忠实地表现中等比例的场景,但我们发现使用一组三平面会限制其容量并降低图像质量。在大型场景中,许多表面点投影到同一个 2D 平面位置,因此表示难以同时表示多个表面的高频细节。尽管这可以通过提高基础表示的空间分辨率来部分改善,但这样做会显著影响内存消耗,并且在实践中成本过高。
相反,我们选择根据相机原点将场景粗略细分为 3D 网格,并以类似于 Block-NeRF 的策略将每个网格单元与一个独立的子模型相关联 [Tancik 等人,2022 年]。每个子模型都被分配了自己的收缩空间(方程(5))并被分配任务
以高细节表示其网格单元内的场景区域,而对每个子模型单元格外部的区域进行粗略建模。请注意,整个场景仍由每个子模型表示 - 子模型的区别仅在于场景的哪些部分位于每个子模型的收缩区域内部或外部。因此,渲染相机只需要一个子模型,这意味着一次只有一个子模型必须在内存中。
实验
我们通过将模型与两种最先进的方法进行比较来评估模型的性能和质量:3D 高斯飞溅 [Kerbl 等人,2023 年] 和 Zip-NeRF [Barron 等人,2023 年]。Zip-NeRF 可生成任何辐射场模型的最高质量重建,但速度太慢,无法在实时环境中使用,而 3DGS 渲染速度快,但质量低于 Zip-NeRF。我们表明,我们的模型(i)在强大的硬件上运行时可与3DGS相媲美,(ii)在各种商用设备上实时运行,以及(iii)比3DGS准确得多。我们的目标不是在质量方面超越 Zip-NeRF——它是我们模型的老师,代表了我们方法可实现质量的上限。
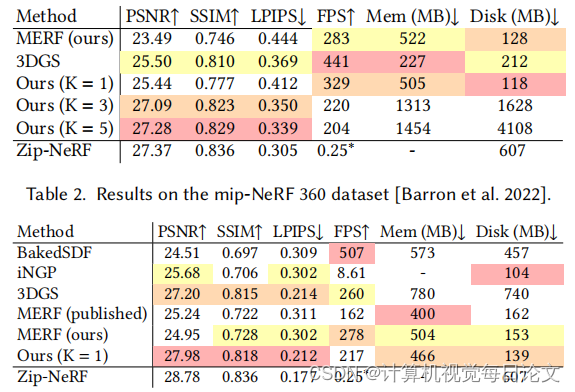

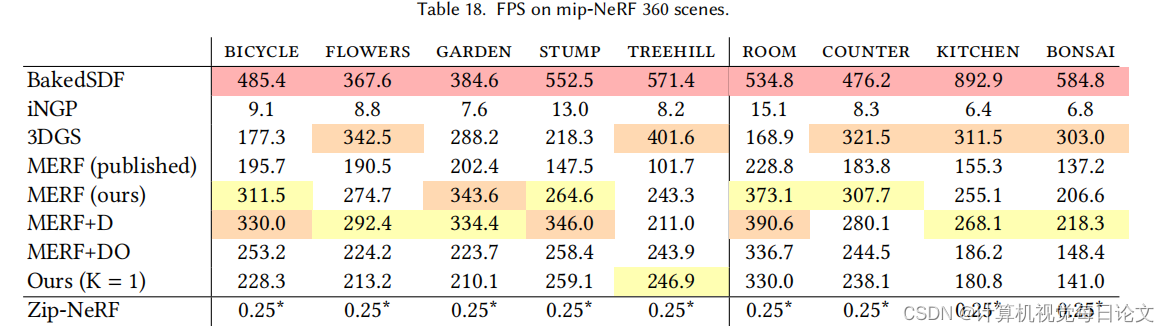
局限性。虽然我们的方法在质量和内存使用方面表现良好,但它的存储成本很高。在实时查看器中,这会导致加载事件和高网络使用率。我们的方法也会产生不小的培训成本:除了培训教师外,我们还根据数据集在 8 个 V100 或 16 个 A100 GPU 上优化了 100,000-200,000 步的方法。虽然我们的方法平均比3DGS达到更高的质量,但对于所有场景的所有部分,它的细节并不是普遍更高的。我们将其归因于我们的表示强加给场景的体素结构。
结论
我们提出了 SMERF,这是一种可流式传输的、内存效率高的辐射场表示,用于大型场景的实时视图合成。我们的方法在日常资源受限的消费类设备(包括智能手机和笔记本电脑)的网络浏览器中实时呈现。同时,它在中型和大型场景中都实现了比现有实时方法更高的质量,分别比现有最先进的 PSNR 高出 0.78 和 1.78 dB。
我们通过将高保真 Zip-NeRF 教师提炼成基于 MERF 构建的分层学生来实现这一目标。我们的方法将场景细分为独立的子模型,每个子模型进一步细分为一组延迟渲染网络。因此,渲染目标视图只需要一个子模型和一个延迟网络参数的局部邻域。我们进一步改进了 MERF 的查看器,将帧速率提高了 70% 以上。因此,内存和计算要求与 MERF 相当,同时显著提高质量和渲染速度。对于大型场景,我们的质量与Zip-NeRF几乎没有区别,Zip-NeRF是目前离线视图合成领域最先进的技术。我们鼓励读者在我们的项目网页上以互动方式探索 SMERF:https://smerf3d.github.io。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









