






 本文探讨了MetaCap如何通过元学习解决稀疏视图的人体捕捉与渲染问题,ObjectDrop通过反事实数据驱动逼真物体的去除和插入,以及Mini-Gemini如何挖掘多模态视觉语言模型的潜力以提升性能。这些创新方法在视觉和图形领域展现了突破性进展。
本文探讨了MetaCap如何通过元学习解决稀疏视图的人体捕捉与渲染问题,ObjectDrop通过反事实数据驱动逼真物体的去除和插入,以及Mini-Gemini如何挖掘多模态视觉语言模型的潜力以提升性能。这些创新方法在视觉和图形领域展现了突破性进展。
1、MetaCap: Meta-learning Priors from Multi-View Imagery for Sparse-view Human Performance Capture and Rendering
中文标题:MetaCap: 从多视角图像中元学习先验,用于稀疏视图人体性能捕捉和渲染
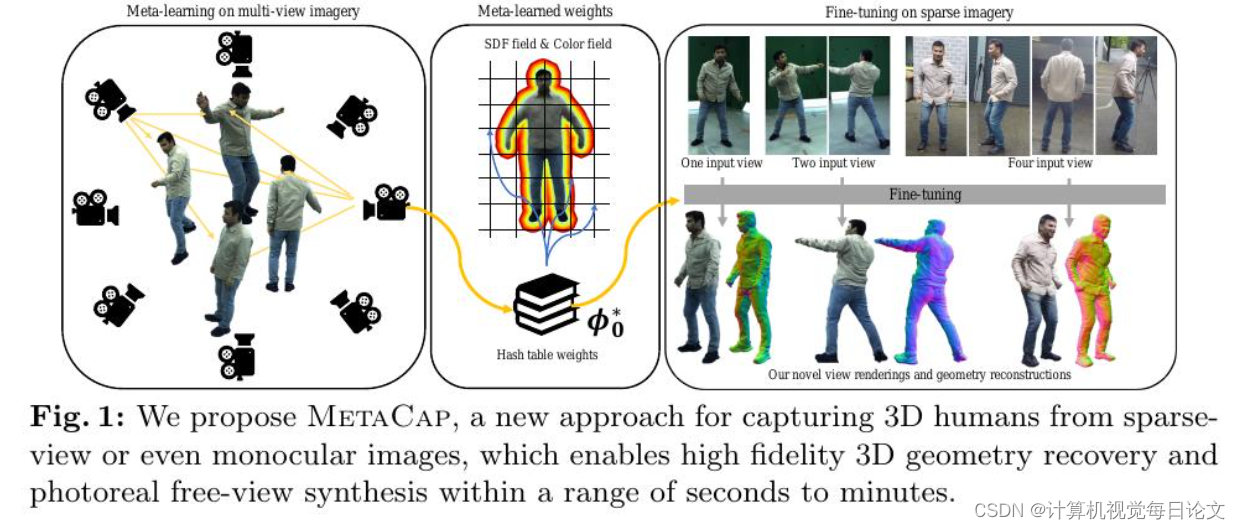
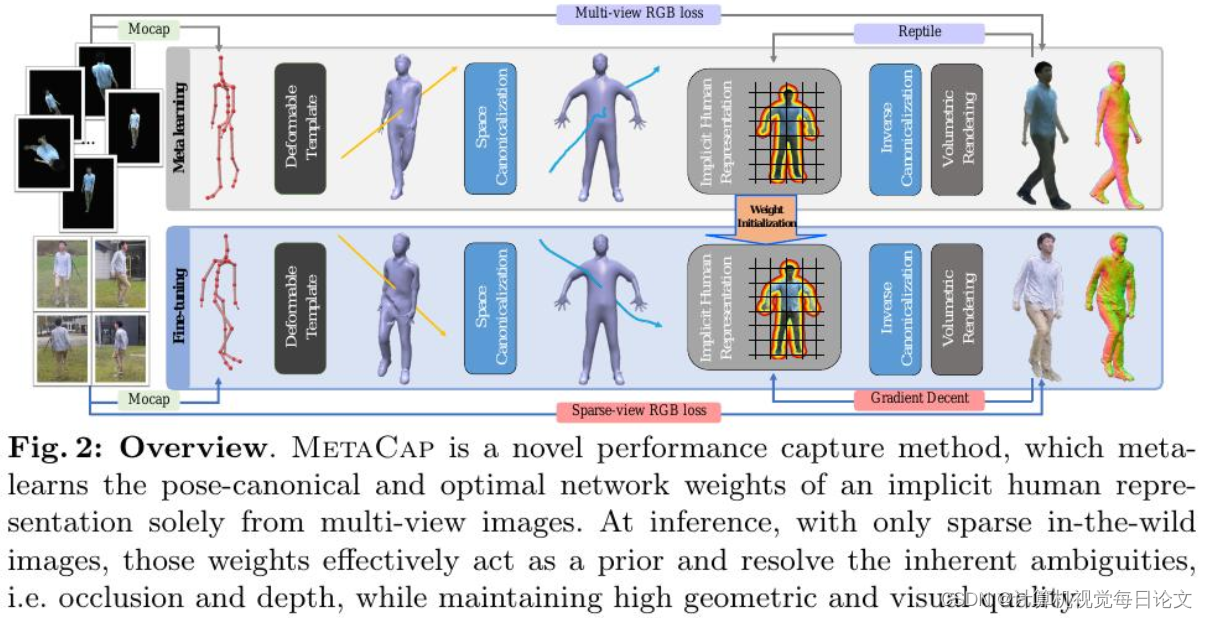
简介:忠实地捕捉人类表现并从稀疏的RGB观测中进行自由视角渲染一直是视觉和图形领域长期存在的问题。主要挑战在于缺乏观测和设置固有的歧义,比如遮挡和深度歧义。在稠密设置中,辐射场可以很好地捕捉高频外观和几何细节,但在稀疏的摄像机视图下进行纯监督时,辐射场的表现不佳,因为它会过度拟合稀疏视图输入。为了解决这个问题,提出了MetaCap,这是一种用于高效和高质量几何恢复和新视角合成的方法,即使只有非常稀疏或单个视角的人类图像。关键思想是仅从可能稀疏的多视角视频中元学习辐射场权重,这可以在将其微调到描述人类的稀疏图像上时作为先验。这种先验提供了良好的网络权重初始化,从而有效地解决了稀疏视图捕获中的歧义。由于人体的关节结构和运动引起的表面变形,学习这样的先验并不容易。因此,建议在姿势规范化空间中元学习场权重,这减少了空间特征范围并使特征学习更加有效。因此,可以微调我们的场参数以快速推广到看不见的姿势、新颖的照明条件以及新颖的稀疏(甚至单目)摄像机视图。为了评估方法在不同情况下的表现,收集了一个新的数据集,WildDynaCap,其中包含在密集的摄像机圆顶和野外稀疏摄像机设备中捕捉的主体,并在公共数据集和WildDynaCap数据集上展示了优于最近的最先进方法的结果。
2、ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion
中文标题:ObjectDrop: 用于逼真物体去除和插入的自举因果推断


简介:扩散模型已经彻底改变了图像编辑的方式,但通常会生成违反物理定律的图像,尤其是在涉及物体对场景的影响时,比如遮挡、阴影和反射。通过分析自我监督方法的局限性,我们提出了一个实用的解决方案,其中心是一个“反事实”数据集。我们的方法涉及在最小化其他变化的同时捕捉一个场景在移除单个物体之前和之后的情况。通过在这个数据集上微调扩散模型,我们不仅能够移除物体,而且还能够消除它们对场景的影响。然而,我们发现将这种方法应用于逼真的物体插入需要一个不切实际的大型数据集。为了解决这个问题,我们提出了引导式监督;利用我们在小型反事实数据集上训练的物体移除模型,我们可以合成大量的数据。我们的方法在逼真的物体移除和插入方面明显优于之前的方法,特别是在建模物体对场景的影响方面。
3、Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
中文标题:Mini-Gemini:挖掘多模态视觉语言模型的潜力

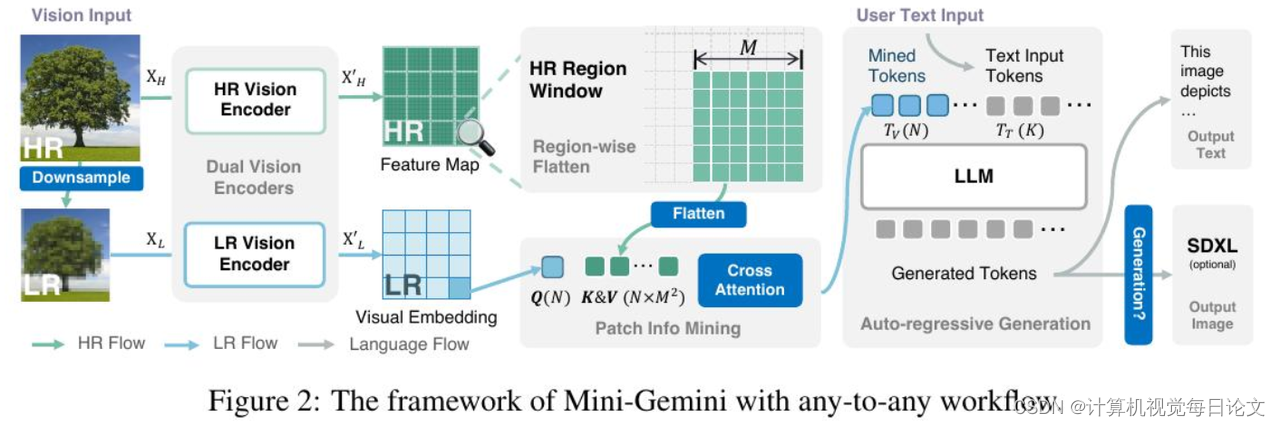
简介:在这项工作中,我们介绍了Mini-Gemini,这是一个简单而有效的框架,可以增强多模态视觉语言模型(VLMs)的性能。尽管VLMs在促进基本的视觉对话和推理方面取得了进展,但与高级模型如GPT-4和Gemini相比,仍存在性能差距。我们试图通过从三个方面挖掘VLMs的潜力以实现更好的性能和任意到任意的工作流程来缩小这一差距,即高分辨率视觉标记、高质量数据和VLM引导生成。为了增强视觉标记,我们提出利用额外的视觉编码器进行高分辨率细化,而不增加视觉标记数量。我们进一步构建了一个高质量的数据集,促进了精确的图像理解和基于推理的生成,扩大了当前VLMs的操作范围。总的来说,Mini-Gemini进一步挖掘了VLMs的潜力,并同时赋予了当前框架图像理解、推理和生成的能力。Mini-Gemini支持从2B到34B的一系列密集和MoE大型语言模型(LLMs)。在几个零样本基准测试中,它被证明能够取得领先的性能,甚至超过了开发的私有模型。代码和模型可在https://github.com/dvlab-research/MiniGemini获得。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









