






 本文介绍了三项关于深度学习在图像处理领域的突破:FactorizedDiffusion通过噪音分解创建感知错觉,InFusion通过深度学习修复3D高斯模型,以及IntrinsicAnything在未知照明下学习扩散先验进行逆渲染。这些方法展示了在图像分解、3D编辑和材质恢复方面的创新技术。
本文介绍了三项关于深度学习在图像处理领域的突破:FactorizedDiffusion通过噪音分解创建感知错觉,InFusion通过深度学习修复3D高斯模型,以及IntrinsicAnything在未知照明下学习扩散先验进行逆渲染。这些方法展示了在图像分解、3D编辑和材质恢复方面的创新技术。
1、Factorized Diffusion: Perceptual Illusions by Noise Decomposition
中文标题:分解扩散:噪音分解引起的感知错觉

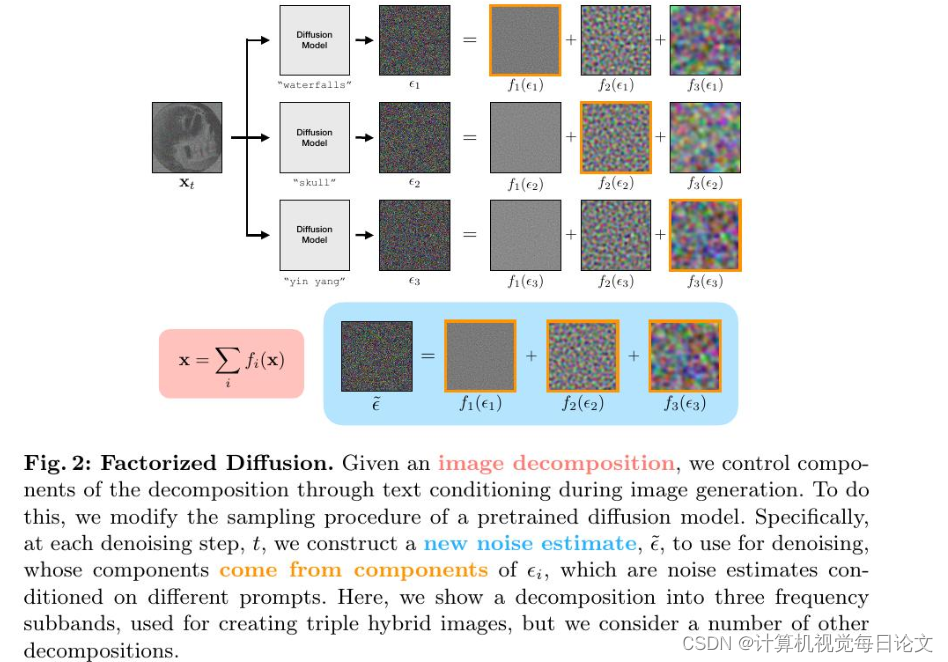
简介:我们提出了一种零样本方法,通过扩散模型采样来控制图像分解成线性分量的每个单独的分量。例如,我们可以将图像分解成低空间频率和高空间频率,并将这些分量置于不同的文本提示之下。这将产生混合图像,其外观随着观看距离的不同而改变。通过将图像分解为三个频率子带,我们可以生成具有三个提示的混合图像。我们还使用灰度和彩色分量的分解来产生在灰度下观看时外观发生变化的图像,这在昏暗的环境下自然发生。我们还探索了通过运动模糊核分解的方法,这种方法可以产生在运动模糊下外观发生变化的图像。我们的方法通过使用复合噪声估计进行去噪,该复合噪声估计由在不同提示下的噪声估计分量构建而成。我们还展示了对于某些分解,我们的方法恢复了先前的组合生成和空间控制方法。最后,我们展示了我们可以将我们的方法扩展到从真实图像生成混合图像。我们通过将一个分量固定并生成其余分量来解决一个反问题。
2、InFusion: Inpainting 3D Gaussians via Learning Depth Completion from Diffusion Prior
中文标题:InFusion: 通过从扩散先验学习深度完成对三维高斯进行修复

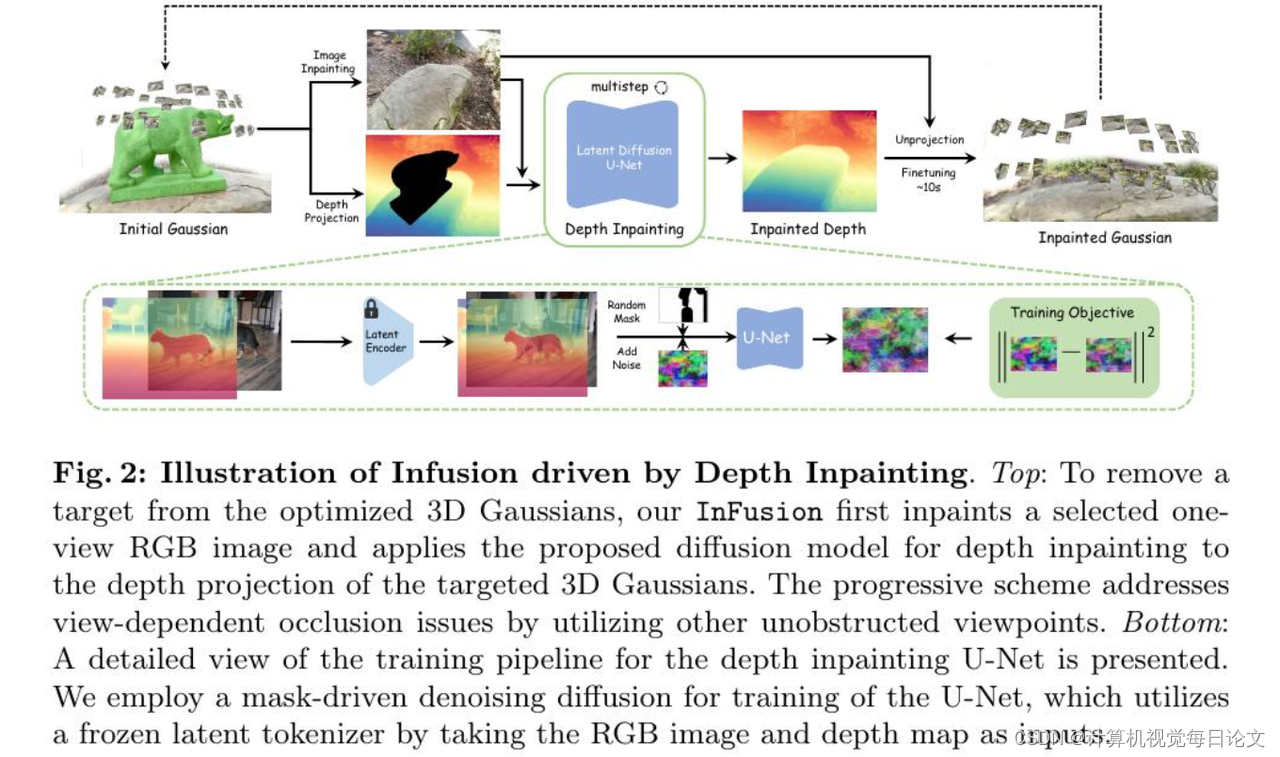
简介:最近,3D高斯模型已成为新视角合成的有效表示方法。本研究关注其可编辑性,特别关注修复任务,旨在通过添加额外点来补充不完整的3D高斯模型,以实现视觉上和谐的渲染。与2D修复相比,修复3D高斯模型的关键在于找出引入点的渲染相关属性,其优化很大程度上受益于它们的初始3D位置。为此,我们提出了一种基于图像条件深度完成模型的点初始化指导方法,该模型学习基于观察图像直接恢复深度图。这种设计使得我们的模型能够以与原始深度对齐的比例填充深度值,并从大规模扩散先验中获得强大的泛化能力。由于更准确的深度完成,我们的方法被称为InFusion,在各种复杂场景下具有足够更好的保真度和效率。我们进一步演示了InFusion的有效性,包括使用用户特定纹理进行修复或插入新对象进行修复等几个实际应用。
3、IntrinsicAnything: Learning Diffusion Priors for Inverse Rendering Under Unknown Illumination
中文标题:IntrinsicAnything:在未知照明下学习扩散先验以进行逆渲染"
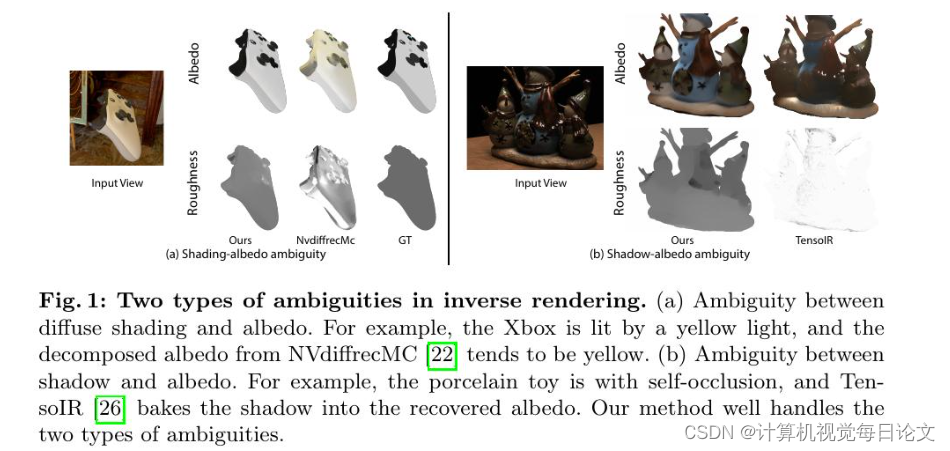

简介:这篇文章的目标是从在未知静态光照条件下拍摄的姿势图像中恢复物体的材质。最近的方法通过可微分的基于物理的渲染来优化材质参数以解决这一问题。然而,由于物体几何、材质和环境光照之间的耦合,反渲染过程中存在固有的模糊性,这妨碍了之前的方法获得准确的结果。为了克服这个不适定问题,我们的关键思想是使用生成模型学习材料先验,以规范化优化过程。我们观察到一般的渲染方程可以分为漫反射和镜面反射两个部分,因此将材料先验制定为反照率和镜面反射的扩散模型。由于这种设计,我们的模型可以使用现有丰富的三维物体数据进行训练,并自然地作为一种多功能工具,用于从RGB图像中恢复材质表示时解决模糊性。此外,我们开发了一种由粗到细的训练策略,利用估计的材料来指导扩散模型满足多视角一致性约束,从而产生更稳定和准确的结果。在真实世界和合成数据集上的广泛实验表明,我们的方法在材料恢复方面实现了最先进的性能。代码将在 https://zju3dv.github.io/IntrinsicAnything 上提供。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









