






1、Guess The Unseen: Dynamic 3D Scene Reconstruction from Partial 2D Glimpses
中文标题:猜测未见之景:从部分二维片段进行动态三维场景重建

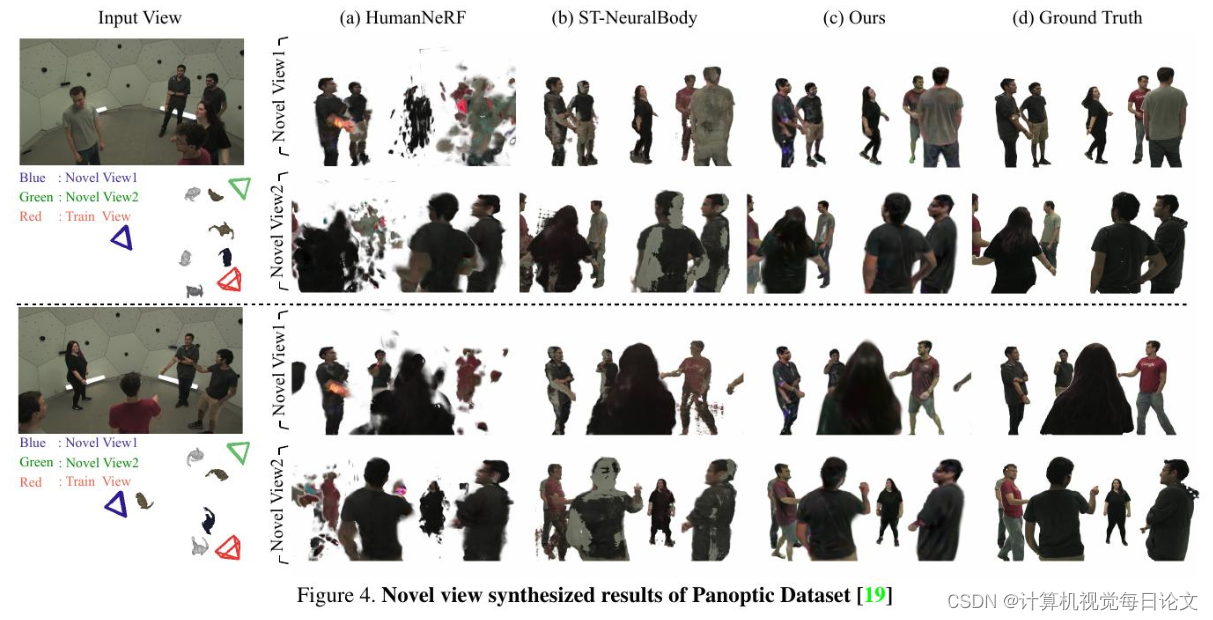
简介:这篇论文提出了一种方法,可以从单目视频输入中重建世界和多个动态人物的3D模型。该方法的关键思想是使用最新的3D高斯飞溅(3D-GS)表示法来表示世界和多个人物,以便方便地组合和渲染它们。特别是,作者解决了3D人体重建中常见的挑战,即受到严重限制和稀疏观察的情况。为了应对这一挑战,他们引入了一种新的方法,通过融合公共空间中的稀疏线索在规范空间中优化3D-GS表示法。作者利用预训练的2D扩散模型合成未见过的视图,同时保持与观察到的2D外观的一致性。作者展示了他们的方法在各种具有挑战性的示例中可以重建高质量的可动画3D人体,包括遮挡、图像裁剪、少量样本和极度稀疏的观察。重建后,他们的方法不仅能够在任意时间点渲染场景的任意新视图,还能通过删除单个人物或为每个人物应用不同的动作来编辑3D场景。通过各种实验,作者展示了他们的方法在质量和效率方面优于其他现有方法。
2、CrossScore: Towards Multi-View Image Evaluation and Scoring
中文标题:跨视图评估和打分

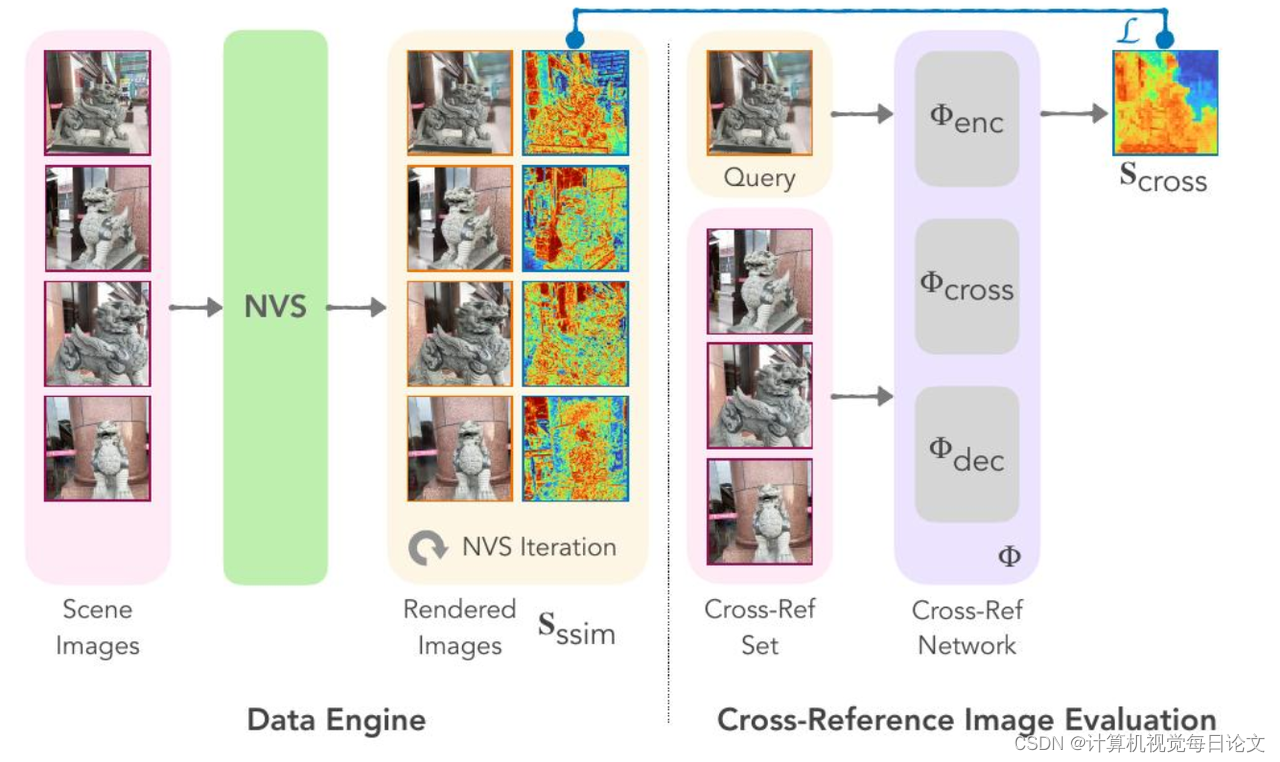
简介:我们提出了一种新颖的交叉参考图像质量评估方法,填补了图像评估领域的空白,补充了各种已建立的评估方案,包括全参考度量(如SSIM),无参考度量(如NIQE),以及一般参考度量(包括FID)和多模态参考度量(例如CLIPScore)。我们的方法利用具有交叉注意机制和独特数据收集管道的神经网络,能够在不需要基准参考的情况下实现准确的图像质量评估。通过将查询图像与同一场景的多个视图进行比较,我们的方法解决了现有度量在新视角合成(NVS)和类似任务中直接参考图像不可用的限制。实验结果表明,我们的方法与全参考度量SSIM密切相关,同时不需要基准参考。
3、GeoDiffuser: Geometry-Based Image Editing with Diffusion Models
中文标题:GeoDiffuser:基于几何的扩散模型图像编辑

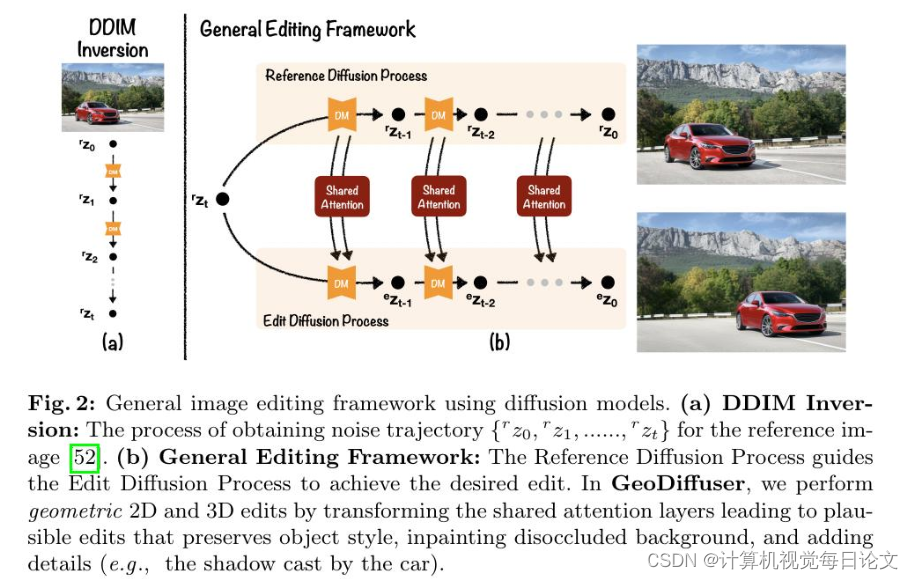
简介:成功的图像生成模型使我们能够开发基于文本或其他用户输入的图像编辑方法。然而,这些方法通常是定制的、不够精确、需要额外信息或仅适用于2D图像编辑。我们提出了GeoDiffuser,这是一种零样本基于优化的方法,将常见的2D和3D基于图像的对象编辑功能统一到一个方法中。我们的关键见解是将图像编辑操作视为几何变换。我们展示了这些变换可以直接并入扩散模型中的注意力层中,以隐式地执行编辑操作。我们的无需训练的优化方法使用一个目标函数,该函数旨在保持对象样式但生成合理的图像,例如具有准确的照明和阴影。它还可以修复图像中原本位于对象位置的不连续部分。给定自然图像和用户输入,我们使用SAM分割前景对象并估计相应的变换,该变换由我们的优化方法用于编辑。GeoDiffuser可以执行常见的2D和3D编辑,如对象平移、3D旋转和去除。我们提供了定量结果,包括感知研究,展示了我们的方法比现有方法更好。请访问https://ivl.cs.brown.edu/research/geodiffuser.html了解更多信息。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









