







HDFS简介
Hadoop Distributed File System (HDFS): HDFS 是 Hadoop 的分布式文件系统,它设计用于存储大量数据,并提供 高吞吐率的数据访问,通过将数据分块存储在多个节点上,实现数据的冗余存储和容错。
HDFS重要概念
HDFS 通过统一的命名空间目录树来定位文件; 另外,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色(分布式本质是拆分,各司其职)。
- 典型的Master/Slave架构
HDFS集群往往是一个NameNode(HA架构会有两个NameNode,联邦机制)+多个DataNode组成。
- 分块存储(block机制)
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定。
- 命名空间(NameSpace)
HDFS 支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动。
Namenode 负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被
Namenode 记录下来。
- NameNode元数据管理
NameNode负责存储文件的元数据,比如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode数据存储
DataNode是HDFS的工作节点,负责存储实际的用户数据。每个DataNode都会向NameNode注册自己的存储能力,并定期报告自己的状态和已存储的数据块信息。
- 副本机制
HDFS 中的文件在物理上是分块存储(block)的,每个block通过副本机制来保证其高可用性。
HDFS会自动维护数据块的副本数量,确保数据的高可靠性。
如果某个副本丢失,NameNode会根据当前的网络状况和数据块的副本分布,选择一个合适的DataNode来创建新的副本。
如果某个DataNode失效,NameNode会重新分配其存储的数据块到其他健康的DataNode上。
- 数据一致性
HDFS使用Write-Once-Read-Many(WORM)模型,确保数据一旦被写入就不能被修改。
在写操作中,NameNode确保所有的副本在提交前都已经成功创建,从而保证数据的一致性。
在读操作中,客户端可以从任何一个副本读取数据,但NameNode会确保客户端获取的是最新的数据版本。
HDFS架构
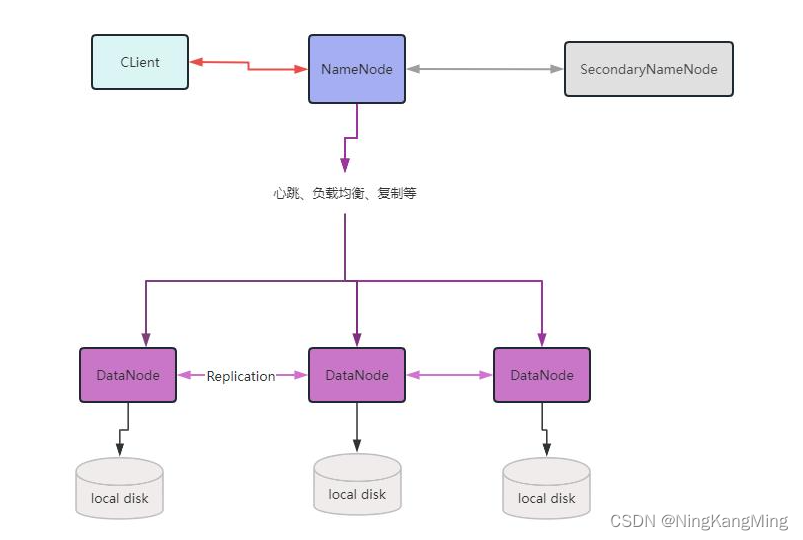
NameNode(nn):存储文件的元数据,比如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
SecondaryNameNode(2nn):辅助NameNode更好的工作,用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据快照。
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验。















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









