






大多数程序员对程序代码如何转换为机器代码以及微处理器如何处理这些代码几乎没有了解。例如,许多程序员不知道双精度计算与单精度计算的速度是一样快的。谁会知道模板类比多态类更高效呢?
本章旨在解释不同C++语言元素的相对效率,以帮助程序员选择最高效的替代方案。其他手册系列中的其他卷进一步解释了理论背景。
7.1 Different kinds of variable storage
根据在C++程序中的声明方式,变量和对象存储在内存的不同部分。这对数据缓存的效率有影响(参见第91页)。如果数据在内存中随机散布,数据缓存效果会较差。因此,了解变量的存储方式非常重要。对于简单变量、数组和对象,存储原则是相同的。
在栈上的存储
在函数内部声明的变量和对象存储在栈上,除非以下各节中另有说明。
栈是按照先进后出的方式组织的内存的一部分。它用于存储函数返回地址(即函数被调用的位置)、函数参数、局部变量,并保存在函数返回前需要恢复的寄存器。每次调用函数时,它会为所有这些目的分配所需的堆栈空间。当函数返回时,该内存空间将被释放。下次调用函数时,它可以使用相同的空间来存储新函数的参数。
栈是存储数据的最高效的内存空间,因为相同的内存地址范围被反复重用。如果没有大型数组,几乎可以确定该内存的一部分被镜像到一级数据缓存中。
我们可以从中得到的教训是,所有变量和对象最好在使用它们的函数内部声明。
通过在{}括号内声明变量,甚至可以使变量的作用域更小。然而,大多数编译器直到函数返回时才会释放变量使用的内存,即使在声明变量的{}括号中退出时可以释放内存。如果变量存储在寄存器中(见下文),那么它可能在函数返回之前被释放。
全局或静态存储
在任何函数外声明的变量被称为全局变量。它们可以从任何函数中访问。全局变量存储在内存的静态部分中。静态内存也用于使用static关键字声明的变量、浮点常量、字符串常量、数组初始化列表、switch语句跳转表和虚函数表。
静态数据区通常分为三个部分:一个用于程序永远不会修改的常量,一个用于可能会被程序修改的初始化变量,一个用于可能会被程序修改的未初始化变量。
静态数据的优点是可以在程序启动之前将其初始化为所需值。缺点是在整个程序执行期间,该内存空间被占用,即使变量仅在程序的一小部分中使用。这使得数据缓存效率降低,因为内存空间不能用于其他目的。
如果可以避免,尽量不要使用全局变量。全局变量可能在不同线程之间需要进行通信,但这几乎是唯一无法避免的情况。如果一个变量被多个不同的函数访问,并且你想避免将变量作为函数参数传递的开销,将该变量设置为全局变量可能有用。但更好的解决方案可能是将访问共享变量的函数作为同一类的成员,并将共享变量存储在类内部。哪种解决方案更好取决于编程风格。
最好将查找表声明为静态和常量。例子:
// Example 7.1
float SomeFunction (int x) {
static const float list[] = {1.1, 0.3, -2.0, 4.4, 2.5};
return list[x];
}这样做的好处是每次调用函数时不需要初始化列表。静态声明帮助编译器决定可以从一次调用中重复使用表格到下一次调用。 const声明帮助编译器了解表格永远不会改变。在函数内部初始化变量上使用静态声明意味着变量在第一次调用函数时必须进行初始化,但在随后的调用中不会进行初始化。这很低效,因为函数需要额外的开销来检查它是第一次调用还是之前已经调用过。const声明有助于编译器决定是否需要进行第一次调用的检查。一些编译器仍然能够优化查找表,但最好将static和const都放在查找表上,以便在所有编译器上优化性能。
字符串常量和浮点常量通常存储在静态内存中。例子:
// Example 7.2
a = b * 3.5;
c = d + 3.5;在这里,常量3.5将存储在静态内存中。大多数编译器将识别出这两个常量是相同的,因此只需要存储一个常量。整个程序中的所有相同常量将被合并在一起,以最小化用于常量的缓存空间。
整数常量通常作为指令代码的一部分包含在内。您可以假设整数常量没有缓存问题。
寄存器存储
有限数量的变量可以存储在寄存器而不是主内存中。寄存器是CPU内部用于临时存储的小块内存。存储在寄存器中的变量访问非常快速。所有优化编译器都会自动选择函数中最常用的变量进行寄存器存储。只要它们的使用范围不重叠,同一个寄存器可以用于多个变量。
局部变量特别适合寄存器存储。这是偏爱局部变量的另一个原因。
寄存器的数量是有限的。在32位x86操作系统中,大约有六个整数寄存器可供通用目的使用,在64位系统中有十四个整数寄存器。
浮点变量使用一种不同类型的寄存器。在32位操作系统中,有八个浮点寄存器可用,而在64位操作系统中有十六个,在启用64位模式下的AVX512指令集时有三十二个。在32位模式下,一些编译器在没有启用SSE指令集(或更高级别)时可能难以创建浮点寄存器变量。
易失性变量
volatile关键字指定变量可以被另一个线程更改。这可以防止编译器进行依赖于变量始终具有代码中先前分配的值的假设的优化。例如:
// Example 7.3. Explain volatile
volatile int seconds; // incremented every second by another thread
void DelayFiveSeconds() {
seconds = 0;
while (seconds < 5) {
// do nothing while seconds count to 5
}
}在这个例子中,DelayFiveSeconds函数会等待直到seconds变量被另一个线程增加到5。如果没有声明volatile关键字,优化编译器会假设在while循环中seconds保持为零,因为循环内部没有任何东西可以改变这个值。循环将是 while (0 < 5) {},即一个无限循环。
volatile关键字的作用是确保变量存储在内存中而不是寄存器中,并阻止对该变量的所有优化。这在测试情况下非常有用,以避免某些表达式被优化掉。
需要注意的是,volatile并不意味着原子性。它不能阻止两个线程同时尝试写入同一变量。在上述例子中,如果在设置seconds为零的同时另一个线程增加了seconds,代码可能会失败。更安全的实现方法是只读取seconds的值,并等待该值变化了五次。
线程本地存储(Thread-local storage,TLS)
大多数编译器可以通过使用关键字thread_local、__thread或__declspec(thread)将静态和全局变量存储为线程本地存储。这些变量对于每个线程都有一个实例。线程本地存储通过在线程环境块中存储的指针进行访问,因此效率较低。如果可能的话,应避免使用静态线程本地存储,并将其替换为存储在线程自己的堆栈上(参见上面,第25页)。在线程函数中声明的非静态变量和对象,或者在任何被线程函数调用的函数中声明的变量和对象,将被存储在线程的堆栈上。这些变量和对象将对每个线程有一个单独的实例。在大多数情况下,可以通过在线程函数内部声明变量或对象来避免使用静态线程本地存储。
远数据段(far data segment)
具有分段内存的系统(例如旧版DOS和16位Windows)允许使用关键字far将变量存储在远数据段中(DOS数组也可以是huge)。远程存储、远程指针和远程过程效率较低。如果程序的数据量超过一个段,则建议使用允许更大段的不同操作系统(32位或64位系统)。
动态内存分配
动态内存分配是通过new和delete运算符或malloc和free函数来实现的。这些运算符和函数会消耗大量时间。一个称为堆(heap)的内存部分被保留用于动态分配。当以随机顺序分配和释放不同大小的对象时,堆很容易变得碎片化。堆管理器可能会花费大量时间清理不再使用的空间并搜索空闲空间。这称为垃圾回收。按顺序分配的对象在内存中不一定顺序存储。当堆已经碎片化时,它们可能散布在不同的位置。这导致数据缓存效率低下。
动态内存分配也倾向于使代码更加复杂和容易出错。程序必须保持对所有分配的对象的指针,并在不再使用时进行跟踪。在程序流程的所有可能情况下都必须将所有分配的对象进行解分配是非常重要的。否则,未完成解分配是一个常见的错误来源,称为内存泄漏。更糟糕的错误是在解分配后访问对象。程序逻辑可能需要额外的开销来防止此类错误。
关于使用动态内存分配的优势和缺点的进一步讨论请参见第95页。
一些编程语言,如Java,对所有对象使用动态内存分配。这当然是低效的。
在类内声明的变量
在类内声明的变量按照它们在类声明中出现的顺序进行存储。存储类型在声明类的对象时确定。类、结构体或联合的对象可以使用上述任何一种存储方式。除非是最简单的情况,否则对象不能存储在寄存器中,但它的数据成员可以被复制到寄存器中。
具有static修饰符的类成员变量将存储在静态内存中,并且只有一个实例。同一个类的非静态成员将与类的每个实例一起存储。
将变量存储在类或结构体中是确保在程序的同一部分使用的变量也被存储在彼此附近的好方法。关于使用类的利弊,请参见第52页。
7.2 Integers variables and operators
Integer sizes
整数可以有不同的大小,并且它们可以是有符号或无符号的。以下表格总结了可用的不同整数类型。
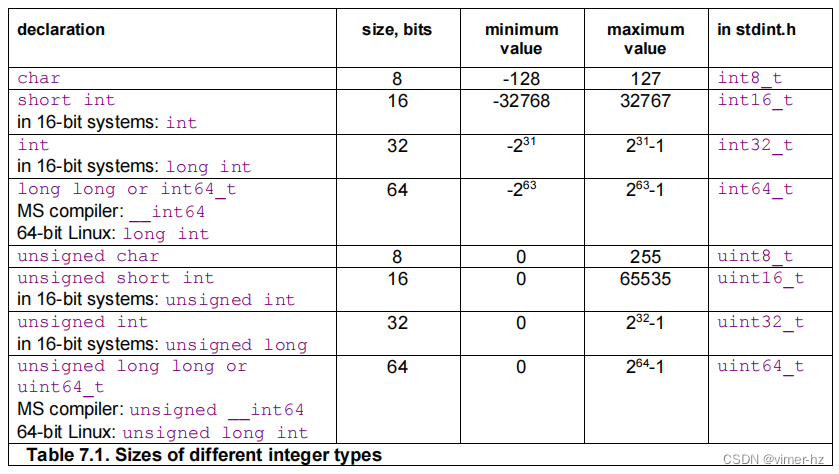
不幸的是,根据上表所示,声明特定大小整数的方式因平台而异。推荐使用标准头文件stdint.h或inttypes.h来定义特定大小的整数类型的可移植方法。
大多数情况下,无论大小,整数操作都是快速的。然而,使用大于最大可用寄存器大小的整数尺寸是低效的。换句话说,在16位系统中使用32位整数或在32位系统中使用64位整数是低效的,特别是如果代码涉及乘法或除法。
如果您声明一个int而没有指定大小,编译器总是会选择最有效的整数大小。较小大小的整数(char、short int)只是稍微低效。在许多情况下,编译器将在进行计算时将这些类型转换为默认大小的整数,然后仅使用结果的低8位或16位。可以假设类型转换需要零个或一个时钟周期。在64位系统中,只要不进行除法运算,32位整数和64位整数的效率几乎没有差异。
在不需要考虑大小且没有溢出风险的情况下,建议使用默认整数大小,例如简单变量、循环计数器等。在大数组中,可能更倾向于使用足够大以满足特定目的的最小整数大小,以更好地利用数据缓存。除8、16、32和64位之外的其他位域大小效率较低。在64位系统中,如果应用程序可以利用额外的位数,可以使用64位整数。
无符号整数类型size_t在32位系统中为32位,在64位系统中为64位。它适用于数组大小和数组索引,当您希望确保即使对于超过2GB的数组也不会发生溢出时使用。
在考虑某个特定整数大小是否足够满足特定目的时,必须考虑中间计算是否会导致溢出。例如,在表达式a = (b*c)/d中,即使a、b、c和d都在最大值以下,(b*c)仍可能溢出。没有自动检查整数溢出的机制。
Signed versus unsigned integers
在大多数情况下,使用有符号和无符号整数之间的速度没有区别。但是,有一些情况是有影响的:
• 除以常数:当您将一个整数除以一个常数时(请参见第150页),无符号的速度比有符号的快。这也适用于取模运算符%。
• 对于大多数指令集,将有符号整数转换为浮点数比将无符号整数转换为浮点数更快。
• 溢出在有符号和无符号变量上表现不同。无符号变量的溢出会产生一个较低的正结果。有符号变量的溢出在正式意义上是未定义的。正溢出的正常行为是将其环绕到一个负值,但编译器可能会基于溢出不会发生的假设优化依赖于溢出的分支。
有符号和无符号整数之间的转换是无代价的。它只是解释相同位不同的方式。当转换为无符号时,负整数将被解释为一个非常大的正整数。
// Example 7.4. Signed and unsigned integers
int a, b;
double c;
b = (unsigned int)a / 10; // Convert to unsigned for fast division
c = a * 2.5; // Use signed when converting to double在示例7.4中,我们将a转换为无符号整数,以加快除法运算的速度。当然,这只有在确保a永远不会为负数时才有效。最后一行在乘以常数2.5(double)之前会将a隐式转换为double。在这种情况下,我们更喜欢a是有符号的。
请确保不要在比较中混合使用有符号和无符号整数,例如“<”。将有符号整数与无符号整数进行比较的结果是不明确的,并且可能产生不希望的结果。
Integer operators
整数操作通常非常快速。对于大多数微处理器而言,简单的整数操作,如加法、减法、比较、位操作和移位操作,只需一个时钟周期。
乘法和除法需要更长的时间。在Pentium 4处理器上,整数乘法需要11个时钟周期,在大多数其他微处理器上需要3-4个时钟周期。整数除法需要40-80个时钟周期,取决于微处理器。在AMD处理器上,整数除法随着整数大小变小而更快,但在Intel处理器上不是这样。关于指令延迟的详细信息请参阅手册4:“指令表”。有关如何加快乘法和除法的提示分别在第149页和第150页列出。
Increment and decrement operators
前置递增运算符++i和后置递增运算符i++与加法一样快。当仅用于递增整数变量时,使用前置递增和后置递增没有区别。效果完全相同。例如,
for (i=0; i<n; i++) 与 for (i=0; i<n; ++i) 是相同的。但是,当表达式的结果被使用时,效率可能会有所不同。例如,
x = array[i++] 比 x = array[++i] 更高效,因为在后一种情况下,数组元素地址的计算必须等待i的新值,这将延迟x的可用性约两个时钟周期。显然,如果将前置递增改为后置递增,则必须调整i的初始值。
也有一些情况下,前置递增比后置递增更高效。例如,在 a = ++b 的情况下,编译器将识别出在此语句之后,a和b的值相同,因此可以同时使用相同的寄存器;而表达式 a = b++ 则会使a和b的值不同,因此它们不能使用同一个寄存器。
这里所说的关于递增运算符的所有内容也适用于整数变量上的递减运算符。
7.3 Floating point variables and operators
x86系列现代微处理器具有两种不同类型的浮点寄存器,相应地也有两种不同类型的浮点指令。每种类型都有其优缺点。
原始的浮点操作方法使用八个浮点寄存器,组织成一个寄存器栈,称为x87寄存器。这些寄存器具有长双精度(80位)。使用寄存器栈的优点包括:
• 所有计算都以长双精度进行。
• 不同精度之间的转换不需要额外的时间。
• 存在用于数学函数(如对数和三角函数)的内部指令。
• 代码紧凑,在代码缓存中占用空间较小。
寄存器栈也存在一些缺点:
• 由于寄存器栈的组织方式,编译器很难生成寄存器变量。
• 浮点比较速度较慢。
• 整数与浮点数之间的转换效率低。
• 使用长双精度时,除法、平方根和数学函数的计算时间更长。
一种较新的浮点操作方法使用矢量寄存器(XMM、YMM或ZMM),可用于多种用途。浮点操作以单精度或双精度进行,中间结果始终与操作数具有相同的精度。使用矢量寄存器的优点包括:
• 可以轻松生成浮点寄存器变量。
• 可以使用矢量操作在矢量寄存器中对多个变量进行并行计算(见第115页)。
缺点包括:
• 不支持长双精度。
• 具有混合精度操作数的表达式计算需要进行精度转换指令,这可能非常耗时(见第153页)。
• 数学函数必须使用函数库,但这通常比内置硬件函数更快。
x87浮点寄存器在所有具有浮点运算功能的系统中都可用(除了64位Windows的设备驱动程序)。XMM、YMM和ZMM寄存器分别需要SSE、AVX和AVX512指令集。有关如何测试这些指令集的可用性,请参见第135页。
现代编译器会在可用时,即在64位模式下或启用了SSE或更高指令集时,使用矢量寄存器进行浮点计算。很少有编译器能够混合使用这两种类型的浮点操作,并选择对每个计算最优的类型。
在大多数情况下,只要双精度计算没有被合并成矢量,它们所花费的时间不会比单精度计算更多。当使用XMM寄存器时,单精度除法、平方根和数学函数的计算速度比双精度更快,而加法、减法、乘法等的速度在大多数处理器上无论精度如何都是相同的,当不使用矢量操作时。
如果双精度对应用程序有利,您可以放心使用它而不必过于关注成本。如果您有大型数组并希望尽可能多地将数据加载到数据缓存中,可以使用单精度。如果您可以利用矢量操作,如第115页所述,那么单精度是很好的选择。如果处理器支持AVX512-FP16指令集扩展,可以使用半精度。
浮点加法需要2至6个时钟周期,这取决于微处理器。乘法需要3至8个时钟周期。除法需要14至45个时钟周期。当使用旧的x87浮点寄存器时,浮点比较和浮点转换为整数都效率低下。
请勿在同一表达式中混合使用单精度和双精度。请参见第153页。
如果可能的话,避免在整数和浮点变量之间进行转换。请参见第153页。
在矢量寄存器中生成浮点下溢的应用程序可以受益于将flush-to-zero模式设置为在下溢时生成非规范化数,而不是生成次规范化数。
// Example 7.5. Set flush-to-zero mode (SSE):
#include <xmmintrin.h>
_MM_SET_FLUSH_ZERO_MODE(_MM_FLUSH_ZERO_ON);强烈建议设置flush-to-zero模式,除非您有使用次规范化数的特殊原因。如果可用矢量寄存器,您还可以设置denormals-are-zero模式:
// Example 7.6. Set flush-to-zero and denormals-are-zero mode (SSE2):
#include <xmmintrin.h>
_mm_setcsr(_mm_getcsr() | 0x8040);有关数学函数的更多信息,请参见第131页和第158页。
7.4 Enums
枚举类型只是整数的伪装。枚举类型和整数完全一样高效。
请注意,枚举值名称将与任何具有相同名称的变量或函数发生冲突。因此,在头文件中使用的枚举值应该具有长且唯一的名称,或者应该放置在一个命名空间中。
7.5 Booleans
The order of Boolean operands
逻辑运算符 && 和 || 的操作数的求值方式如下所示。如果 && 的第一个操作数为 false,那么根据第一个操作数的结果,不需要对第二个操作数进行求值,因为结果已经确定为 false。同样地,如果 || 的第一个操作数为 true,那么不需要对第二个操作数进行求值,因为结果已经确定为 true。
在 && 表达式中,将最可能为 true 的操作数放在最后,或者在 || 表达式中将其放在最前面,可能会有优势。例如,假设 a 在50%的情况下为 true,而 b 在10%的情况下为 true。当 a 为 true 时,表达式 a && b 需要对 b 进行求值,这发生在50%的情况下。而等效的表达式 b && a 只需要在 b 为 true 时对 a 进行求值,这只发生在10%的情况下。如果 a 和 b 的求值时间相同,并且被分支预测机制同样可能预测正确,那么这种交换方式会更快速。关于分支预测的解释,请参见第43页。
如果一个操作数比另一个更容易预测,那么将最可预测的操作数放在最前面。
如果一个操作数的计算速度比另一个快,那么将最快计算的操作数放在最前面。
然而,在交换布尔操作数的顺序时,必须要小心。如果操作数的求值具有副作用,或者第一个操作数决定了第二个操作数是否有效,那么就不能交换操作数的顺序。例如:
// Example 7.7
unsigned int i; const int ARRAYSIZE = 100; float list[ARRAYSIZE];
if (i < ARRAYSIZE && list[i] > 1.0) { ...在这里,你不能交换操作数的顺序,因为当 i 不小于 ARRAYSIZE 时,表达式 list[i] 是无效的。另一个示例:
// Example 7.8
if (handle != INVALID_HANDLE_VALUE && WriteFile(handle, ...)) { ...在这里,你不能交换布尔操作数的顺序,因为如果句柄是无效的,则不应调用 WriteFile。
Boolean variables are overdetermined
//布尔变量是过度确定的。
布尔变量以 8 位整数形式存储,false 的值为 0,true 的值为 1。布尔变量是过度确定的,因为所有的以布尔变量为输入的操作符都会检查输入是否具有除 0 或 1 之外的其他值,但是以布尔值为输出的操作符只能产生 0 或 1。这使得以布尔变量为输入的操作不够有效。例如:
// Example 7.9a
bool a, b, c, d;
c = a && b;
d = a || b;通常情况下,编译器会按照以下方式实现:
bool a, b, c, d;
if (a != 0) {
if (b != 0) {
c = 1;
}
else {
goto CFALSE;
}
}
else {
CFALSE:
c = 0;
}
if (a == 0) {
if (b == 0) {
d = 0;
}
else {
goto DTRUE;
}
}
else {
DTRUE:
d = 1;
}这显然远非最优解。如果出现分支预测错误的情况,分支将要花费很长时间(请参见第43页)。如果可以确定操作数仅具有 0 和 1 值,布尔运算可以变得更加高效。编译器不做出这种假设的原因是,如果变量未初始化或来自未知来源,则变量可能具有其他值。如果已经将 a 和 b 初始化为有效值,或者它们来自生成布尔输出的操作符,则可以对上述代码进行优化。优化后的代码如下所示:
// Example 7.9b
char a = 0, b = 0, c, d;
c = a & b;
d = a | b;为了能够使用按位运算符(& 和 |)而不是布尔运算符(&& 和 ||),我在这里使用了 char(或 int)而不是 bool。按位运算符是单个指令,仅需一个时钟周期。即使 a 和 b 具有除 0 或 1 之外的其他值,OR 运算符(|)也可以正常工作。如果操作数具有除 0 和 1 之外的其他值,AND 运算符(&)和 EXCLUSIVE OR 运算符(^)可能会产生不一致的结果。
请注意,这里存在一些注意事项。你不能使用 ~ 进行取反操作。相反,你可以通过将已知为 0 或 1 的变量与 1 进行异或操作来实现布尔的 NOT 操作:
// Example 7.10a
bool a, b;
b = !a;can be optimized to:
// Example 7.10b
char a = 0, b;
b = a ^ 1;如果 b 是一个在 a 为 false 时不应该被计算的表达式,那么你不能用 a & b 替换 a && b。同样地,如果 b 是一个在 a 为 true 时不应该被计算的表达式,你不能用 a | b 替换 a || b。
使用按位运算符的技巧在操作数为变量时比操作数为比较等更加有优势。例如:
// Example 7.11
bool a; float x, y, z;
a = x > y && z != 0;在大多数情况下,这是最优的做法。除非你预计 && 表达式会生成许多分支预测错误,否则不要将 && 更改为 &。
Boolean vector operations
整数可以用作布尔向量。例如,如果 a 和 b 是32位整数,那么表达式 y = a & b; 将在一个时钟周期内进行32次 AND 操作。运算符 &、|、^、~ 对于布尔向量操作非常有用。
7.6 Pointers and references
Pointers versus references
指针和引用在效率上是一样的,因为它们实际上正在做相同的事情。例如:
// Example 7.12
void FuncA (int * p) {
*p = *p + 2;
}
void FuncB (int & r) {
r = r + 2;
}这两个函数做的事情是相同的,如果你查看编译器生成的代码,你会注意到两个函数的代码完全相同。差别只是编程风格的问题。与引用相比,使用指针的优点有:
• 从上面的函数体中可以清楚地看出 p 是一个指针,但是你不确定 r 是一个引用还是一个简单变量。使用指针可以更清晰地告诉读者正在发生什么。
• 可以使用指针做一些引用无法实现的事情。你可以更改指针所指向的位置,并且可以对指针执行算术运算。
使用引用而不是指针的优点是:
• 使用引用时语法更简单。
• 引用比指针更安全,因为大多数情况下它们肯定指向有效地址。如果指针未初始化、指针算术计算超出了有效地址范围或者指针被强制转换为错误类型,指针可能无效并导致致命错误。
• 引用对于复制构造函数和重载运算符很有用。
• 声明为常量引用的函数参数接受表达式作为参数,而指针和非常量引用需要一个变量作为参数。
Efficiency
通过指针或引用访问变量或对象与直接访问它一样快速。这种效率的原因在于微处理器的构造方式。在函数内部声明的所有非静态变量和对象都存储在堆栈上,并且实际上是相对于堆栈指针进行寻址的。同样,类中声明的所有非静态变量和对象都通过隐式指针(在C++中称为 "this")进行访问。因此,我们可以得出结论,在良好结构化的C++程序中,大多数变量实际上都以某种方式通过指针进行访问。因此,微处理器必须设计成使指针高效,这也正是它们的用途。
然而,使用指针和引用也有缺点。最重要的是,它需要额外的寄存器来保存指针或引用的值。寄存器是一种有限的资源,特别是在32位模式下。如果寄存器不足,则每次使用指针时都必须从内存中加载,这会使程序变慢。另一个缺点是,在可以访问指向的变量之前,需要几个时钟周期来获取指针的值。
Pointer arithmetic
指针实际上是一个保存内存地址的整数。因此,指针算术运算与整数算术运算一样快速。当将一个整数与指针相加时,它的值会乘以所指向对象的大小。例如:
// Example 7.13
struct abc {int a; int b; int c;};
abc * p; int i;
p = p + i;在这里,添加到 p 的值不是 i,而是 i*12,因为 abc 的大小为 12 字节。将 i 添加到 p 需要的时间与进行乘法和加法运算的时间相等。如果 abc 的大小是2的幂次方,则可以用移位操作替代乘法,移位操作速度更快。在上面的示例中,通过向结构体添加一个整数,可以将 abc 的大小增加到16字节。
递增或递减一个指针只需要进行加法操作,而不需要乘法。比较两个指针只需要进行整数比较,速度很快。
计算两个指针之间的差异需要进行除法,除非所指对象的类型大小是2的幂次方(关于除法请参见第150页)。
在计算出指针的值后,可以大约在两个时钟周期后访问所指对象。因此,建议在使用指针之前提前计算指针的值。例如,x = *(p++) 比 x = *(++p) 更高效,因为在后一种情况下,必须等待直到指针 p 增加了几个时钟周期后才能读取 x,而在前一种情况下,在增加 p 之前就可以读取 x 。有关递增和递减运算符的更多讨论,请参见第31页。
7.7 Function pointers
通过函数指针调用函数,如果目标地址可以预测,则可能比直接调用函数多花费几个时钟周期。如果函数指针的值与上次执行该语句时相同,则会预测到目标地址。如果函数指针的值改变了,则目标地址很可能被错误地预测,这会导致长时间的延迟。有关分支预测,请参见第43页。
7.8 Member pointers
在简单的情况下,数据成员指针只需存储相对于对象起始位置的数据成员偏移量,而成员函数指针只是成员函数的地址。但在多重继承等特殊情况下,需要使用更复杂的实现方式。这些复杂情况应该被尽量避免。
如果编译器对成员指针所引用的类的信息不完整,它必须使用最复杂的成员指针实现方式。例如:
// Example 7.14
class c1;
int c1::*MemberPointer;在这里,编译器除了类 c1 的名称外没有关于它的任何信息。因此,它必须假设最坏的情况并制作一个复杂的成员指针实现。可以通过在声明 MemberPointer 之前完整声明 c1 来避免这种情况。避免多重继承、虚函数和其他使成员指针不那么高效的复杂情况。
大多数 C++ 编译器都有各种选项来控制成员指针的实现方式。如果可能,使用最简单的实现选项,并确保对于使用相同成员指针的所有模块,使用相同的编译器选项。
7.9 Smart pointers
智能指针是一种行为类似于指针的对象。它具有一个特殊的特性,即当指针被删除时,它所指向的对象也会被删除。智能指针对于存储在动态分配内存中的对象非常方便,使用new关键字进行分配。使用智能指针的目的是确保对象在不再使用时被正确删除,并释放内存。智能指针可以被视为一种简单的实现数据容器或动态大小数组的方法,而无需定义容器类。
C++11标准定义了智能指针作为std::unique_ptr和std::shared_ptr。std::unique_ptr具有这样的特性:始终只有一个拥有分配对象的指针。通过赋值,所有权可以从一个unique_ptr转移到另一个unique_ptr。shared_ptr允许多个指针指向同一个对象。
通过智能指针访问对象并没有额外的成本。无论p是一个简单指针还是智能指针,通过*p或p->member访问对象的速度都是相同的。但是,每当创建、删除、复制或从一个函数转移到另一个函数时,智能指针都会有额外的成本。shared_ptr的这些成本比unique_ptr更高。
最优化的编译器(如Clang、Gnu)能够在简单情况下去掉大部分或全部unique_ptr的开销,使得编译后的代码只包含对new和delete的调用。
智能指针在以下情况下可能很有用:程序的逻辑结构规定一个对象必须由一个函数动态创建,然后由另一个函数删除,而这两个函数彼此无关(不属于同一个类的成员)。如果同一个函数或类负责创建和删除对象,则不需要智能指针。
如果程序使用许多小的动态分配对象,并且每个对象有自己的智能指针,那么您可能需要考虑这种解决方案的成本是否太高。将所有对象汇集到单个容器中,最好是连续的内存,可能更高效。请参阅第97页关于容器类的讨论。
7.10 Arrays
数组通过在内存中连续存储元素来实现。数组没有存储关于数组维度的信息。这使得在C和C++中使用数组比其他编程语言更快,但也更不安全。可以通过定义一个行为类似于带有边界检查的数组的容器类来解决这个安全问题,如下面的示例所示:
// Example 7.15a. Array with bounds checking
template <typename T, unsigned int N> class SafeArray {
protected:
T a[N]; // Array with N elements of type T
public:
SafeArray() { // Constructor
memset(a, 0, sizeof(a)); // Initialize to zero
}
int Size() { // Return the size of the array
return N;
}
T & operator[] (unsigned int i) { // Safe [] array index operator
if (i >= N) {
// Index out of range. The next line provokes an error.
// You may insert any other error reporting here:
return *(T*)0; // Return a null reference to provoke error
}
// No error
return a[i]; // Return reference to a[i]
}
};在第97页上还提供了更多关于容器类的示例。
使用上述模板类声明一个数组时,需要指定类型和大小作为模板参数,就像下面的示例7.15b所示。可以像访问普通数组一样,通过方括号索引来访问它。构造函数将所有元素都设置为零。如果不想进行这种初始化,或者如果类型T是一个具有默认构造函数并执行必要初始化的类,则可以删除memset行。编译器可能会报告memset已经被弃用。这是因为如果尺寸参数错误,它可能会导致错误,但仍然是将数组置零的最快方法。[]运算符将检测是否超出范围(请参见第147页的边界检查)。在这里,通过返回空引用的方式以相当非常规的方式引发错误消息。如果访问数组元素时,这将在受保护操作系统中引发错误消息,并且可以通过调试器轻松跟踪此错误。您可以将此行替换为任何其他形式的错误报告。例如,在Windows中,您可以编写FatalAppExitA(0,"Array index out of range");,或者更好的是,自己编写错误消息函数。
以下示例演示了如何使用SafeArray:
// Example 7.15b
SafeArray <float, 100> list; // Make array of 100 floats
for (int i = 0; i < list.Size(); i++) { // Loop through array
cout << list[i] << endl; // Output array element
}如第26页所述,最好将由列表初始化的数组设为静态。可以使用memset将数组初始化为零:
// Example 7.16
float list[100];
memset(list, 0, sizeof(list));多维数组应该按照最后一个索引变化最快的方式进行组织:
// Example 7.17
const int rows = 20, columns = 50;
float matrix[rows][columns];
int i, j; float x;
for (i = 0; i < rows; i++)
for (j = 0; j < columns; j++)
matrix[i][j] += x;这样可以确保按顺序访问元素。两个循环的相反顺序会使访问变得不连续,这会使数据缓存 less efficient。
如果行索引按非顺序方式索引,则除了第一维的大小最好是2的幂,以使地址计算更加高效:
// Example 7.18
int FuncRow(int); int FuncCol(int);
const int rows = 20, columns = 32;
float matrix[rows][columns];
int i; float x;
for (i = 0; i < 100; i++)
matrix[FuncRow(i)][FuncCol(i)] += x;在这里,代码必须计算(FuncRow(i)*columns + FuncCol(i)) * sizeof(float)以查找矩阵元素的地址。在这种情况下,如果columns是2的幂,则通过columns进行乘法更快。在前面的示例中,这不是问题,因为优化编译器可以看到行是连续访问的,并且可以通过将一行的长度添加到前一行的地址来计算每一行的地址。
相同的建议适用于结构体或类对象数组。如果按非顺序方式访问元素,则对象的大小(以字节为单位)最好是2的幂。
使列数为2的幂的建议并不总是适用于大于一级数据缓存并且按非顺序方式访问的数组,因为可能会导致缓存争用。请参见第91页对此问题的讨论。
7.11 Type conversions
C++语法有几种不同的类型转换方式:
// Example 7.19
int i; float f;
f = i; // Implicit type conversion
f = (float)i; // C-style type casting
f = float(i); // Constructor-style type casting
f = static_cast<float>(i); // C++ casting operator这些不同的方法具有完全相同的效果。使用哪种方法是编程风格的问题。下面将讨论不同类型转换的时间消耗。
Signed / unsigned conversion
// Example 7.20
int i;
if ((unsigned int)i < 10) { ...有符号和无符号整数之间的转换只是让编译器以不同的方式解释整数的位。没有进行溢出检查,代码也不会花费额外的时间。这些转换可以自由使用,而不会对性能造成任何成本。
Integer size conversion
// Example 7.21
int i; short int s;
i = s;将整数转换为更长的大小,如果整数是有符号的,则通过扩展符号位进行,如果是无符号的,则通过扩展零位进行。如果源是算术表达式,则通常需要一个时钟周期。如果与从内存中的变量读取值的操作一起执行大小转换,则此转换通常不需要额外的时间,就像示例7.22中一样。
// Example 7.22
short int a[100]; int i, sum = 0;
for (i=0; i<100; i++) sum += a[i];将整数转换为更小的大小只需简单地忽略高位。不会进行溢出检查。例如:
// Example 7.23
int i; short int s;
s = (short int)i;这种转换不需要额外的时间。它只是简单地存储32位整数的低16位。
Floating point precision conversion
在使用浮点寄存器堆栈时,浮点数、双精度浮点数和长双精度浮点数之间的转换不需要额外的时间。当使用XMM寄存器时,它需要2到15个时钟周期(取决于处理器)。请参见第31页中关于寄存器栈和XMM寄存器的解释。例如:
// Example 7.24
float a; double b;
a += b;在这个例子中,如果使用XMM寄存器,转换是昂贵的。为了避免这种情况,a和b应该是相同的类型。请参考第153页进行进一步讨论。
Integer to float conversion
将有符号整数转换为浮点数或双精度浮点数取决于处理器和所使用的寄存器类型,需要4-16个时钟周期。相比于有符号整数,无符号整数的转换时间更长,除非启用了AVX512指令集(对于64位无符号整数则是AVX512DQ)。如果不会出现溢出的风险,先将无符号整数转换为有符号整数会更快:
// Example 7.25
unsigned int u; double d;
d = (double)(signed int)u; // Faster, but risk of overflow通过将整数变量替换为浮点数变量,有时可以避免整数到浮点数的转换。例如:
// Example 7.26a
float a[100]; int i;
for (i = 0; i < 100; i++) a[i] = 2 * i;在这个例子中,可以通过增加一个额外的浮点型变量来避免将i转换为浮点数:
// Example 7.26b
float a[100]; int i; float i2;
for (i = 0, i2 = 0; i < 100; i++, i2 += 2.0f) a[i] = i2;Float to integer conversion
将浮点数转换为整数需要很长时间,除非启用SSE2或更高版本的指令集。通常,转换需要50-100个时钟周期。原因是C/C++标准规定截断,因此浮点数舍入模式必须改为截断,然后再改回来。
如果代码的关键部分存在浮点数到整数的转换,则重要的是采取措施解决它。可能的解决方案包括:
使用不同类型的变量避免转换。
通过将中间结果存储为浮点数,将转换移出最内层循环。
使用64位模式或启用SSE2指令集(需要支持此功能的微处理器)。
使用舍入而不是截断,并使用汇编语言制作一个舍入函数。有关舍入的详细信息,请参见第154页。
Pointer type conversion
指针可以转换为不同类型的指针。同样,指针可以转换为整数,或整数可以转换为指针。重要的是整数具有足够的位数来容纳指针。
这些转换不会产生任何额外的代码。它只是以不同的方式解释相同的位或绕过语法检查。
当然,这些转换是不安全的。程序员有责任确保结果是有效的。
Re-interpreting the type of an object
通过将变量或对象的地址进行类型转换,可以使编译器将其视为具有不同类型:
// Example 7.27
float x;
*(int*)&x |= 0x80000000; // Set sign bit of x这里的语法可能看起来有点奇怪。x的地址被类型转换为指向整数的指针,然后通过取消引用该指针来将x作为整数访问。编译器不会生成任何额外的代码来创建一个指针。指针会被优化掉,结果就是x被视为整数。但是,&运算符会强制编译器将x存储在内存中而不是寄存器中。上面的示例使用|运算符设置了x的符号位,而该运算符通常只能应用于整数。这比x = -abs(x);要快。
在进行指针类型转换时,有一些需要注意的危险性:
• 这种技巧违反了C标准的严格别名规则,该规则指定两个不同类型的指针不能指向同一个对象(除了char指针)。优化编译器可能会将浮点和整数表示存储在两个不同的寄存器中。您需要检查编译器是否按照您的意图进行操作。更安全的做法是使用联合体,如第155页的示例14.22所示。
• 如果对象被视为比实际大小更大,这种技巧将失败。如果int在x86系统中使用比float更多的位(两者都使用32位)时,上述代码将失败。
• 如果您访问变量的一部分,例如64位双精度的32位,那么该代码在使用大端存储的平台上将无法移植。
• 如果以部分方式访问变量,例如每次以32位的方式写入64位双精度,则由于CPU中的存储转发延迟,代码执行可能会比预期慢(请参阅第3章手册:“Intel、AMD和VIA CPU的微体系结构”)。
Const cast
const_cast运算符用于解除指针的const限制。它具有一些语法检查,并且比C风格的类型转换更安全,而不会添加任何额外的代码。示例:
// Example 7.28
class c1 {
const int x; // constant data
public:
c1() : x(0) {}; // constructor initializes x to 0
void xplus2() { // this function can modify x
*const_cast<int*>(&x) += 2;} // add 2 to x
};在这里,const_cast运算符的作用是移除x上的const限制。它是一种解除语法限制的方式,但它不会生成任何额外的代码,也不会消耗任何额外的时间。这是一种确保一个函数可以修改x,而其他函数不能的有用方式。
Static cast
static_cast运算符与C风格的类型转换相同。例如,它可以用于将float转换为int。
Reinterpret cast
reinterpret_cast运算符用于指针转换。它与C风格的类型转换相同,但具有更多的语法检查。它不会生成任何额外的代码。
Dynamic cast
dynamic_cast运算符用于将一个类的指针转换为另一个类的指针。它会进行运行时检查,以确保转换是有效的。例如,当将一个指向基类的指针转换为指向派生类的指针时,它会检查原始指针实际上是否指向派生类的对象。这个检查使得dynamic_cast比简单的类型转换更加耗时,但也更安全。它可以捕捉到其他情况下可能未被发现的编程错误。
Converting class objects
涉及类对象的转换(而不仅仅是对象的指针)只有在程序员定义了一个构造函数、重载的赋值运算符或重载的类型转换运算符来指定如何进行转换时才可能发生。构造函数或重载运算符与成员函数一样高效。
7.12 Branches and switch statements
现代微处理器的高速性是通过使用流水线实现的,在执行之前,指令会经过多个阶段进行取指和解码。然而,流水线结构存在一个大问题。每当代码有一个分支(例如if-else结构)时,微处理器无法提前知道应该将哪个分支输入到流水线中。如果错误的分支被输入到流水线中,那么错误直到10-20个时钟周期后才被检测到,并且在此期间通过取指、解码和可能的预执行指令所做的工作都被浪费了。结果是,每当微处理器将一个分支输入到流水线中,并且后来发现选择了错误的分支时,它就会浪费几个时钟周期。
微处理器设计师为了减少这个问题已经付出了很大努力。最重要的方法是分支预测。现代微处理器使用先进的算法根据该分支和其他附近分支的过去历史来预测分支的走向。用于分支预测的算法对于每种类型的微处理器都不同。这些算法在手册3《Intel、AMD和VIA CPU的微体系结构》中有详细描述。
在微处理器做出正确预测的情况下,分支指令通常需要0-2个时钟周期。从分支错误预测中恢复所需的时间大约为12-25个时钟周期,具体取决于处理器。这被称为分支误预测的惩罚。
如果大多数情况下能够正确预测分支,那么分支的开销相对较低,但如果经常预测错误,则开销较高。当分支总是按照同一方向执行时,预测效果会很好。而当分支大部分时间按照一种方向执行,很少按照另一种方向执行时,只有在执行另一种方向时才会预测错误。当一个分支连续多次按照一种方向执行,然后连续多次按照另一种方向执行时,只有在改变方向时才会预测错误。如果一个分支按照简单的周期模式执行,并且在循环中没有或很少存在其他分支,那么它也可以被很好地预测。一个简单的周期模式可以是按照某种顺序执行两次一种方向,三次另一种方向,然后再次两次第一种方式,三次第二种方式,以此类推。最糟糕的情况是一个分支随机地按照两种方向之一进行,每种方向的概率都为50%。这样的分支将有50%的概率预测错误。
for循环和while循环也是一种分支结构。在每次迭代后,它决定是重复循环还是退出循环。如果重复次数较小且始终相同,则循环分支通常能够被很好地预测。完全可以预测的最大循环次数因处理器而异,介于9到64之间。嵌套循环只有在某些处理器上能够被很好地预测。在许多处理器上,包含多个分支的循环不能被很好地预测。
switch语句是一种能够有多个路径的分支结构。如果case标签按照前一个标签加一的顺序排列,那么switch语句的效率最高,因为它可以实现为一个跳转目标表。如果有许多标签的值相差很大,那么switch语句的效率较低,因为编译器必须将其转换为一个分支树。
在旧的处理器上,顺序标签的switch语句通常会被预测为上次执行时的方向。因此,每当它执行与上次不同的方向时,就肯定会预测错误。新的处理器有时能够预测一个遵循简单周期模式的switch语句,或者当它与前面的分支相关并且具有少量不同目标时也能够预测。
在程序的关键部分,特别是如果分支难以预测,最好尽量减少分支和switch语句的数量。如果可能的话,通过展开循环来消除分支可能是有用的,具体解释见下一段。
分支和函数调用的目标保存在一个特殊的缓存中,称为分支目标缓冲区。如果程序有许多分支或函数调用,就可能发生分支目标缓冲区的争用。这种争用的后果是,即使分支本来能够被很好地预测,也可能会预测错误。甚至直接函数调用也可能因为这个原因被预测错误。在代码的关键部分中有许多分支和函数调用的程序可能会因此遭受预测错误的影响。
在某些情况下,可以通过表格查找来替换难以预测的分支。例如:
// Example 7.29a
float a; bool b;
a = b ? 1.5f : 2.6f; 这里的 ?: 运算符是一个分支。如果它的可预测性较差,可以用表格查找来替代它。
// Example 7.29b
float a; bool b = 0;
const float lookup[2] = {2.6f, 1.5f};
a = lookup[b];如果将bool用作数组索引,则必须确保它被初始化或来自可靠的源,以便它的取值只能为0或1。请参阅第34页。
在某些情况下,编译器可以自动通过条件移动来替代分支。第147页和148页上的示例展示了减少分支数量的各种方式。
《手册3:英特尔、AMD和VIA CPU的微体系结构》对不同微处理器中的分支预测提供了更多详细信息。
7.13 Loops
循环的效率取决于微处理器对循环控制分支的预测能力。请参阅前面的段落和《手册3:英特尔、AMD和VIA CPU的微体系结构》以了解分支预测的解释。具有小且固定重复次数且没有内部分支的循环可以完全预测。如上所述,可以预测的最大循环次数取决于处理器。只有某些具有特殊循环预测器的处理器才能很好地预测嵌套循环。在其他处理器上,只有最内层的循环能够得到很好的预测。具有高重复次数的循环仅在退出时会预测错误。例如,如果一个循环重复一千次,那么循环控制分支只会在一千次中预测错误一次,因此预测错误的代价对总执行时间的贡献非常小,可以忽略不计。
Loop unrolling
在某些情况下,展开循环可以带来优势。例如:
// Example 7.30a
int i;
for (i = 0; i < 20; i++) {
if (i % 2 == 0) {
FuncA(i);
}
else {
FuncB(i);
}
FuncC(i);
}这个循环重复20次,并交替调用FuncA和FuncB,然后调用FuncC。将循环展开两次得到:
// Example 7.30b
int i;
for (i = 0; i < 20; i += 2) {
FuncA(i);
FuncC(i);
FuncB(i+1);
FuncC(i+1);
}这样做有三个优点:
• i<20的循环控制分支只需执行10次,而不是20次。
• 重复次数从20减少到10意味着在大多数CPU上可以完全预测。
• 条件分支被消除了。
展开循环也有一些缺点:
• 展开后的循环在代码缓存或微操作缓存中占用更多空间。
• 许多CPU都有循环回溯缓冲区,可以改善非常小的循环性能,正如我在微体系结构手册中所解释的那样。展开后的循环不太可能适应循环回溯缓冲区。
• 如果重复次数是奇数,并且展开因子为2,则在循环外还必须执行额外的迭代。通常,当重复次数不能被展开因子整除时,会出现这个问题。
只有在可以获得特定优势时才应使用展开循环。如果一个循环中包含浮点计算或向量指令,并且循环计数器是整数,则通常可以假定整个计算时间是由浮点代码而不是由循环控制分支决定的。在这种情况下,展开循环没有任何收益。
当存在循环延迟依赖链时,展开循环是有用的,详见第113页。
在具有微操作缓存的处理器上,最好避免使用循环展开,因为重复利用微操作缓存非常重要。这也适用于具有循环回溯缓冲区的处理器。
编译器通常会自动展开循环,如果这看起来是有利可图的话(参见第72页)。除非有特定的优势可以获得,例如在例7.30b中消除if-branch,否则程序员不必手动展开循环。
The loop control condition
最有效的循环控制条件是一个简单的整数计数器。具有乱序执行功能的微处理器(参见第113页)将能够提前几个迭代地评估循环控制语句。
如果循环控制分支取决于循环内的计算,则效率较低。以下示例将以零结尾的ASCII字符串转换为小写:
// Example 7.31a
char string[100], *p = string;
while (*p != 0) *(p++) |= 0x20;如果已经知道字符串的长度,那么使用循环计数器更高效:
// Example 7.31b
char string[100], *p = string; int i, StringLength;
for (i = StringLength; i > 0; i--) *(p++) |= 0x20;循环控制分支取决于循环内的计算的常见情况之一是数学迭代,如泰勒展开和牛顿-拉弗森迭代。在这种情况下,迭代将重复执行,直到残差误差低于某个特定容限。计算残差误差的绝对值并将其与容限进行比较所需的时间可能非常长,以至于确定最坏情况的最大重复次数,并始终使用这个迭代次数更为高效。此方法的优点是微处理器可以提前执行循环控制分支,并在循环内的浮点计算完成之前解决任何分支错误预测问题。如果典型的重复次数接近最大重复次数,并且每次迭代计算残差误差对总计算时间有显著贡献,则此方法具有优势。
循环计数器最好是整数。如果循环需要一个浮点计数器,则需额外使用一个整数计数器。例如:
// Example 7.32a
double x, n, factorial = 1.0;
for (x = 2.0; x <= n; x++) factorial *= x;可以通过添加一个整数计数器并在循环控制条件中使用该整数来改进此方法:
// Example 7.32b
double x, n, factorial = 1.0; int i;
for (i = (int)n - 2, x = 2.0; i >= 0; i--, x++) factorial *= x;请注意在具有多个计数器的循环中逗号和分号的区别,就像示例7.32b中一样。for循环有三个子句:初始化、条件和递增。这三个子句之间用分号分隔,而每个子句内部的多个语句用逗号分隔。条件子句中应该只有一个语句。
将整数与零进行比较有时比将其与其他任何数字进行比较更高效。因此,将循环计数器倒数至零要比使其递增至某个正值n稍微更高效。但是,如果循环计数器用作数组索引,则情况就不同了。数据缓存已经针对正向访问数组进行了优化,而不是反向访问。
Copying or clearing arrays
像复制一个数组或将一个数组设置为全零这样的琐碎任务使用循环可能并不是最优的。例如:
// Example 7.33a
const int size = 1000; int i;
float a[size], b[size];
// set a to zero
for (i = 0; i < size; i++) a[i] = 0.0;
// copy a to b
for (i = 0; i < size; i++) b[i] = a[i];通常使用memset和memcpy函数会更快:
// Example 7.33b
const int size = 1000;
float a[size], b[size];
// set a to zero
memset(a, 0, sizeof(a));
// copy a to b
memcpy(b, a, sizeof(b));在简单的情况下,大多数编译器会自动将这样的循环替换为对memset和memcpy的调用。然而,显式使用memset和memcpy是不安全的,如果大小参数大于目标数组,则可能会发生严重错误。但是,如果循环计数过大,也会发生相同的错误。
7.14 Functions
函数调用可能会使程序变慢,原因如下:
• 函数调用会使微处理器跳转到不同的代码地址并返回,这可能需要多达4个时钟周期。在大多数情况下,微处理器能够将调用和返回操作与其他计算重叠以节省时间。
• 如果代码在内存中分散和随机分布,则代码缓存的效率会降低。
• 在32位模式下,函数参数存储在栈中。将参数存储在堆栈中并再次读取需要额外的时间。如果参数是关键依赖链的一部分,则延迟是显著的。
• 需要额外的时间来设置堆栈帧、保存和恢复寄存器,并可能保存异常处理信息。
• 每个函数调用语句占用分支目标缓冲器(BTB)中的空间。如果程序的关键部分具有许多调用和分支,则BTB中的争用可能导致分支预测错误。
以下方法可用于减少程序中关键部分上的函数调用所需的时间。
Avoid unnecessary functions
一些编程教材建议将超过几行的每个函数拆分为多个函数。我不同意这个规则。将函数拆分为多个较小的函数只会使程序变得更低效。除非函数执行多个逻辑上不同的任务,否则仅仅因为函数较长就将其拆分并不能使程序更清晰。如果可能的话,最关键的内部循环最好完全保留在一个函数中。
Use inline functions
内联函数会像宏一样展开,以便调用函数的每个语句都被替换为函数体。如果使用inline关键字或者函数体定义在类定义内部,则通常会将函数内联化。如果函数很小或者只从程序中的一个地方调用,那么内联函数是有优势的。通常,编译器会自动将小型函数内联。另一方面,如果内联导致技术问题或性能问题,在某些情况下,编译器可能会忽略请求内联一个函数。
Avoid nested function calls in the innermost loop
调用其他函数的函数被称为帧函数,而不调用任何其他函数的函数被称为叶函数。如第63页所述,叶函数比帧函数更加高效。如果程序的关键内部循环包含对帧函数的调用,那么可以通过将帧函数内联或通过内联其调用的所有函数将帧函数变成叶函数来改进代码。
Use macros instead of functions
使用#define声明的宏肯定会被内联展开。但请注意,宏参数在每次使用时都会被求值。例如:
// Example 7.34a. Use macro as inline function
#define MAX(a,b) (a > b ? a : b)
y = MAX(f(x), g(x));在这个例子中,由于宏被引用两次,f(x)或g(x)会被计算两次。通过使用内联函数而不是宏,可以避免这种情况。如果希望该函数适用于任何类型的参数,则可以将其定义为模板:
// Example 7.34b. Replace macro by template
template <typename T>
static inline T max(T const & a, T const & b) {
return a > b ? a : b;
}宏的另一个问题是,名称无法进行重载或限定作用域。无论作用域或命名空间如何,宏都会干扰任何具有相同名称的函数或变量。因此,特别是在头文件中,使用长且唯一的名称对于宏非常重要。
Use fastcall and vectorcall functions
关键字__fastcall会在32位模式下改变函数的调用方式,使得前两个整数参数传递到寄存器而不是堆栈中。这可以提高具有整数参数的函数的速度。
浮点参数不受__fastcall的影响。成员函数中的隐式'this'指针也被视为参数,因此可能只剩下一个可用的寄存器来传递其他参数。因此,在使用__fastcall时,请确保最关键的整数参数排在最前面。在64位模式下,默认情况下,函数参数会通过寄存器传递。因此,在64位模式下不识别__fastcall关键字。
关键字__vectorcall会在Windows系统中改变浮点和向量操作数的函数调用方式,使得参数在向量寄存器中传递和返回。这在64位Windows系统中特别有优势。目前,__vectorcall方法得到Microsoft、Intel和Clang编译器的支持。
Make functions local
只在同一模块(即当前的.cpp文件)中使用的函数应该被声明为局部函数。这样可以更容易地让编译器内联函数并在函数调用之间进行优化。有三种方法可以使函数成为局部函数:
1. 在函数声明中加入关键字static。这是最简单的方法,但对于类成员函数来说不适用,因为static在此情况下有不同的含义。
2. 将函数或类放入一个匿名命名空间中。
3. GNU编译器允许使用"__attribute__((visibility("hidden")))"。
Use whole program optimization
一些编译器提供了整个程序优化的选项,或者将多个.cpp文件合并成一个单独的目标文件的选项。这使得编译器能够在组成程序的所有.cpp模块中进行寄存器分配和参数传递的优化。但整个程序优化无法用于以目标文件或库文件形式分发的函数库。
Use 64-bit mode
参数传递在64位模式下比32位模式更有效,在64位Linux下比64位Windows更有效。在64位Linux中,前六个整数参数和前八个浮点参数在寄存器中传递,总共达到十四个寄存器参数。在64位Windows中,无论整数还是浮点数,前四个参数都在寄存器中传递。因此,如果函数具有超过四个参数,则64位Linux比64位Windows更有效。在这方面,32位Linux和32位Windows之间没有区别。
对于浮点和向量变量可用的寄存器数量,在32位模式下为8个寄存器,在64位模式下为16个寄存器。当启用AVX512指令集时,它进一步增加到64位模式下的32个寄存器。高数量的寄存器可以提高性能,因为编译器可以将变量存储在寄存器中而不是内存中。
7.15 Function parameters
在大多数情况下,函数参数是通过值传递的。这意味着参数的值被复制到一个局部变量中。对于简单类型(如int、float、double、bool、enum)、指针和引用来说,这是高效的。
数组总是以指针的形式传递,除非它们被封装到一个类或结构体中。
如果参数具有结构体或类等组合类型,则情况会更复杂。如果满足以下所有条件,则组合类型参数的传递方式是最有效的:
- 对象很小,适合存储在一个寄存器中
- 对象没有复制构造函数和析构函数
- 对象没有虚成员
- 对象不使用运行时类型识别(RTTI)
如果这些条件中有任何一个不满足,则通常更快的方式是传递对象的指针或引用。如果对象很大,那么复制整个对象需要时间。在将对象复制到参数时,必须调用任何复制构造函数,并在函数返回之前调用析构函数(如果有)。
将组合对象传递给函数的首选方法是使用const引用。const引用确保原始对象不被修改。与指针或非const引用不同,const引用允许函数参数是表达式或匿名对象。如果函数是内联的,编译器可以轻松地优化掉const引用。
另一种解决方案是将函数作为对象的类成员或结构体成员。这同样是高效的。
在32位系统中,简单函数参数在堆栈上传递,但在64位系统中放在寄存器中。后者更高效。64位Windows允许最多在寄存器中传递四个参数。64位Unix系统允许最多在寄存器中传递十四个参数(8个浮点型或双精度型加上6个整数、指针或引用参数)。成员函数中的this指针计为一个参数。更多细节见手册5:"不同C++编译器和操作系统的调用约定"。
7.16 Function return types
函数的返回类型最好是简单类型、指针、引用或void。返回组合类型的对象更复杂,通常效率也更低。
在最简单的情况下,组合类型的对象可以仅在寄存器中返回。关于何时可以在寄存器中返回对象,请参见手册5:"不同C++编译器和操作系统的调用约定"。除了最简单的情况,组合对象都通过将它们复制到由调用方通过隐藏指针指定的位置来返回。复制过程中通常会调用复制构造函数(如果有),当原始对象被销毁时会调用析构函数。在简单的情况下,编译器可能能够避免调用复制构造函数和析构函数,方法是在最终目的地上构造对象,但不能保证可以做到这一点。
与其返回组合对象,您可能考虑以下替代方法:
- 将函数作为对象的构造函数。
- 使函数修改现有对象而不是创建一个新对象。现有对象可以通过指针或引用提供给函数,或者函数可以是对象类的成员函数。
- 使函数返回指向在函数内定义的静态对象的指针或引用。这种方法高效但存在风险。返回的指针或引用仅在下次调用函数及其本地对象被覆盖之前有效,可能在不同的线程中。如果您忘记将本地对象设为静态,则在函数返回后它会立即失效。
- 使函数使用new构造对象并返回指向该对象的指针。这种方法效率低下,因为涉及动态内存分配的成本。如果忘记删除对象,则可能会出现内存泄漏。
7.17 Function tail calls
尾调用是一种优化函数调用的方式。如果一个函数的最后一个语句是对另一个函数的调用,编译器可以将该调用替换为跳转到第二个函数的指令。优化编译器会自动执行这个优化。第二个函数不会返回到第一个函数,而是直接返回到调用第一个函数的位置。这样更高效,因为它省去了一次返回操作。示例:
// Example 7.35. Tail call
void function2(int x);
void function1(int y) {
...
function2(y+1);
}在这里,通过直接跳转到function2来消除了从function1返回的操作。即使存在返回值,这种优化也可以工作:
// Example 7.36. Tail call with return value
int function2(int x);
int function1(int y) {
...
return function2(y+1);
}尾调用优化仅在两个函数具有相同的返回类型时起作用。如果函数在堆栈上有参数(这在32位模式下通常是情况),那么这两个函数必须使用相同数量的堆栈空间来存储参数。
7.18 Recursive functions
递归函数是调用自身的函数。递归函数调用对于处理递归数据结构非常有用。递归函数的代价是每次递归所有参数和局部变量都会获得一个新实例,这会占用堆栈空间。深层递归还会使返回地址的预测变得不太高效。这个问题通常在递归层数大于16时出现(参见手册3中Intel、AMD和VIA CPU的微体系结构的解释)。递归函数调用仍然可以是处理分支数据树结构的最有效解决方案。如果树结构比较广,递归是更高效的选择,如果树结构比较深,循环则更高效。非分支递归总是可以被一个循环替换,而循环更加高效。一个经典的教科书递归函数例子是阶乘函数:
// Example 7.37. Factorial as recursive function
unsigned long int factorial(unsigned int n) {
if (n < 2) return 1;
return n * factorial(n-1);
}这个实现非常低效,因为所有的n实例和返回地址都会占用堆栈的存储空间。使用循环更加高效:
// Example 7.38. Factorial function as loop
unsigned long int factorial(unsigned int n) {
unsigned long int product = 1;
while (n > 1) {
product *= n;
n--;
}
return product;
}递归的尾调用比其他递归调用更高效,但仍然比循环低效。新手程序员有时会调用main函数来重新启动他们的程序。这是一个不好的做法,因为每次对main函数的递归调用都会在堆栈上创建新的局部变量实例,导致堆栈空间被填满。正确的方法是在main函数中使用循环来重新启动程序。
7.19 Structures and classes
如今,编程教科书推荐面向对象编程作为使软件更清晰和模块化的手段。所谓的对象是结构体和类的实例。面向对象编程风格对程序性能产生了正面和负面的影响。其中正面效果包括:
- 如果变量属于同一结构体或类的成员,在存储时它们会被一起存放,这使得数据缓存更高效。
- 类的成员变量无需作为参数传递给类成员函数,因此避免了参数传递的开销。
面向对象编程的负面效果包括:
- 有些程序员将代码划分为过多的小类,这是低效的。
- 非静态成员函数需要一个隐式的'this'指针作为参数进行传递,对于所有非静态成员函数都会产生参数传递的开销。
- 'this'指针占用一个寄存器。在32位系统中,寄存器是一种稀缺资源。
- 虚函数的效率较低(参见第55页)。
无法一般性地断言正面效果还是负面效果在面向对象编程中占主导地位。至少可以说,使用类和成员函数并不昂贵。只要避免在程序的最关键部分出现过多的函数调用,如果这种编程风格对程序的逻辑结构和清晰度有益,可以使用面向对象编程风格。在性能方面,使用结构体(无成员函数)没有负面影响。
7.20 Class data members (instance variables)
当创建一个类或结构的实例时,类或结构的数据成员按照声明的顺序连续存储。将数据组织成类或结构不会带来性能损失。访问类或结构对象的数据成员所需的时间与访问简单变量的时间相同。大多数编译器会对数据成员进行对齐,以便优化访问,具体对齐情况请参考以下表格。
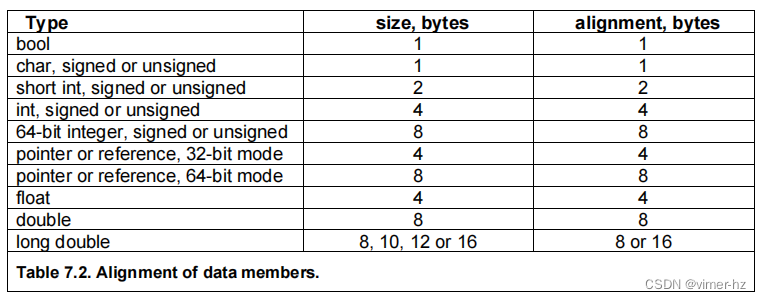
这种对齐可能会导致在具有不同大小成员的结构体或类中出现未使用字节的空洞。例如:
// Example 7.39a
struct S1 {
short int a; // 2 bytes. first byte at 0, last byte at 1
// 6 unused bytes
double b; // 8 bytes. first byte at 8, last byte at 15
int d; // 4 bytes. first byte at 16, last byte at 19
// 4 unused bytes
};
S1 ArrayOfStructures[100];在这里,a和b之间有6个未使用的字节,因为b必须从可以被8整除的地址开始。末尾还有4个未使用的字节。原因是数组中的下一个S1实例必须从可以被8整除的地址开始,以便将其b成员对齐到8字节。通过将最小的成员放在最后,未使用的字节数量可以减少到2个:
// Example 7.39b
struct S1 {
double b; // 8 bytes. first byte at 0, last byte at 7
int d; // 4 bytes. first byte at 8, last byte at 11
short int a; // 2 bytes. first byte at 12, last byte at 13
// 2 unused bytes
};
S1 ArrayOfStructures[100];通过重新排序数据成员,这个结构体减小了8个字节,数组减小了800个字节。通过重新排序数据成员,通常可以减小结构体和类对象的大小。如果类至少有一个虚成员函数,则在第一个数据成员之前或最后一个成员之后会有一个指向虚表的指针。在32位系统中,该指针占用4个字节,在64位系统中占用8个字节。如果对结构体或其成员的大小存疑,可以使用sizeof操作符进行一些测试。sizeof操作符返回的值包括对象末尾的任何未使用字节。
如果相对于结构体或类的起始位置,访问数据成员的偏移量小于128,则代码更加简洁,因为偏移量可以表示为一个8位有符号数。如果相对于结构体或类的起始位置的偏移量为128字节或更大,则必须将偏移量表示为32位数(指令集在8位和32位偏移量之间没有其他选项)。例如:
// Example 7.40
class S2 {
public:
int a[100]; // 400 bytes. first byte at 0, last byte at 399
int b; // 4 bytes. first byte at 400, last byte at 403
int ReadB() {return b;}
};这里的b的偏移量是400。通过指针或成员函数(如ReadB)访问b的任何代码都需要将偏移量编码为32位数。如果交换a和b的位置,则可以使用编码为8位有符号数的偏移量或根本不使用偏移量来访问它们两个。这使得代码更加紧凑,以便更高效地使用代码缓存。因此,建议将大型数组和其他大型对象放在结构体或类声明的最后,并将最常用的数据成员放在前面。如果无法将所有数据成员包含在前128字节内,则将最常用的成员放在前128字节内。
7.21 Class member functions (methods)
每次声明或创建一个类的新对象时,都会生成数据成员的新实例。但是,每个成员函数只有一个实例。函数代码不会被复制,因为相同的代码可以适用于类的所有实例。
调用成员函数的速度与调用指向结构体的指针或引用的简单函数一样快。例如:
// Example 7.41
class S3 {
public:
int a;
int b;
int Sum1() {return a + b;}
};
int Sum2(S3 * p) {return p->a + p->b;}
int Sum3(S3 & r) {return r.a + r.b;}Sum1、Sum2和Sum3这三个函数完全做着相同的事情,并且它们的效率也是相等的。如果你查看编译器生成的代码,你会注意到有些编译器会为这三个函数生成完全相同的代码。Sum1有一个隐式的'this'指针,它执行的操作与Sum2和Sum3中的p和r相同。将函数作为类的成员函数、给它一个指向类或结构体的指针或引用,仅仅是一种编程风格的问题。有些编译器在32位Windows中,通过在寄存器中传递'this'而不是在栈上传递,使得Sum1比Sum2和Sum3稍微更高效一些。
静态成员函数无法访问任何非静态数据成员或非静态成员函数。静态成员函数比非静态成员函数更快,因为它不需要'this'指针。如果成员函数不需要非静态访问,可以通过将它们声明为静态函数来提高速度。
7.22 Virtual member functions
虚函数用于实现多态类。多态类的每个实例都有一个指向不同版本虚函数的指针表。这个所谓的虚表在运行时用于找到正确版本的虚函数。多态性是面向对象程序相对于非面向对象程序可能效率较低的主要原因之一。如果可以避免使用虚函数,那么就可以在不付出性能代价的情况下获得大部分面向对象编程的优势。
调用虚成员函数所需的时间比调用非虚成员函数多几个时钟周期,前提是函数调用语句始终调用相同版本的虚函数。如果版本发生变化,则可能会获得10-20个时钟周期的错误预测惩罚。关于虚函数调用的预测和错误预测规则与switch语句相同,详见第44页。
当在已知类型的对象上调用虚函数时,可以绕过派发机制,但即使明显可以这样做,不能总是依赖编译器绕过派发机制。请参阅第76页。
只有在无法在编译时确定调用哪个版本的多态成员函数时才需要运行时多态。如果虚函数在程序的关键部分使用,则可以考虑是否可以通过编译时多态或者其他方式获得所需的功能。
有时候,可以使用模板而不是虚函数来获得所需的多态效果。模板参数应该是一个包含具有多个版本的函数的类。这种方法更快,因为模板参数总是在编译时解析而不是在运行时。第59页的示例7.47展示了如何做到这一点。不幸的是,语法可能相对复杂,可能不值得这样做。
7.23 Runtime type identification (RTTI)
运行时类型识别(RTTI)会给所有类对象添加额外的信息,这是不高效的。如果编译器有关闭RTTI的选项,请关闭它并使用其他实现方式。
7.24 Inheritance
派生类的对象与包含父类和子类成员的简单类的对象一样进行实现。可以同样快速地访问父类和子类成员。一般来说,可以认为使用继承没有什么性能惩罚。
然而有以下原因可能会导致代码缓存和数据缓存的降级:
• 子类包含所有父类数据成员,即使它不需要它们。
• 父类数据成员的大小被添加到子类成员的偏移量中。访问具有大于127字节总偏移量的数据成员的代码略微不够紧凑。详见第54页。
• 父类和子类的成员函数可能存储在不同的模块中。这可能导致跳转频繁,代码缓存不够高效。这个问题可以通过确保调用彼此接近的函数也一起存储在相近位置来解决。详见第92页。
在同一级别从多个父类继承可能会导致成员指针和虚函数的复杂性,或者在通过指向其中一个基类的指针访问派生类对象时出现问题。为了避免多重继承,您可以在派生类内部创建对象:
// Example 7.42a. Multiple inheritance
class B1; class B2;
class D : public B1, public B2 {
public:
int c;
};Replace with:
// Example 7.42b. Alternative to multiple inheritance
class B1; class B2;
class D : public B1 {
public:
B2 b2;
int c;
};一般来说,只有当继承对程序的逻辑结构有益时,才应该使用继承。
7.25 Constructors and destructors
构造函数在内部实现为返回对象的引用的成员函数。新对象的内存分配不一定由构造函数本身完成。因此,构造函数和其他任何成员函数一样高效。这适用于默认构造函数、拷贝构造函数和其他任何构造函数。
一个类不需要构造函数。如果对象不需要初始化,则不需要默认构造函数。如果对象可以通过复制所有数据成员来进行复制,则不需要拷贝构造函数。一个简单的构造函数可以进行内联以提高性能。
拷贝构造函数可能会在对象被赋值、作为函数参数或作为函数返回值进行拷贝时调用。如果涉及到内存或其他资源的分配,则拷贝构造函数可能会消耗时间。避免这种浪费性能的内存块复制有多种方法,例如:
• 使用对象的引用或指针而不是复制它
• 使用“移动构造函数”来转移对内存块的所有权。这需要C++0x或更高版本。
• 创建一个成员函数、友元函数或操作符,将内存块的所有权从一个对象转移到另一个对象。失去内存块所有权的对象应该将其指针设置为NULL。当然,应该有一个析构函数来销毁对象拥有的任何内存块。
析构函数和成员函数一样高效。如果不需要,不要创建析构函数。虚析构函数和虚成员函数一样高效。详见第55页。
7.26 Unions
联合是一个数据成员共享相同内存空间的结构。通过允许两个永远不会同时使用的数据成员共享相同的内存块,可以使用联合来节省内存空间。示例请参见第94页。
联合也可以用于以不同方式访问相同的数据。例如:
// Example 7.43
union {
float f;
int i;
} x;
x.f = 2.0f;
x.i |= 0x80000000; // set sign bit of f
cout << x.f; // will give -2.0在这个例子中,使用按位或运算符设置f的符号位,但该运算符只能用于整数。
7.27 Bitfields
位字段可以使数据更加紧凑。访问位字段的成员比访问结构的成员效率更低。如果可以节省缓存空间或减小文件大小,那么在大数组的情况下,额外的时间可能是合理的。
通过使用 << 和 | 运算符来组合位字段比逐个编写成员更快。例如:
// Example 7.44a
struct Bitfield {
int a:4;
int b:2;
int c:2;
};
Bitfield x;
int A, B, C;
x.a = A;
x.b = B;
x.c = C;假设A、B和C的值都太小而不会引起溢出,则可以通过以下方式改进此代码:
// Example 7.44b
union Bitfield {
struct {
int a:4;
int b:2;
int c:2;
};
char abc;
};
Bitfield x;
int A, B, C;
x.abc = A | (B << 4) | (C << 6);或者,如果需要防止溢出:
// Example 7.44c
x.abc = (A & 0x0F) | ((B & 3) << 4) | ((C & 3) <<6 );7.28 Overloaded functions
重载函数的不同版本仅被视为不同的函数。使用重载函数没有性能惩罚。
7.29 Overloaded operators
重载运算符与函数等效。使用重载运算符的效率与使用执行相同操作的函数完全相同。
具有多个重载运算符的表达式将导致为中间结果创建临时对象,这可能是不希望发生的。例如:
// Example 7.45a
class vector { // 2-dimensional vector
public:
float x, y; // x,y coordinates
vector() {} // default constructor
vector(float a, float b) {x = a; y = b;} // constructor
vector operator + (vector const & a) { // sum operator
return vector(x + a.x, y + a.y);} // add elements
};
vector a, b, c, d;
a = b + c + d; // makes intermediate object for (b + c)可以通过将操作组合起来来避免为中间结果(b+c)创建临时对象:
// Example 7.45b
a.x = b.x + c.x + d.x;
a.y = b.y + c.y + d.y;幸运的是,在简单的情况下,大多数编译器会自动进行这种优化操作。
7.30 Templates
模板与宏类似,模板参数在编译之前被替换为它们的值。以下示例说明了函数参数和模板参数之间的区别:
// Example 7.46
int Multiply (int x, int m) {
return x * m;}
template <int m>
int MultiplyBy (int x) {
return x * m;}
int a, b;
a = Multiply(10,8);
b = MultiplyBy<8>(10);a和b都将获得值10 * 8 = 80。区别在于如何将m传递给函数。在简单的函数中,m在运行时从调用者传递到被调用的函数。但是在模板函数中,m在编译时被其值替换,因此编译器看到的是常量8而不是变量m。使用模板参数而不是函数参数的优点是避免了参数传递的开销。缺点是编译器需要为每个不同的模板参数值创建一个新的模板函数实例。如果在这个示例中使用MultiplyBy来调用很多不同的因子作为模板参数,那么代码可能会变得非常庞大。
在上面的示例中,模板函数比简单函数更快,因为编译器知道可以通过使用移位操作来乘以2的幂次方。x*8被替换为x<<3,这样速度更快。对于简单函数,编译器不知道m的值,除非函数可以内联,否则无法进行优化。(在上面的示例中,编译器能够内联和优化两个函数,并将80直接放入a和b中。但在更复杂的情况下,编译器可能无法这么做)。
模板参数也可以是类型。第38页的示例展示了如何使用相同的模板创建不同类型的数组。
模板高效的原因是模板参数始终在编译时解析。模板使源代码更复杂,但不会使编译后的代码变得复杂。一般来说,使用模板不会在执行速度方面产生额外的开销。
如果模板参数完全相同,则两个或多个模板实例将合并为一个实例。如果模板参数不同,则会为每组模板参数集合生成一个实例。具有许多实例的模板会使编译后的代码变得庞大,并使用更多的缓存空间。
过度使用模板会使代码难以阅读。如果模板只有一个实例,您可以考虑使用#define、const或typedef来代替模板参数。
模板还可以用于元编程,详见第163页的解释。
Using templates for polymorphism
模板类可以用于实现编译时多态,这比通过虚成员函数获得的运行时多态更高效。以下示例首先展示了运行时多态:
// Example 7.47a. Runtime polymorphism with virtual functions
class CHello {
public:
void NotPolymorphic(); // Non-polymorphic functions go here
virtual void Disp(); // Virtual function
void Hello() {
cout << "Hello ";
Disp(); // Call to virtual function
}
};
class C1 : public CHello {
public:
virtual void Disp() {
cout << 1;
}
};
class C2 : public CHello {
public:
virtual void Disp() {
cout << 2;
}
};
void test () {
C1 Object1; C2 Object2;
CHello * p;
p = &Object1;
p->NotPolymorphic(); // Called directly
p->Hello(); // Writes "Hello 1"
p = &Object2;
p->Hello(); // Writes "Hello 2"
}如果编译器不知道指针p所指向的对象是哪个类(参见第76页),则在运行时将派发给C1::Disp()或C2::Disp()。在这种情况下,最好的编译器可以优化掉p,并且在像这样的情况下内联调用Object1.Hello()。
如果在编译时已知对象属于C1类还是C2类,我们可以避免低效的虚函数派发过程。这可以通过一种特殊的技巧来实现,该技巧在Active Template Library (ATL)和Windows Template Library (WTL)中被使用:
// Example 7.47b. Compile-time polymorphism with templates
// Place non-polymorphic functions in the grandparent class:
class CGrandParent {
public:
void NotPolymorphic();
};
// Any function that needs to call a polymorphic function goes in the
// parent class. The child class is given as a template parameter:
template <typename MyChild>
class CParent : public CGrandParent {
public:
void Hello() {
cout << "Hello ";
// call polymorphic child function:
(static_cast<MyChild*>(this))->Disp();
}
};
// The child classes implement the functions that have multiple
// versions:
class CChild1 : public CParent<CChild1> {
public:
void Disp() {
cout << 1;
}
};
class CChild2 : public CParent<CChild2> {
public:
void Disp() {
cout << 2;
}
};
void test () {
CChild1 Object1; CChild2 Object2;
CChild1 * p1;
p1 = &Object1;
p1->Hello(); // Writes "Hello 1"
CChild2 * p2;
p2 = &Object2;
p2->Hello(); // Writes "Hello 2"
}在这里,CParent是一个模板类,通过模板参数获取有关其子类的信息。它可以通过将'this'指针转换为指向其子类的指针来调用其子类的多态成员。只有当它的模板参数与正确的子类名称相同时,才是安全的。换句话说,您必须确保声明
class CChild1 : public CParent<CChild1> {
中的子类名称和模板参数名称相同。
继承顺序如下。第一代类(CGrandParent)包含任何非多态成员函数。第二代类(CParent<>)包含需要调用多态函数的任何成员函数。第三代类包含多态函数的不同版本。第二代类通过模板参数获取有关第三代类的信息。
如果已知对象的类,则不会浪费时间在运行时派发到虚成员函数上。这些信息包含在具有不同类型的p1和p2中。缺点是CParent::Hello()具有占用缓存空间的多个实例。
诚然,示例7.47b中的语法非常混乱。通过避免虚函数派发机制可能节省的几个时钟周期很少足以证明使用这种复杂且难以理解和难以维护的代码是合适的。如果编译器能够自动执行去虚拟化(参见第76页),则依赖于编译器优化肯定更方便,而不是使用这种复杂的模板方法。
7.31 Threads
线程被用于同时或看似同时地完成两个或多个任务。现代CPU具有多个核心,可以同时运行多个线程。当线程数量超过CPU核心数时,每个线程通常会获得30毫秒的前台作业时间片和10毫秒的后台作业时间片。每次时间片结束后的上下文切换是非常昂贵的,因为所有缓存都必须适应新的上下文。通过延长时间片可以减少上下文切换的次数。这样做会使应用程序以更快的速度运行,但以用户输入响应时间的延长为代价。
线程对于给不同的任务分配不同的优先级非常有用。例如,在文字处理器中,用户期望按下键盘键或移动鼠标时能立即得到响应。这个任务必须具有高优先级。其他任务,如拼写检查和重新排版,以较低的优先级在其他线程中运行。如果没有将不同的任务划分为具有不同优先级的线程,那么当程序繁忙进行拼写检查时,用户可能会遇到无法接受的长时间响应键盘和鼠标输入的情况。
任何需要很长时间的任务,比如大量的数学计算,在具有图形用户界面的应用程序中应该在一个单独的线程中进行调度。否则,程序将无法迅速响应键盘或鼠标输入。
在不调用操作系统线程调度器的开销的情况下,可以在应用程序中实现类似线程调度的功能。这可以通过在图形用户界面的消息循环中逐步进行繁重的后台计算来实现(在Windows MFC中称为OnIdle)。在CPU核心较少的系统中,这种方法可能比创建单独的线程更快,但它要求后台作业可以分成适当时长的小片段。
充分利用多CPU核心系统的最佳方法是将任务分成多个线程。然后每个线程可以在自己的CPU核心上运行。
当优化多线程应用程序时,我们必须考虑四种多线程的成本:
• 启动和停止线程的成本。如果将一个任务放入单独的线程中,而该任务与启动和停止线程所需的时间相比较很短,则不要这样做。
• 任务切换成本。如果具有相同优先级的线程数不超过CPU核心数,则可以最小化此成本。
• 线程之间同步和通信的成本。信号量、互斥量等的开销很大。如果两个线程经常等待对方以获取对同一资源的访问权限,则最好将它们合并为一个线程。共享于多个线程的变量必须声明为volatile。这可防止编译器将该变量存储在寄存器中,因为寄存器不是线程之间共享的。
• 不同的线程需要分别存储。任何被多个线程使用的函数或类都不应依赖于静态或全局变量。 (请参见第28页的线程局部存储)线程都有自己的堆栈。如果线程共享同一个缓存,则可能会导致缓存争用。
多线程程序必须使用线程安全函数。线程安全的函数不应使用静态变量。
有关多线程技术的技巧进一步讨论,请参见第10章第110页。
7.32 Exceptions and error handling
运行时错误会导致异常,可以以陷阱或软件中断的形式检测到。通过使用try-catch块,可以捕获这些异常。如果启用了异常处理并且没有try-catch块,则程序将崩溃并显示错误消息。
异常处理旨在检测很少发生的错误并以优雅的方式从错误条件中恢复。您可能认为只要没有发生错误,异常处理就不需要额外的时间,但不幸的是,这并非总是正确的。程序可能需要进行大量的簿记记录,以便在发生异常时知道如何进行恢复。这种簿记记录的成本在很大程度上取决于编译器。一些编译器具有高效的基于表格的方法,几乎没有任何开销,而另一些编译器则具有低效的基于代码的方法或需要运行时类型识别(RTTI),这会影响到代码的其他部分。有关进一步解释,请参见ISO / IEC TR18015 C ++性能技术报告。
下面的示例说明为什么需要簿记记录:
// Example 7.48
class C1 {
public:
...
~C1();
};
void F1() {
C1 x;
...
}
void F0() {
try {
F1();
}
catch (...) {
...
}
}当函数F1返回时,应该调用对象x的析构函数。但是如果在F1中的某个地方发生了异常怎么办?那么我们将在没有返回的情况下退出F1。由于被中断,F1无法进行清理工作。现在异常处理程序有责任调用x的析构函数。只有在F1保存了有关要调用的析构函数或其他可能需要清理的所有信息时,才能实现这一点。如果F1调用另一个函数,而该函数又调用另一个函数,依此类推,如果最内层的函数发生异常,那么异常处理程序需要获取有关函数调用链的所有信息,并且需要逆向跟踪函数调用以检查是否需要进行所有必要的清理工作。这就是所谓的堆栈展开。
所有函数都必须为异常处理程序保存一些信息,即使永远不会发生异常。这就是为什么在某些编译器中,异常处理可能会很昂贵的原因。如果您的应用程序不需要异常处理,则应该在编译器中禁用它以使代码更小、更高效。您可以通过关闭编译器中的异常处理选项来为整个程序禁用异常处理。您可以通过在函数原型中添加throw()来禁用单个函数的异常处理:
void F1() throw();这样可以让编译器假设F1不会抛出任何异常,因此它不需要为函数F1保存恢复信息。然而,如果F1调用可能会抛出异常的另一个函数F2,那么F1必须检查F2抛出的异常,并在F2实际抛出异常时调用std::unexpected()函数。因此,只有当F1调用的所有函数也具有空的throw()规范时,才应将空的throw()规范应用于F1。空的throw()规范对于库函数非常有用。
编译器对叶子函数和框架函数进行区分。框架函数是至少调用一个其他函数的函数。叶子函数是不调用任何其他函数的函数。如果可以排除异常或在发生异常时没有清理工作要做,叶子函数比框架函数更简单,因为可以省略堆栈展开信息。通过内联调用它所调用的所有函数,可以将框架函数转换为叶子函数。如果程序的关键最内部循环不包含对框架函数的调用,则可以获得最佳性能。
虽然在某些情况下空的throw()语句可以提高优化效果,但没有理由添加类似throw(A,B,C)的语句来明确告知函数可能抛出的异常类型。实际上,编译器可能会添加额外的代码来检查抛出的异常是否确实是指定的类型(参见Sutter:《一种实用的异常规范观点》,Dr Dobbs Journal,2002年)。
在某些情况下,在程序的最关键部分使用异常处理是最优的。如果替代实现效率较低且希望能够从错误中恢复,则需要这样做。以下示例说明了这种情况:
// Example 7.49
// Portability note: This example is specific to Microsoft compilers.
// It will look different in other compilers.
#include <excpt.h>
#include <float.h>
#include <math.h>
#define EXCEPTION_FLT_OVERFLOW 0xC0000091L
void MathLoop() {
const int arraysize = 1000; unsigned int dummy;
double a[arraysize], b[arraysize], c[arraysize];
// Enable exception for floating point overflow:
_controlfp_s(&dummy, 0, _EM_OVERFLOW);
// _controlfp(0, _EM_OVERFLOW); // if above line doesn't work
int i = 0; // Initialize loop counter outside both loops
// The purpose of the while loop is to resume after exceptions:
while (i < arraysize) {
// Catch exceptions in this block:
__try {
// Main loop for calculations:
for ( ; i < arraysize; i++) {
// Overflow may occur in multiplication here:
a[i] = log (b[i] * c[i]);
}
}
// Catch floating point overflow but no other exceptions:
__except (GetExceptionCode() == EXCEPTION_FLT_OVERFLOW
? EXCEPTION_EXECUTE_HANDLER : EXCEPTION_CONTINUE_SEARCH) {
// Floating point overflow has occurred.
// Reset floating point status:
_fpreset();
_controlfp_s(&dummy, 0, _EM_OVERFLOW);
// _controlfp(0, _EM_OVERFLOW); // if above doesn't work
// Re-do the calculation in a way that avoids overflow:
a[i] = log(b[i]) + log(c[i]);
// Increment loop counter and go back into the for-loop:
i++;
}
}
}假设b[i]和c[i]中的数字非常大,导致在乘法b[i]*c[i]中可能发生溢出,尽管这种情况很少发生。上述代码将在溢出时捕获异常,并以一种需要更多时间但避免溢出的方式重新计算。取每个因子的对数而不是乘积可以确保不会发生溢出,但计算时间加倍。
在支持异常处理方面所需的时间是可以忽略不计的,因为在关键的最内部循环中,除了log之外,没有try块或函数调用。我们假设log是经过优化的库函数。无论如何,我们无法改变其可能的异常处理支持。当异常发生时,它是昂贵的,但这并不是问题,因为我们假设出现的情况很少。
在循环内部进行溢出条件的测试在这里不会带来任何开销,因为我们依赖微处理器硬件来在溢出时引发异常。如果存在try块,操作系统将捕获异常并将其重定向到程序中的异常处理程序。
捕获硬件异常存在可移植性问题。该机制依赖于编译器、操作系统和CPU硬件中的非标准化细节。将这样的应用程序移植到不同的平台可能需要修改代码。
让我们来看看在这个例子中可能的异常处理替代方案。我们可以通过检查b[i]和c[i]是否过大来检测溢出。这将需要两次浮点数比较,因为它们必须在最内部循环中。另一种可能性是始终使用安全的公式a[i] = log(b[i]) + log(c[i])。这将使log的调用次数加倍,而且计算对数需要很长时间。如果有一种方法可以在循环之外检查溢出而无需检查所有数组元素,那么这可能是一个更好的解决方案。如果所有的因子都是从相同的几个参数生成的,则可能在循环之前进行这样的检查。或者,如果结果通过某个公式组合成单个结果,则可能在循环之后进行检查。
Exceptions and vector code
矢量指令对于并行执行多个计算非常有用。这在下面的第12章中进行了描述。异常处理与矢量代码不太兼容,因为矢量中的单个元素可能会引发异常,而其他矢量元素则不会。甚至在未执行分支的情况下,由于矢量代码实现的方式,可能会生成异常。如果代码可以受益于矢量指令,则最好禁用异常陷阱,依靠NAN和INF的传播。参见下面的第7.34章节。关于这一点在www.agner.org/optimize/nan_propagation.pdf文档中进一步进行了讨论。
Avoiding the cost of exception handling
如果没有尝试从错误中恢复,那么异常处理是不必要的。如果您只希望程序在出现错误时发出错误消息并停止运行,那么就没有理由使用try、catch和throw。定义自己的错误处理函数,简单地打印适当的错误消息,然后调用exit更高效。
如果存在需要清理的已分配资源,则调用exit可能不安全,如下所述。在不使用异常的情况下,还有其他处理错误的方式。检测到错误的函数可以返回一个错误代码,调用该函数的函数可以使用它来恢复或发出错误消息。
建议使用系统性和经过深思熟虑的错误处理方法。您必须区分可恢复和不可恢复的错误;确保在发生错误时清理已分配的资源;并向用户返回适当的错误消息。
Making exception-safe code
假设一个函数以独占模式打开文件,但在文件关闭之前发生错误导致程序终止。在程序终止后,文件将保持锁定状态,用户将无法访问该文件,直到计算机重新启动。为了防止这种问题,您必须使程序具备异常安全性。换句话说,程序必须在异常或其他错误情况下清理一切。可能需要清理的内容包括:
• 使用new或malloc分配的内存。
• 窗口句柄、图形刷等。
• 锁定的互斥量。
• 打开的数据库连接。
• 打开的文件和网络连接。
• 需要删除的临时文件。
• 需要保存的用户工作。
• 任何其他已分配的资源。
在C++中处理清理工作的方式是使用析构函数。读取或写入文件的函数可以封装为一个带有析构函数的类,确保文件被关闭。同样的方法也适用于任何其他资源,如动态分配的内存、窗口、互斥量、数据库连接等。
C++的异常处理系统确保调用所有局部对象的析构函数。如果存在具有析构函数的包装类来处理所有已分配资源的清理工作,则程序具备异常安全性。如果析构函数引发另一个异常,系统可能会失败。
如果您自己创建错误处理系统而不是使用异常处理,那么就无法确保调用所有析构函数并清理资源。如果错误处理程序调用exit()、abort()、_endthread()等,那么无法保证调用所有析构函数。在不使用异常的情况下处理不可恢复的错误的安全方式是从函数中返回。该函数可以返回错误代码(如果可能),或者错误代码可以存储在全局对象中。调用该函数的函数必须检查错误代码。如果后续函数还有需要清理的内容,则必须返回到其自身的调用者,依此类推。
7.33 Other cases of stack unwinding
上述段落描述了一种称为堆栈展开(stack unwinding)的机制,它被异常处理程序用于在异常情况下跳出函数时进行清理和调用必要的析构函数,而不使用正常的返回路径。该机制还在另外两种情况下使用:
当线程终止时,可以使用堆栈展开机制。其目的是检测线程中是否有声明了需要调用析构函数的对象。建议在终止线程之前从需要清理的函数中返回。不能确定调用_endthread()是否清理堆栈。这个行为依赖于具体实现。
当使用函数longjmp进行函数跳转时,也会使用堆栈展开机制。如果可能,避免使用longjmp。在时间关键的代码中不要依赖longjmp。
7.34 Propagation of NAN and INF
在大多数情况下,浮点数错误会传播到一系列计算的最终结果中。这是一种非常高效的异常处理和错误捕获的替代方法。
浮点数溢出和除以零会得到无穷大。如果你将无穷大与其他值相加或相乘,结果仍然是无穷大。在这种情况下,无穷大的代码可能会传播到最终结果。然而,并不是所有对无穷大的操作都会得到无穷大的结果。如果你用一个常规数除以无穷大,结果是零。特殊情况下,无穷大减去无穷大(INF-INF)和无穷大除以无穷大(INF/INF)会得到非数字(NAN)。当你除以零或者函数的输入超出范围(比如sqrt(-1)和log(-1))时,也会得到特殊代码NAN。
大多数带有NAN输入的操作会得到NAN输出,因此NAN会传播到最终结果。这是一种简单而高效的检测浮点数错误的方式。几乎所有的浮点数错误都会传播到最终结果,表现为无穷大或非数字。如果你打印输出结果,你会看到无穷大或非数字而不是一个数。不需要额外的代码来追踪错误,传播无穷大和非数字也没有额外的开销。
一个NAN可以携带额外的有效载荷信息。函数库可以在发生错误时将错误代码放入有效载荷中,这个有效载荷会传播到最终结果。
当参数为无穷大或非数字时,函数finite()会返回false,如果参数是一个常规浮点数,则返回true。这可以用于在浮点数转换为整数之前检测错误,以及其他需要检查错误的情况。
有关无穷大和非数字传播的详细信息可参考文档"NAN propagation versus fault trapping in floating point code",网址为www.agner.org/optimize/nan_propagation.pdf。该文档还讨论了无穷大和非数字传播失败的情况,以及影响这些代码传播的编译器优化选项。
7.35 Preprocessing directives
预处理指令(以#开头的部分)在程序性能方面是零成本的,因为它们在程序编译之前就解析了。
#if 指令对于支持多个平台或使用相同源代码的多个配置非常有用。因为#if 在编译时解析,所以比 if 更高效,if 是在运行时解析。
#define 指令在定义常量时与 const 定义等效。例如,#define ABC 123 和 const int ABC = 123; 是同样高效的,因为在大多数情况下,优化编译器可以将整数常量替换为其值。然而,在某些情况下,const int 声明可能占用内存空间,而 #define 指令永远不会占用内存空间。浮点数常量总是占用内存空间,即使没有被命名。
当作为宏使用时,#define 指令有时比函数更高效。请参阅第48页进行讨论。
7.36 Namespaces
使用命名空间在执行速度方面没有开销。
















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









