






3.1 THE RISC CONCEPT
现今的管理咨询师和商业作家告诫美国企业要抛弃古老格言和过去的老套方法,尝试不同的思维方式。这正是IBM T.J.沃森研究中心在1970年代末做的事情。在那个时候,半导体工艺的进步提供了越来越多的集成境遇,人们欢迎它作为增加CPU复杂性的手段。旧架构提供了简单的构造,例如使用简单寻址模式进行加载、存储和加法。随着更高的集成度,程序员可以提供单个指令,对基于多个内存操作符的运算对象进行乘除或执行简单级数逼近函数的子集,使用高度精密的寻址技术。这种方法很大程度上增加了代码密度。 IBM的研究表明, CPU的大部分工作都是用来执行简单的读写功能,而不是使用复杂的寻址。这应该不足为奇。令人惊讶的是,加载和存储操作与其他任何操作的比例如此之高,以至于简化其他操作或添加更复杂的指令的优点与提高加载/存储指令速度的效果相比显得微不足道。各大学进行的进一步研究表明,如果编译器仅使用富指令集的子集,专注于执行速度最快的指令,无论它们的操作多么简单,都可以生成更快的代码。即使对于英特尔的CISC处理器系列,从Pentium开始也是如此。英特尔费尽心思地向软件公司提供优化编译器,以确保新软件充分利用处理器吞吐量。抛弃复杂的寻址模式!摆脱任何高级指令!只需加速加载和存储!让我们看一个数字例子。假设编译器生成的代码(基于跟踪)按以下比例执行:从简单地址加载40%,存储到简单地址40%,分支/跳转/推送/弹出5%,寄存器之间的操作3%。这应该看起来是完全合理和可信的,特别是对于那些在386时代,在昂贵的数学协处理器添加后,非常失望于其PC性能没有得到显著提高的人们。在这个例子中,如果可以将使用简单地址的加载和存储速度提高2.5%(1-39/40),则对更复杂地址的引用可以减慢两倍,程序仍然会运行同样快。
3.1.1 The CISC Bottleneck

那么谁在乎呢?CPU的设计者在乎!CPU的最大时钟速度由两个简单的因素决定:门传播延迟和关键路径上的门数量。所有处理器设计都有点循环性质。数据或指令必须在下一个时钟周期中按时环绕循环路径被时钟锁存到寄存器中。流水线系统通过在循环路径的中间点添加寄存器,并以更快的速率进行时钟锁存来加快这个过程(在某些情况下除外)(参见图3.1)。任何CPU的最小时钟周期时间由寄存器时钟之间的最大延迟长度路径设定。在CISC处理器中,更丰富的指令集的增加会逐步向这个关键路径添加门。
了解图灵机的人会意识到,通过使用一个非常简单的机器,可以解决各种各样的问题。如果CPU的速度是由涉及十个门的延迟路径决定的,并且如果我们可以通过精简一半的指令集来消除一个门,那么考虑到CPU刚刚变快了10%,去除这个门和它所支持的所有指令可能是值得的。根据刚刚展示的编译器统计数据,在不涉及复杂引用的所有指令中实现10%的改进,将使得复杂引用的计算时间最多延长六倍,而不会影响系统性能!在这一点上,显然很明显,与可能对所有其他指令造成负担的硬件实现相比,以更高的速度提供更复杂指令的软件替代方案实际上可能是一个非常好的权衡选择。
减小指令集计算机(RISC)的方法是基于同时减小指令集大小和周期时间的原则,找到最小化的指令集。与许多研究一样,这个过程最终并不客观,因此产生了几种RISC架构。不过,RISC处理器的指令集如此相似,以至于作者的一个朋友声称,如果读者从中间开始阅读处理器的指令手册,根本无法分辨是哪个处理器。所有的RISC CPU都专注于简单的加载和存储操作,在寄存器之间进行算术和逻辑运算。相反,CISC CPU通常允许将内存用作算术和逻辑运算的源和目的地,并且很可能支持一些相当奇特的地址模式。
3.1.2 The Rise Architect's Goal
在设计RISC处理器时的目标是使最常用的指令尽可能快地运行,虽然这会导致指令集复杂性的降低。相比较而言,CISC处理器通常会提供执行一个低级别指令子程序所需功能的指令,但执行这些指令可能需要多达30个周期。我们必须权衡减少执行代码的效用、增加代码密度的效果和更频繁遇到的指令的执行速度,就像在第3.1节的示例统计中所展示的一样。
RISC架构的重要目标是尽可能每个周期执行尽可能多的指令。为了实现这一点,设计师往往广泛使用流水线技术,甚至使用分支预测作为一种尝试在处理器实际请求指令之前获取适当指令的方法。在一种非常简单的分支预测形式中,当获取一条指令时,下一个内存位置的地址,极有可能是下一条将被使用的指令,已经被输出到内存系统。当然,还有更复杂的算法,但这种简单的分支预测对我们来说已经足够。
只要代码按线性方式运行,并且不进行主存数据访问,处理器确实可以在每个时钟周期执行一条指令。当对主存进行数据访问时,将消耗额外的周期,使得每条指令的周期数增加一部分(尽管通过允许处理其他不需要通过主存加载数据的指令,这可能有时对RISC处理器来说是隐藏的)。此外,当分支被执行时,由于简单预测单元选择的分支将不会被预测到,至少会浪费一个周期,直到输出地址从合理的估计值变为CPU所需的实际地址。这有时可以通过允许在分支指令之后执行指令来解决。
RISC处理器往往不支持像跳转到子程序这样复杂的指令,因为在加载目标地址时,会消耗多个周期,并且在将程序计数器的先前内容推送到堆栈(通常位于主存中)时也会消耗多个周期。这将导致每条指令所需的时钟周期数增加,这在RISC处理器的世界中是不可接受的。相反,子程序往往将程序计数器放入寄存器中,并让编译器处理上下文切换的细节。
3.1.3 Interaction of Software and Hardware
RISC架构的整体方程中,软件起到了相当大的支撑作用。一些RISC销售支持程序甚至提供了具有不同缓存配置的系统模型,以便设计者可以在确定系统构建方式之前,测试特定代码在各种缓存策略下的性能。当然,如果我们在前面的示例中放弃了复杂的引用,并将其替换为配置不良的代码片段,那么所有这些都无法协同工作。为了从高速硬件中获得最大的速度,软件需要充分利用支持的特定处理器。
整个RISC解决方案不仅仅依赖于对硬件的优化(再次基于统计数据的测量),还依赖于使用优化编译器,进一步将编译后的代码的统计数据朝着加速处理器吞吐量的方向倾斜。
3.1.4 Optimizing Compilers

编译器如何优化代码,这对缓存性能有什么影响?通过阅读本书,您应该意识到理解软件与硬件整体性能之间的相互作用的重要性。通过了解您特定的优化编译器如何工作,您将更好地能够优化缓存策略。在第3.1.2节中,简要讨论了分支。每当取一个分支时,处理器通常需要消耗一个额外的时钟周期,以便程序计数器有足够的时间重新加载自己。这意味着任何循环都会比运行相同的几个指令重复一次的线性代码运行得更慢。速度提升的百分比与循环长度成反比。优化编译器将检查使用固定重复次数的循环,确定如果循环被展开,代码会变得过大,评估保留循环和展开循环(有时称为展开)之间的速度折衷,基于循环长度,然后决定使用循环还是高度重复的线性代码(见表3.1)。
类似地,优化编译器将决定是否将子例程保留为子例程或将多个副本嵌入到调用它的少数代码位置中。子例程调用不仅由于重新加载程序计数器而具有延迟,还可能需要大量的堆栈支持来保存和恢复上下文,导致高延迟,通过这种优化过程可以完全消除高延迟。
RISC体系结构更加关注寄存器,并具有富有寄存器的CPU。这意味着支持这些CPU的编译器将专注于将频繁的内存访问转换为寄存器访问,结果是外部数据传输与指令调用数量比例失衡。
除了使反汇编代码难以跟踪之外,所有这些对缓存设计者意味着什么?首先,使用直线代码而不是小循环倾向于使更长的线路长度成为一个更合理的选择,因为在这种优化的代码中很可能进行更高数量的顺序访问。其次,在第1章和第2章中,我们探讨了对于由于子例程调用及其随后的堆栈操作而产生的冲突而遭受抖动的系统,更高联想性高速缓存的重要性。如果将几个子例程拉入调用例程中,将会有较少的地址冲突和堆栈访问,从而稍微降低使用更高缓存联想性带来的改进。再次强调,代码将更加内嵌,而不是被分成子例程,因此较长的线路将比使用非优化编译器时更可行。第三,如果大多数时间都在寄存器之间传递数据,并且通过在寄存器丰富的机器上使用优化代码,数据加载和存储显著减少,则设计者应该更加注重发挥指令缓存的作用,而不是数据缓存。最后一个观点得到了加强,即对于小指令集的优化代码,其大小将明显大于非优化的CISC等价物。
3.1.5 Architectural Trade-offs
处理器架构师必须在速度和其可能提供的许多功能之间进行权衡。如果要最大化每个时钟周期的指令数,指令、操作数和目的地必须同时对CPU可用,而不是按顺序访问。此外,一些大的延迟可能会发生在内存管理单元内。这些权衡的方法决定了缓存设计的两个重要方面,两者都已用于某些RISC处理器设计中以减少门延迟路径。
3.1.5.1 Harvard vs. Von Neumann
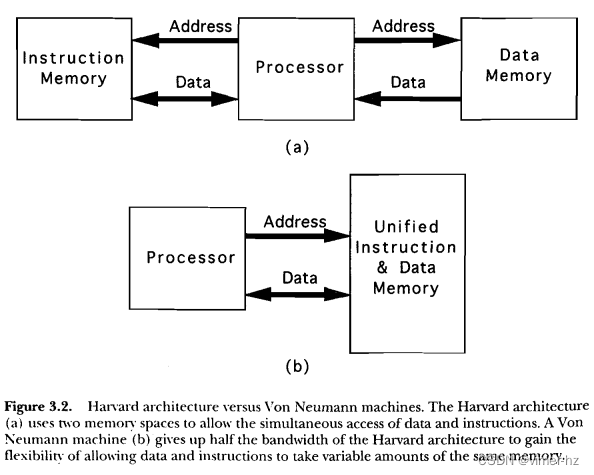
冯·诺伊曼体系结构如此普遍地使用,以至于哈佛体系结构和冯·诺伊曼机器几乎听不到这些术语。简单来说,虽然冯·诺伊曼机器有一个单一的地址空间,其中任何部分都可以作为指令或数据访问,而哈佛体系结构使用两个独立的固定大小空间:一个用于指令,一个用于数据。这自动意味着哈佛机器可以在单个周期内加载或操作数据,并通过指令总线从指令空间获取指令,数据通过数据总线加载或存储到数据存储器中(图3.2a)。也暗示了冯·诺伊曼机器(图3.2b)必须在单个内存空间的单个数据总线上,在两个单独的周期中获取指令,然后加载或存储操作数。当然,任何追求性能的机器都会尝试减少需要对主存储器进行两次访问的指令数量。在任何类型的CPU中获得惊人的速度优势的一种方法是允许同时访问指令和数据。有两种基本方法可以做到这一点。第一种方法是设计具有富有寄存器的冯·诺伊曼体系结构,其中大多数指令作用于两个寄存器中包含的数据,而不是存储在内存中的数据。在寄存器丰富的RISC机器中,访问指令,对芯片寄存器中间的数据执行某些功能,并将数据写回到这些寄存器之一,全部在单个周期内完成。(实际上,处理器的内部流水线将任何一个指令分散在几个周期中,但由于同时操作多个指令,所以有效的指令执行时间不到一个时钟周期。)寄存器丰富的体系结构的优化编译器会尝试确保最常使用的操作数将映射到寄存器(寄存器供应短缺),而很少使用的操作数则永远不会映射到寄存器,而是驻留在主存储器中。通过这种方法,大部分数据访问将被隐藏在总线之后,总线活动的大部分将围绕指令获取,强制访问比在将指令和数据操作数更随机地交织的机器中更加顺序化。这直观地意味着长的线路可能是这样的机器非常好的缓存策略,并且一个单独的指令缓存可以提高吞吐量,就像一个组合缓存一样。
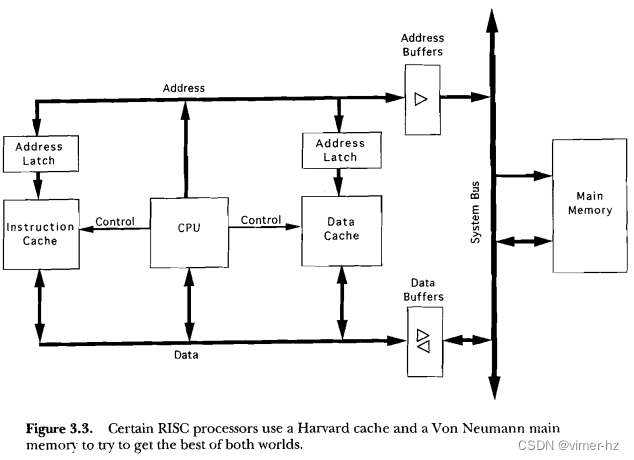
其他RISC处理器使用冯·诺伊曼风格的统一内存空间作为主存储器,但将缓存分为指令和数据空间,使得CPU缓存子系统呈现出哈佛架构的特征(见图3.3)。数据和指令同时来自两个不同的存储器,通过两个不同的总线传输。一个单独的内部累加器提供一个操作数并存储结果。现在,指令获取和数据加载/存储可以在同一个周期内进行,但整个系统仍然具有冯·诺伊曼机器的主存储器灵活性。这种方法使得处理器的性能不再依赖于CPU的寄存器集的大小。
哈佛架构具有两个优点。首先,编译器在管理寄存器内容以确保数据很快且频繁地被使用方面需要更少的注意。其次,在具有高级流水线的寄存器丰富型机器中,可能存在后续指令需要早期指令产生的数据,而这些数据尚未从流水线中传出的可能性。通过计分板技术来处理这些问题,该过程使用特定的标志位来表示寄存器中的数据是否是最新可用的。这个过程的实现较为复杂,并且当一条指令必须等待其操作数可用时,会导致延迟。
3.1.5.2 Physical vs. Logical Caches

回顾一下,在2.2.1节中,我们讨论了逻辑缓存和物理缓存的属性。在RISC设计中,按照减少门延迟的RISC理念,只使用逻辑缓存似乎是合适的选择。你可能还记得逻辑缓存位于内存管理单元的处理器侧,其延迟较小,而物理缓存位于MMU延迟的下游(图3.4)。
一些RISC处理器通过增加流水线的深度来解决MMU延迟问题,从而隐藏了对缓存的延迟。这可能对设计师提出了挑战,但简化了一个我们将在第4章遇到的问题,即在逻辑缓存中维持一致性。
3.2 FEEDING INSTRUCTIONS TO A RISC CPU
设计一个快速的CPU,然后让它等待慢速的内存接口是不负责任的。因此,我们要在RISC处理器和缓存之间进行竞争。甚至有一位处理器架构师建议在设计处理器之前先为缓存设计最佳速度和命中率。这似乎有点极端,因为如果你不知道编译器将生成什么样的代码,很难优化缓存的命中率,而且编译器将根据处理器的架构进行优化。最重要的是,整个系统必须作为一个整体来设计,每个部分都会影响其他部分的设计。即使是一个出色的缓存,如果与糟糕的主存储器相配合,也可能比一个缓存不足但设计非常良好的主存储器的系统性能差。
与任何CPU一样,RISC处理器大部分主存储器的访问用于获取指令。因此,那些将大部分注意力放在优化指令访问上的设计师将设计出最佳的缓存。缓存设计师可以借鉴RISC处理器架构师的经验,简化设计以减少门延迟。大多数RISC处理器的设计者主张在芯片上放置一个小型的一级缓存和一个较大的二级缓存,而不是一个单独的较大缓存,这样一来一级缓存可以用最少的门延迟来构建。SRAM越小,地址译码器中的门延迟就越少。
3.3 PROBLEMS UNIQUE TO RISC CACHES
如果高速缓存无法满足处理器对数据的贪婪需求,整个RISC哲学就会崩溃。要记住的是,RISC的假设是通过减少关键时序环路中的延迟路径来加速处理器的时钟频率。缓存是这个环路的一个组成部分。设计一个非常快的处理器有什么用,如果在每个单独的指令周期中都要等待缓存访问延迟呢?
在高时钟频率下支持零等待击中可能会带来很大的问题。简单地说,进入和离开一个硅片通常需要约3纳秒的时间(假设使用TTL I/O电平)。由于缓存RAM和CPU通常是两个不同的硅片,因此6纳秒可以在芯片间通信中消失。即使其余延迟总共只有1纳秒,这样系统的最大时钟频率也只有166MHz,已经低于大多数当前处理器的时钟速度!
为了解决这个问题,处理器设计师总是在CPU芯片本身上放置至少一个缓存。这么做有一个相当好的理由,因为即使是小缓存也往往具有相对较高的命中率。然而,这并不免除缓存设计师的速度问题。在写作本文时,RISC二级缓存设计的问题仍然非常棘手,通常需要使用极高速的同步SRAM。
当然,在RISe缓存中,与2.5.1节中提到的相同的引脚负载问题变得更为严重,特别是在RISC CPU现在提供的高时钟频率下。降额,在较低时钟频率下可以忽略不计,但在更高的速度下就成为一个决定性因素了。大多数架构采用的方法是使用最广泛的设备和最先进的密度来实现缓存数据RAM。通过减少由CPU地址总线驱动的设备数量,可以避免电容负载的有害影响。
















 3293
3293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









