






有许多编程语言,以及用于执行这些语言的编译器和运行时环境,而每种语言的执行方式会影响其跟踪方法。本章解释了这些差异,并将帮助您找到跟踪任何给定语言的方法。
学习目标:
- 理解编译语言的插桩(例如:C)
- 理解 JIT 编译语言的插桩(例如:Java、Node.js)
- 理解解释语言的插桩(例如:bash shell)
- 尽可能跟踪函数调用、参数、返回值和延迟
- 跟踪给定语言的用户级栈跟踪
本章首先总结了编程语言的实现,然后使用几种语言作为示例:C 代表编译语言,Java 代表 JIT 编译语言,bash shell 脚本代表完全解释语言。对于每种语言,我都会介绍如何查找函数名称(符号)、函数参数,并如何调查和跟踪栈跟踪。在本章末尾,我还包括了跟踪其他语言的说明:JavaScript(Node.js)、C++ 和 Golang。
无论您对哪种语言感兴趣,本章都将为您提供插桩的起步点,并帮助您了解其他语言中已经解决的挑战和解决方案。
12.1 Background
要理解如何对给定的语言进行插桩,您需要检查它是如何转换为机器代码以供执行的。这通常不是语言本身的特性,而是语言实现的特性。例如,Java 并不是一种 JIT 编译语言:Java 只是语言本身。常用的 OracleJDK 或 OpenJDK 提供的 JVM 运行时通过一个从解释到 JIT 编译的流水线来执行 Java 方法,但这属于 JVM 的特性。JVM 本身也是编译自 C++ 代码的,执行诸如类加载和垃圾回收等功能。在一个完全插桩的 Java 应用中,您可能会遇到已经编译的(C++ JVM 函数)、解释的(Java 方法)以及 JIT 编译的(Java 方法)代码——每种类型的代码有不同的插桩方法。其他语言也有各自的编译器和解释器实现,您需要了解正在使用的是哪一种,以便理解如何进行跟踪。
简而言之:如果您的任务是跟踪语言 X,您首先要问的问题是,我们目前使用的是什么东西来运行 X,它是如何工作的?它是编译器、JIT 编译器、解释器,还是其他什么?
本节提供了通过 BPF 跟踪任何语言的一般建议,通过根据语言实现生成机器代码的方式(编译、JIT 编译或解释)对语言实现进行分类。一些实现(例如 JVM)支持多种技术。
12.1.1 Compiled
常见的编译语言包括 C、C++、Golang、Rust、Pascal、Fortran 和 COBOL。
对于编译语言,函数被编译成机器代码并存储在可执行的二进制文件中,通常为 ELF 格式,具有以下特点:
- 对于用户级软件,ELF 二进制文件中包含符号表,用于将地址映射到函数和对象名称。这些地址在执行期间不会移动,因此符号表可以在任何时候读取以获得正确的映射。内核级软件有所不同,因为它在 `/proc/kallsyms` 中有自己的动态符号表,随着模块的加载而增长。
- 函数参数及其返回值存储在寄存器和栈偏移中。它们的位置通常遵循每种处理器类型的标准调用约定;然而,某些编译语言(例如 Golang)使用不同的约定,还有一些(例如 V8 内建函数)根本不使用约定。
- 帧指针寄存器(x86_64 上的 RBP)可以用于显示栈跟踪,如果编译器在函数前言中初始化了它。编译器通常会将其重用于通用寄存器(这是对寄存器有限的处理器的一种性能优化)。其副作用是会破坏基于帧指针的栈跟踪。
编译语言通常容易进行跟踪,对于用户级软件使用 uprobes,对于内核级软件使用 kprobes。本书中有许多相关示例。
在处理编译软件时,检查是否存在符号表(例如使用 `nm(1)`、`objdump(1)` 或 `readelf(1)`)。如果不存在,检查是否有适用于该软件的调试信息包,它可以提供缺失的符号。如果仍然无果,检查编译器和构建软件,了解符号缺失的原因:它们可能被 `strip(1)` 工具剥离。一个解决方法是重新编译软件时不调用 `strip(1)`。
还要检查基于帧指针的栈跟踪是否正常工作。这是当前通过 BPF 遍历用户空间栈的默认方式,如果它不工作,软件可能需要用编译器标志(例如 `gcc -fno-omit-frame-pointer`)重新编译以保留帧指针。如果不可行,可以探索其他栈跟踪技术,如最后分支记录(LBR)、DWARF、用户级 ORC 和 BTF。这些技术的 BPF 工具仍需要进一步的开发,相关讨论见第 2 章。
12.1.2 JIT Compiled
常见的 JIT 编译语言包括 Java、JavaScript、Julia、.Net 和 Smalltalk。
JIT 编译语言会先编译成字节码,然后在运行时将字节码编译成机器代码,通常会利用运行时操作的反馈来指导编译器优化。这些语言具有以下特点(仅讨论用户级):
- 由于函数是在运行时编译的,因此没有预构建的符号表。这些映射通常存储在 JIT 运行时的内存中,用于打印异常堆栈等目的。这些映射也可能会改变,因为运行时可能会重新编译并移动函数。
- 函数参数和返回值可能遵循标准调用约定,也可能不遵循。
- JIT 运行时可能会考虑帧指针寄存器,也可能不会,因此基于帧指针的栈遍历可能会有效,也可能会失败(在这种情况下,你会看到栈跟踪以虚假的地址突然结束)。运行时通常有一种方法可以遍历自己的栈,以便在出现错误时由异常处理程序打印栈跟踪。
跟踪 JIT 编译语言是困难的。由于其符号表是动态的并存储在内存中,所以在二进制文件中没有符号表。一些应用程序提供了 JIT 映射的补充符号文件(例如 `/tmp/perf-PID.map`);然而,由于以下两个原因,这些符号文件不能与 uprobes 一起使用:
1. 编译器可能会在内存中移动插桩的函数而未通知内核。当不再需要插桩时,内核会将指令恢复正常,但现在它正在写入错误的位置,可能会破坏用户空间内存。
2. uprobes 基于 inode,需要文件位置才能工作,而 JIT 函数可能存储在匿名私有映射中。
如果运行时提供了 USDT 探针(User Statically Defined Tracing),则可能可以跟踪编译函数,尽管这种技术通常会带来较高的开销,无论是否启用。一个更高效的方法是用动态 USDT 对选定的点进行插桩。(USDT 和动态 USDT 在第 2 章中介绍。)USDT 探针还提供了一种解决方案,用于将函数参数和返回值作为参数插桩。
如果 BPF 的栈跟踪已经有效,可以使用补充符号文件将其转换为函数名称。对于不支持 USDT 的运行时,这提供了一种可见化正在运行的 JIT 函数的路径:可以在系统调用、内核事件和定时剖析中收集栈跟踪,揭示正在运行的 JIT 函数。这可能是获取 JIT 函数可见性的最简单方法,有助于解决许多问题。
如果栈跟踪无法工作,请检查运行时是否支持带选项的帧指针,或是否可以使用 LBR(Last Branch Record)。如果这些方法都不可行,还有其他几种修复栈跟踪的方法,尽管这些方法可能需要大量工程工作。一个方法是修改运行时编译器以保留帧指针。另一个方法是添加 USDT 探针,使用语言自身的方式获取调用栈,并将其作为字符串参数传递。还有一种方法是通过 BPF 向进程发送信号,让用户空间的辅助程序将栈跟踪写入 BPF 可以读取的内存中,就像 Facebook 为 hhvm 实现的那样。
本章稍后将以 Java 为例,讨论这些技术在实践中的工作方式。
12.1.3 Interpreted
常见的解释型语言包括 Bash shell、Perl、Python 和 Ruby。此外,还有一些语言在 JIT 编译之前常常会经历解释阶段,例如 Java 和 JavaScript。在这些分阶段语言的解释阶段进行分析,与仅使用解释的语言分析类似。
解释型语言的运行时不会将程序函数编译成机器代码,而是使用其自身内置的例程解析和执行程序。它们具有以下特征:
- 二进制符号表显示了解释器的内部结构,但没有用户提供程序中的函数。函数很可能存储在特定于解释器实现的内存表中,并映射到解释器对象。
- 函数参数和返回值由解释器处理。它们可能通过解释器函数调用传递,并可能被打包为解释器对象,而不是简单的整数和字符串。
- 如果解释器本身被编译以支持帧指针,那么帧指针栈遍历将有效,但只会显示解释器的内部结构,而没有运行的用户提供程序中的函数名称上下文。程序栈很可能为解释器所知,并为异常栈打印,但存储在自定义数据结构中。
USDT 探针可能存在,用于显示函数调用的开始和结束,以及函数名称和参数作为 USDT 探针的参数。例如,Ruby 运行时在解释器中内置了 USDT 探针。这提供了一种跟踪函数调用的方法,但可能会带来高开销:通常意味着需要对所有函数调用进行插桩,然后根据函数名称进行过滤。如果语言运行时有动态 USDT 库,可以用来仅在感兴趣的函数中插入自定义的 USDT 探针,而不是跟踪所有函数然后过滤。(有关动态 USDT 的介绍,请参见第 2 章。)例如,ruby-static-tracing 包为 Ruby 提供了这种功能。
如果运行时没有内置的 USDT 探针,并且没有提供运行时 USDT 支持的包(如 libstapsdt/libusdt),其解释器函数可以通过 uprobes 进行跟踪,并可以获取函数名称和参数等详细信息。这些可能以解释器对象的形式存储,并需要一些结构导航来解析。
从解释器的内存中提取栈跟踪可能非常困难。一种方法(尽管开销很高)是跟踪 BPF 中的所有函数调用和返回,并在 BPF 内存中构建每个线程的合成栈,以便在需要时读取。与 JIT 编译语言一样,可能还有其他方法可以添加栈跟踪支持,包括通过自定义 USDT 探针、运行时自身的获取栈的方法(如 Ruby 的 “caller” 内置方法或异常方法),或通过 BPF 信号发送到用户空间辅助程序。
12.1.4 BPF Capabilities
使用BPF(Berkeley Packet Filter)对语言进行跟踪的目标能力是回答以下问题:
- 调用了哪些函数?
- 函数的参数是什么?
- 函数的返回值是什么?是否出现错误?
- 导致某个事件的代码路径(堆栈跟踪)是什么?
- 函数的执行时长是多少?以直方图形式展示?
能回答这些问题的数量取决于语言的实现。许多语言实现自带的调试工具可以轻松回答前四个问题,因此你可能会想知道为什么我们还需要BPF。主要原因是能够在一个工具中跟踪软件栈的多个层次。与仅使用内核上下文来检查磁盘I/O或页面错误不同,你可以将这些事件与负责的用户级代码路径一并跟踪,并结合应用程序上下文:即哪些用户请求导致了多少磁盘I/O或页面错误等等。在许多情况下,内核事件可以识别并量化问题,但用户级代码则显示如何解决问题。
对于一些语言(例如Java),显示哪个堆栈跟踪导致了某个事件比跟踪其函数/方法调用更容易实现。结合BPF可以插装的众多其他内核事件,堆栈跟踪可以完成很多工作。你可以看到哪些应用程序代码路径导致了磁盘I/O、页面错误和其他资源使用;你可以看到哪些代码路径导致了线程阻塞并离开CPU;还可以使用定时采样来分析CPU使用情况并生成CPU火焰图。
12.1.5 Strategy
以下是分析语言的建议总体策略:
1. **确定语言的执行方式**:了解运行该语言的软件是使用编译为二进制文件、即时编译(JIT)还是解释执行,或是这些方法的混合。这将决定你在本章讨论的方法。
2. **浏览本章的工具和单行命令**:理解每种语言类型可能实现的功能。
3. **在互联网上搜索**“[e]BPF语言”、“BCC语言”和“bpftrace语言”,查看是否已有用于使用BPF分析该语言的工具和方法。
4. **检查语言软件是否有USDT探针**,以及这些探针是否在分发的二进制文件中启用(或者你是否需要重新编译以启用它们)。这些探针提供了稳定的接口,优先使用。如果语言软件没有USDT探针,可以考虑添加它们。大多数语言软件是开源的。
5. **编写一个示例程序进行插装**:调用一个已知名称的函数,调用次数和延迟(显式的睡眠)都是已知的。这样可以检查你的分析工具是否正常工作,确保它们正确识别所有这些已知的条件。
6. **对于用户级软件,使用uprobes检查语言在本地级别的执行**;对于内核级软件,使用kprobes。
接下来的章节将详细讨论三个示例语言:用于编译型语言的C,用于即时编译语言的Java,以及用于解释型语言的bash shell。
12.1.6 BPF Tools
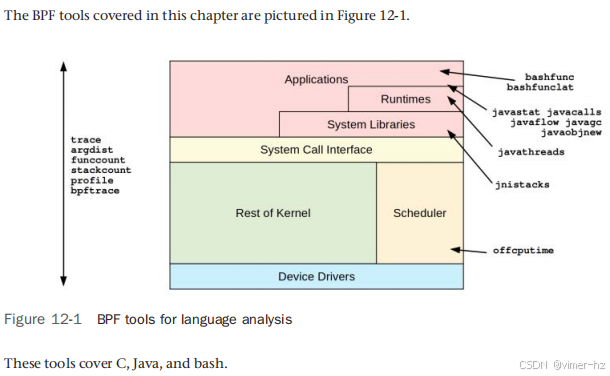
12.2 C
C语言是最容易进行跟踪的语言。
对于内核级的C,内核有自己的符号表,并且大多数发行版会在其内核构建中保留帧指针(CONFIG_FRAME_POINTER=y)。这使得使用kprobes跟踪内核函数变得简单:可以看到并跟踪函数,参数遵循处理器ABI,并且可以获取堆栈跟踪。至少,大多数函数都可以被看到和跟踪:例外包括内联函数,以及那些被内核标记为不安全的跟踪黑名单上的函数。
对于用户级的C,如果编译后的二进制文件没有剥离符号表,并且没有省略帧指针,那么使用uprobes进行跟踪也是简单的:可以看到并跟踪函数,参数遵循处理器ABI,并且可以获取堆栈跟踪。不幸的是,许多二进制文件会剥离符号表,编译器也会省略帧指针,这意味着你需要重新编译这些文件或找到其他方式来读取符号和堆栈。
USDT探针可以在C程序中用于静态插装。一些C库,包括libc,默认提供USDT探针。
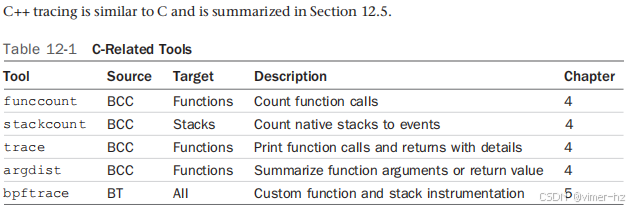
本节讨论了C函数符号、C堆栈跟踪、C函数跟踪、C函数偏移量跟踪、C USDT以及C语言单行命令。表12-1列出了已在其他章节中介绍的用于插装自定义C代码的工具。
12.2.1 C Function Symbols
函数符号可以从ELF符号表中读取。可以使用`readelf(1)`来检查这些符号是否存在。例如,以下是一个微基准程序中的符号:
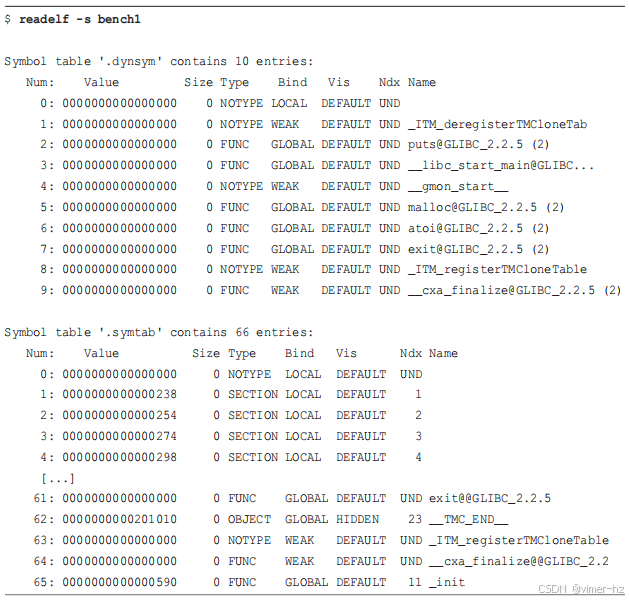
符号表“.symtab”有数十个条目(此处已截断)。还有一个用于动态链接的附加符号表“.dynsym”,其中包含六个函数符号。现在考虑在二进制文件经过`strip(1)`处理后的符号表,这在许多打包的二进制文件中很常见:
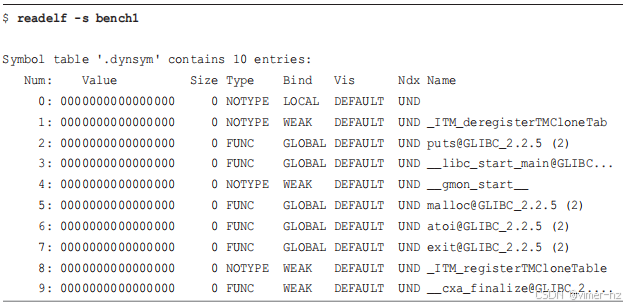
`strip(1)` 移除了 `.symtab` 符号表,但保留了 `.dynsym` 表。`.dynsym` 包含被调用的外部全局符号,而 `.symtab` 包含相同的符号以及应用程序的本地符号。没有 `.symtab`,虽然二进制文件中仍有一些库调用符号,但可能缺少最有趣的符号。静态编译并去除符号的应用程序可能会丢失所有符号,因为它们全部放在被删除的 `.symtab` 中。
有至少两种解决方法:
- 从软件构建过程中移除 `strip(1)` 并重新编译软件。
- 使用其他符号来源:DWARF 调试信息或 BTF。
调试信息有时作为软件包提供,扩展名为 -dbg、-dbgsym 或 -debuginfo。`perf(1)` 命令、BCC 和 bpftrace 都支持这些调试信息。
调试信息
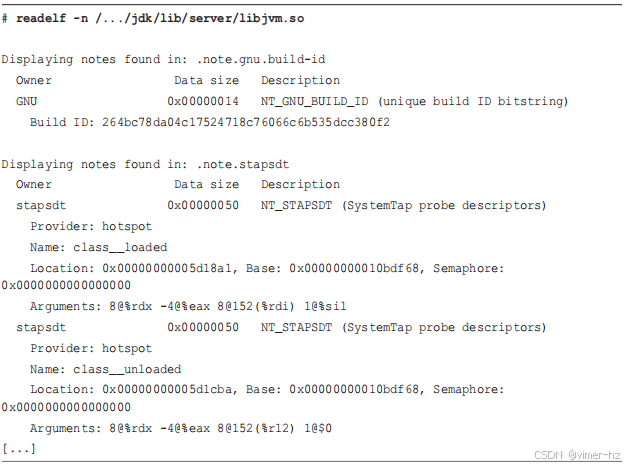
调试信息文件的名称可能与二进制文件相同,扩展名为“.debuginfo”,或者使用唯一的构建 ID 校验和作为文件名,并存放在 `/usr/lib/debug/.build-id` 或该路径的用户版本下。对于后一种情况,构建 ID 存储在二进制 ELF 的注释部分中,可以通过 `readelf -n` 查看。
例如,本系统安装了 `openjdk-11-jre` 和 `openjdk-11-dbg` 包,分别提供了 `libjvm.so` 和 `libjvm.debuginfo` 文件。以下是它们的符号计数:

轻量级调试信息
虽然总是安装调试信息文件可能看起来很有必要,但这会带来文件大小的开销:调试信息文件为 222 兆字节,而 `libjvm.so` 为 17 兆字节。这个大小的大部分不是符号信息,而是其他调试信息部分。可以使用 `readelf(1)` 来检查符号信息的大小:
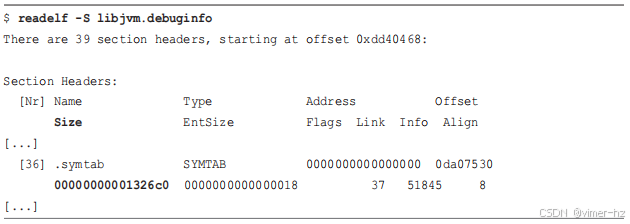
这显示 `.symtab` 的大小仅为 1.2 兆字节。相比之下,提供 `libjvm.so` 的 openjdk 包为 175 兆字节。
如果完整的调试信息大小成为问题,可以考虑精简调试信息文件。以下命令使用 `objcopy(1)` 删除其他调试信息部分(以“.debug_”开头),以创建一个轻量级的调试信息文件。这个文件可以作为包含符号的调试信息替代品,或者也可以使用 `eu-unstrip(1)` 重新附加到二进制文件中。示例命令:
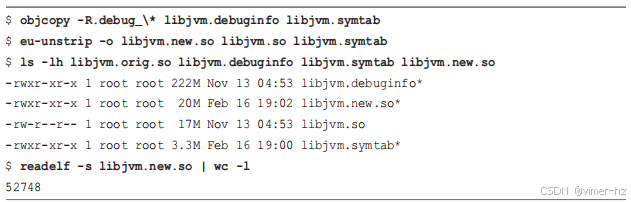
新的 `libjvm.new.so` 只有 20 兆字节,并且包含所有符号。请注意,这是我为本书开发的概念验证技术,尚未经过生产环境测试。
BTF
未来,BPF 类型格式(BTF)可能提供另一种轻量级的调试信息源,而且它是为 BPF 使用而设计的。目前 BTF 仅在内核中使用:尚未开始开发用户级版本。有关 BTF 的更多信息,请参见第 2 章。
使用 bpftrace
除了使用 `readelf(1)`,`bpftrace` 也可以通过匹配哪些 uprobe 可用于插装来列出二进制文件中的符号:

12.2.2 C Stack Traces
BPF 目前支持基于帧指针的栈遍历。为了使这一功能正常工作,软件必须编译为使用帧指针寄存器。对于 GCC 编译器,可以使用 `-fno-omit-frame-pointer` 选项。未来,BPF 可能还会支持其他类型的栈遍历。
由于 BPF 是可编程的,我能够在真正的支持添加之前使用纯 BPF 编写了一个帧指针栈遍历器 [134]。Alexei Starovoitov 添加了官方支持,引入了一种新的映射类型 BPF_MAP_TYPE_STACK_TRACE 和一个助手函数 `bpf_get_stackid()`。该助手函数返回栈的唯一 ID,而映射则存储栈的内容。这可以最大限度地减少栈追踪的存储,因为重复的栈使用相同的 ID 和存储。
在 `bpftrace` 中,栈信息可以通过内置的 `ustack` 和 `kstack` 获取,分别用于用户级和内核栈。以下是一个跟踪 bash shell 的示例,bash 是一个大型 C 程序,并打印出导致读取文件描述符 0(STDIN)的栈跟踪:

这个栈实际上是损坏的:在 `read()` 函数之后出现了一个看起来不像地址的十六进制数字。(可以使用 `pmap(1)` 检查一个 PID 的地址空间映射,以确定它是否在某个范围内;在这个例子中,它不在。)
现在,使用 `-fno-omit-frame-pointer` 重新编译的 bash shell:
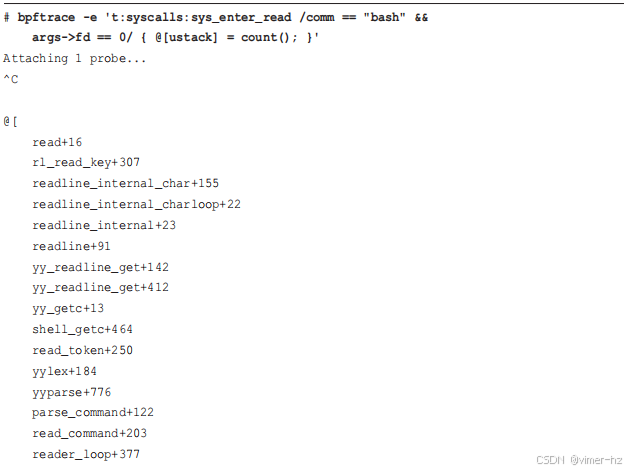

现在,栈跟踪是可见的。它是从叶子到根的自上而下打印的。换句话说,自上而下也就是从子到父到祖父,依此类推。
这个例子显示了 shell 通过 `readline()` 函数从 STDIN 读取数据,处于 `read_command()` 代码路径中。这是 bash shell 正在读取输入。
栈的底部是另一个虚假的地址,位于 `__libc_start_main` 之后。问题是,栈现在进入了系统库 libc,而这个库在编译时没有使用帧指针。
有关 BPF 如何遍历栈以及未来工作的更多信息,请参见第2章第2.4节。
12.2.3 C Function Tracing
可以使用 `kprobes` 和 `kretprobes` 跟踪内核函数,以及 `uprobes` 和 `uretprobes` 跟踪用户级函数。这些技术在第2章中介绍过,第5章则讲解了如何使用 bpftrace 来操作它们。书中有许多它们使用的示例。
作为本节的一个示例:以下代码跟踪了 `readline()` 函数,该函数通常包含在 bash shell 中。由于这是用户级软件,因此可以使用 `uprobes` 进行跟踪。函数签名如下:
char * readline(char *prompt)
它接受一个字符串参数 `prompt`,并返回一个字符串。使用 `uprobe` 来跟踪 `prompt` 参数,该参数可以作为 `arg0` 内置变量访问:

除了主二进制文件之外,共享库也可以通过用库的路径替换探测中的 "/bin/bash" 路径来进行跟踪。一些 Linux 发行版将 `bash` 构建为通过 `libreadline` 调用 `readline`,因此上面的单行命令可能会失败,因为 `readline()` 符号不在 `/bin/bash` 中。它们可以通过 `libreadline` 的路径进行跟踪,例如:

12.2.4 C Function Offset Tracing
有时你可能希望跟踪函数内的任意偏移量,而不仅仅是函数的开始和返回点。除了提供对函数代码流的更大可见性外,通过检查寄存器,你还可以确定局部变量的内容。
`uprobes` 和 `kprobes` 支持在任意偏移量处进行跟踪,BCC 的 Python API 中的 `attach_uprobe()` 和 `attach_kprobe()` 也支持这种功能。然而,这种能力尚未通过 BCC 工具(如 `trace(8)` 和 `funccount(8)`)或 bpftrace 提供。将其添加到这些工具中应该是比较直接的,但难点在于安全地实现这一点。`uprobes` 不检查指令对齐情况,因此跟踪错误的地址(例如,位于多字节指令的中间)可能会破坏目标程序中的指令,从而导致程序以不可预测的方式失败。其他跟踪工具,例如 `perf(1)`,使用调试信息来检查指令对齐。
12.2.5 C USDT
USDT 探针可以添加到 C 程序中以提供静态插装:为跟踪工具提供一个可靠的 API。一些程序和库已经提供了 USDT 探针,例如,可以使用 `bpftrace` 列出 `libc` 的 USDT 探针:
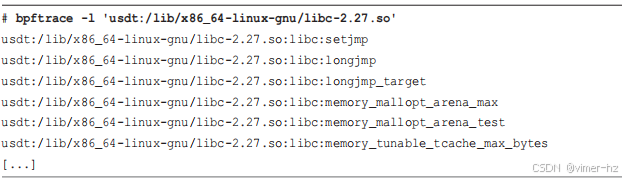
不同的库提供 USDT 插装支持,包括 `systemtap-sdt-dev` 和 Facebook 的 Folly。有关如何将 USDT 探针添加到 C 程序的示例,请参阅第 2 章。
12.2.6 C One-Liners
以下部分展示了 BCC 和 bpftrace 的一行命令。在可能的情况下,展示了使用 BCC 和 bpftrace 实现的相同命令。
**BCC**
- 统计以 "attach" 开头的内核函数调用:
```bash
funccount 'attach*'
```
- 统计从二进制文件(例如 /bin/bash)中以 "a" 开头的函数调用:
```bash
funccount '/bin/bash:a*'
```
- 统计从库文件(例如 libc.so.6)中以 "a" 开头的函数调用:
```bash
funccount '/lib/x86_64-linux-gnu/libc.so.6:a*'
```
- 跟踪一个函数及其参数(例如 bash readline()):
```bash
trace '/bin/bash:readline "%s", arg1'
```
- 跟踪一个函数及其返回值(例如 bash readline()):
```bash
trace 'r:/bin/bash:readline "%s", retval'
```
- 跟踪一个库函数及其参数(例如 libc fopen()):
```bash
trace '/lib/x86_64-linux-gnu/libc.so.6:fopen "%s", arg1'
```
- 统计一个库函数的返回值(例如 libc fopen()):
```bash
argdist -C 'r:/lib/x86_64-linux-gnu/libc.so.6:fopen():int:$retval'
```
- 统计用户级别的函数调用栈(例如 bash readline()):
```bash
stackcount -U '/bin/bash:readline'
```
- 以49赫兹采样用户栈:
```bash
profile -U -F 49
```
**bpftrace**
- 统计以 "attach" 开头的内核函数调用:
```bash
bpftrace -e 'kprobe:attach* { @[probe] = count(); }'
```
- 统计从二进制文件(例如 /bin/bash)中以 "a" 开头的函数调用:
```bash
bpftrace -e 'uprobe:/bin/bash:a* { @[probe] = count(); }'
```
- 统计从库文件(例如 libc.so.6)中以 "a" 开头的函数调用:
```bash
bpftrace -e 'u:/lib/x86_64-linux-gnu/libc.so.6:a* { @[probe] = count(); }'
```
- 跟踪一个函数及其参数(例如 bash readline()):
```bash
bpftrace -e 'u:/bin/bash:readline { printf("prompt: %s\n", str(arg0)); }'
```
- 跟踪一个函数及其返回值(例如 bash readline()):
```bash
bpftrace -e 'ur:/bin/bash:readline { printf("read: %s\n", str(retval)); }'
```
- 跟踪一个库函数及其参数(例如 libc fopen()):
```bash
bpftrace -e 'u:/lib/x86_64-linux-gnu/libc.so.6:fopen { printf("opening: %s\n", str(arg0)); }'
```
- 统计一个库函数的返回值(例如 libc fopen()):
```bash
bpftrace -e 'ur:/lib/x86_64-linux-gnu/libc.so.6:fopen { @[retval] = count(); }'
```
- 统计用户级别的函数调用栈(例如 bash readline()):
```bash
bpftrace -e 'u:/bin/bash:readline { @[ustack] = count(); }'
```
- 以49赫兹采样用户栈:
```bash
bpftrace -e 'profile:hz:49 { @[ustack] = count(); }'
```
12.3 Java
Java 是一个复杂的追踪目标。Java 虚拟机(JVM)通过将 Java 方法编译为字节码并在解释器中运行这些方法来执行它们。当这些方法超过一个执行阈值(-XX:CompileThreshold)时,它们会被即时编译(JIT)为本地指令。JVM 还会对方法执行进行分析,并重新编译方法以进一步提高性能,同时动态更改它们的内存位置。JVM 包含用 C++ 编写的库,用于编译、线程管理和垃圾回收。最常用的 JVM 是 HotSpot,它最初由 Sun Microsystems 开发。
JVM 的 C++ 组件(libjvm)可以像编译语言一样进行插装,这在上一节中已经讨论过。JVM 提供了许多 USDT 探针,以便更容易地追踪 JVM 内部。这些 USDT 探针也可以对 Java 方法进行插装,但它们也带来了本节将要讨论的挑战。
本节首先简要介绍 libjvm C++ 插装,然后讨论 Java 线程名称、Java 方法符号、Java 堆栈跟踪、Java USDT 探针和 Java 一行命令。还会涵盖表 12-2 中列出的与 Java 相关的工具。
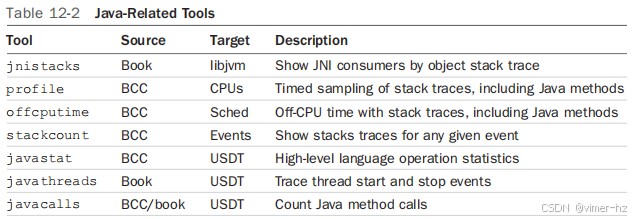

这些工具中的一些显示了 Java 方法,而在 Netflix 生产服务器上展示它们的输出需要对内部代码进行脱敏处理,这使得示例难以跟随。因此,我将用一个开源 Java 游戏来演示这些工具:freecol。这个游戏的软件复杂且对性能敏感,使它成为类似于 Netflix 生产代码的目标。freecol 的官方网站是:http://www.freecol.org。
12.3.1 libjvm Tracing
JVM 主库 libjvm 包含了数千个用于运行 Java 线程、加载类、编译方法、分配内存、垃圾回收等功能的函数。这些函数大多是用 C++ 编写的,可以通过追踪来提供运行中的 Java 程序的不同视图。
作为示例,我将使用 BCC 的 `funccount(8)`(也可以使用 bpftrace)来追踪所有的 Java 本地接口(JNI)函数。
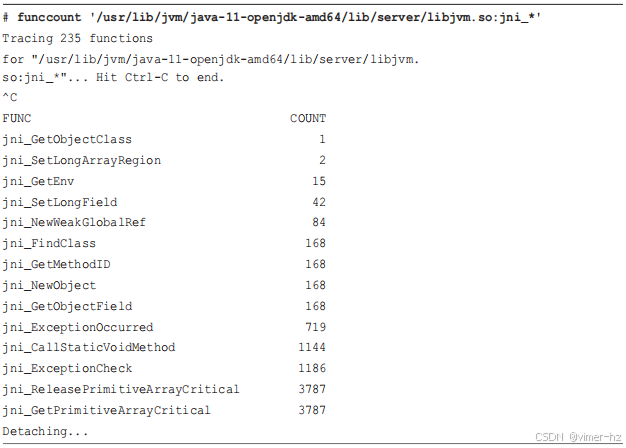
这段代码追踪了 libjvm.so 中所有匹配 "jni_*" 的函数,并发现最频繁的函数是 `jni_GetPrimitiveArrayCritical()`,在追踪过程中调用了 3552 次。为了防止输出换行,libjvm.so 的路径在输出中被截断了。
libjvm 符号
通常与 JDK 一起打包的 libjvm.so 已被剥离,这意味着本地符号表不可用,因此这些 JNI 函数在没有额外步骤的情况下无法被追踪。可以使用 `file(1)` 来检查其状态:

可能的解决方案:
- 从源代码构建自己的 libjvm,并且不要使用 `strip(1)`。
- 安装 JDK 的 debuginfo 包(如果可用),BCC 和 bpftrace 支持该包。
- 安装 JDK 的 debuginfo 包,并使用 `elfutils unstrip(1)` 将符号表添加回 libjvm.so(参见前面的“Debuginfo”部分,第 12.2.1 节)。
- 使用 BTF(如果可用,详见第 2 章)。
在这个示例中,我使用了第二个选项。
12.3.2 jnistacks
作为一个示例 libjvm 工具,`jnistacks(8)` 计算了导致 `jni_NewObject()` 调用的栈信息,以及其他以 "jni_NewObject" 开头的调用。这将揭示哪些 Java 代码路径(包括 Java 方法)导致了新的 JNI 对象的创建。以下是一些示例输出:
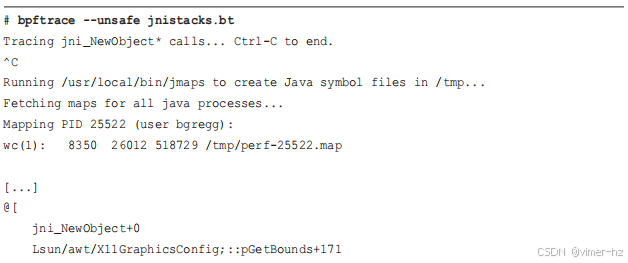

为了简洁起见,这里仅包含了最后一个栈。可以从底部到顶部检查以显示调用路径,或从顶部到底部检查继承关系。这个栈似乎从事件队列(EventQueue)开始,然后经过绘制方法,最后调用 `sun.awt.X11GraphicsConfig::pGetBounds()`,这正在进行 JNI 调用——我猜是因为它需要调用 X11 图形库。
可以看到一些 `Interpreter()` 框架:这是 Java 使用其解释器执行方法的情况,直到它们跨越 `CompileThreshold` 并成为本地编译的方法。
由于 Java 符号是类签名,读取这个栈有些困难。`bpftrace` 目前还不支持解码这些符号。`c++filt(1)` 工具也不支持此版本的 Java 类签名。为了显示这些符号应如何解码,这个符号:
`Ljavax/swing/RepaintManager;::prePaintDirtyRegions+1556`
应为:
`javax.swing.RepaintManager::prePaintDirtyRegions()+1556`
`jnistacks(8)` 的源代码是:

`uprobe` 跟踪所有来自 `libjvm.so` 的以 "jni_NewObject*" 开头的调用,并对用户栈跟踪进行频率统计。
`END` 子句运行一个外部程序 `jmaps`,该程序在 `/tmp` 目录下设置一个补充的 Java 方法符号文件。这使用了 `system()` 函数,该函数需要 `--unsafe` 命令行参数,因为 `system()` 运行的命令无法通过 BPF 安全验证器进行验证。
`jmaps` 的输出已包含在之前的 `bpftrace` 输出中。详细解释见第 12.3.4 节。`jmaps` 可以在外部运行,并不需要包含在这个 `bpftrace` 程序中(你可以删除 `END` 子句);然而,执行 `jmaps` 和使用符号转储之间的时间间隔越长,符号变陈旧和误译的可能性就越大。通过将其包含在 `bpftrace` 的 `END` 子句中,可以在栈信息输出之前立即执行,最小化收集和使用之间的时间间隔。
12.3.3 Java Thread Names
JVM 允许为每个线程指定自定义名称。如果你尝试将 "java" 作为进程名称进行匹配,可能会找不到任何事件,因为线程的名称可能不同。例如,使用 `bpftrace`:
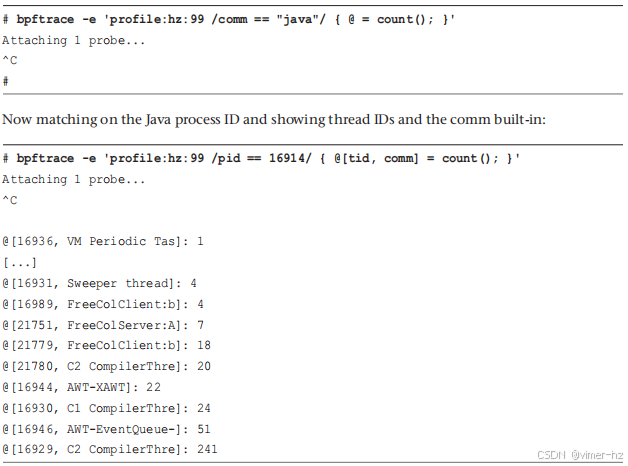
`comm` 内置函数返回的是线程(任务)名称,而不是父进程名称。这的好处在于提供了更多的线程上下文:上述配置文件显示 C2 `ComplierThread`(名称已截断)在采样期间消耗了最多的 CPU。但这也可能造成混淆,因为其他工具包括 `top(1)` 显示的是父进程名称:"java"。
这些线程名称可以在 `/proc/PID/task/TID/comm` 中查看。例如,使用 `grep(1)` 以文件名的方式打印它们:
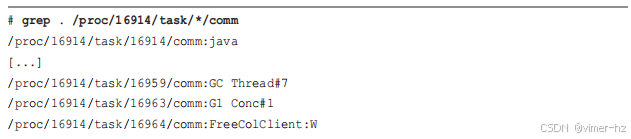
接下来的部分中的示例是根据 Java PID 进行匹配,而不是名称 "java",这就是原因所在。另一个原因是:使用信号量的 USDT 探针需要 PID,以便 `bpftrace` 知道为该 PID 设置信号量。有关这些信号量探针的更多细节,请参见第 2 章第 2.10.1 节。
12.3.4 Java Method Symbols
开源的 `perf-map-agent` 可以用于创建包含已编译 Java 方法地址的补充符号文件 [135]。每当你需要打印包含 Java 方法的栈跟踪或地址时,这是必要的;否则,地址将无法确定。`perf-map-agent` 使用 Linux `perf(1)` 创建的约定,将一个文本文件写入 `/tmp/perf-PID.map`,格式如下 [136]:
```
START SIZE symbolname
```
以下是来自生产环境 Java 应用程序的一些示例符号,其中符号包含 "sun"(仅作为示例):

`perf-map-agent` 可以按需运行,附加到一个活动的 Java 进程并转储符号表。请注意,这个过程在符号转储期间可能会产生一些性能开销,对于大型 Java 应用程序,它可能需要超过一秒钟的 CPU 时间。由于这是符号表的快照,随着 Java 编译器重新编译方法,这些符号很快就会变得过时,尤其是在工作负载看似已达到稳定状态后。符号快照和 BPF 工具翻译方法符号之间的时间间隔越长,符号过时和误翻译的可能性就越大。对于编译率高的繁忙生产工作负载,我不信任超过 60 秒的 Java 符号转储。第 12.3.5 节提供了一个没有 `perf-map-agent` 符号表的栈跟踪示例,然后是在运行 `jmaps` 后有了符号表的示例。
自动化
你可以自动化这些符号转储,以最小化它们创建和被 BPF 工具使用之间的时间间隔。`perf-map-agent` 项目包含了自动化这一步骤的软件,我也发布了自己的程序,称为 `jmaps` [137]。`jmaps` 会找到所有 Java 进程(基于它们的进程名称)并转储它们的符号表。以下是运行 `jmaps` 在一个 48 CPU 的生产服务器上的示例:
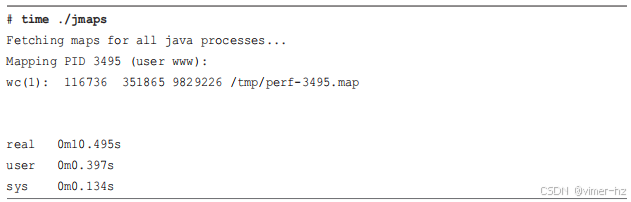
这些输出包括各种统计信息:`jmaps` 对最终的符号转储运行了 `wc(1)`,结果显示它包含 116,000 行(符号)和 9.4 兆字节(9829226 字节)。我还用 `time(1)` 运行了它,以显示所需时间:这是一个繁忙的 Java 应用程序,主内存为 174 Gbytes,运行时间为 10.5 秒。(大部分 CPU 时间被 JVM 使用,用户和系统统计信息中未能反映。)
为了与 BCC 工具一起使用,可以在工具之前立即运行 `jmaps`。例如:
```
./jmaps; trace -U '...'
```
这样会在 `jmaps` 完成后立即调用 `trace(8)` 命令,从而最小化符号变得过时的时间。对于收集堆栈跟踪摘要的工具(例如 `stackcount(8)`),可以修改工具本身以在打印摘要之前立即调用 `jmaps`。
对于 `bpftrace`,可以在使用 `printf()` 的工具中将 `jmaps` 放在 BEGIN 子句中,而在打印地图摘要的工具中放在 END 子句中。之前的 `jnistacks(8)` 工具就是后者的一个例子。
其他技术和未来工作
虽然这些技术减少了符号的频繁变化,`perf-map-agent` 方法在许多环境中表现良好,但其他方法可能更好地解决符号表过时的问题,并可能在未来由 BCC 支持。总结如下:
- **时间戳符号日志记录**:`perf(1)` 支持此功能,相关软件在 Linux 源代码中。目前需要持续记录,这会带来一定的性能开销。理想情况下,它不应要求持续记录,而应在跟踪开始时按需启用,然后在禁用时生成完整的符号表快照。这将允许从时间跟踪 + 快照数据中重建符号状态,而不必承受持续记录的性能开销。
- **使过时符号可见**:应该能够转储前后的符号表,找到发生变化的位置,然后构建一个新符号表,将这些位置标记为不可靠。
- **async-profile**:将 `perf_events` 堆栈跟踪与通过 Java 的 `AsyncGetCallTrace` 接口获取的跟踪结合。这种方法不需要启用帧指针。
- **内核支持**:在 BPF 社区中已讨论过。未来我们可能会增加内核支持,以改进堆栈跟踪收集,并在内核中进行符号转换。这在第 2 章中有提到。
- **JVM 内建符号转储支持**:`perf-map-agent` 是一个单线程模块,受限于 JVMTI 接口。如果 JVM 支持直接写入 `/tmp/perf-PID.map` 补充符号文件——例如,当它接收到信号或其他 JVMTI 调用时——这种内建的 JVM 版本可能会更高效。
这是一个不断发展的领域。
12.3.5 Java Stack Traces
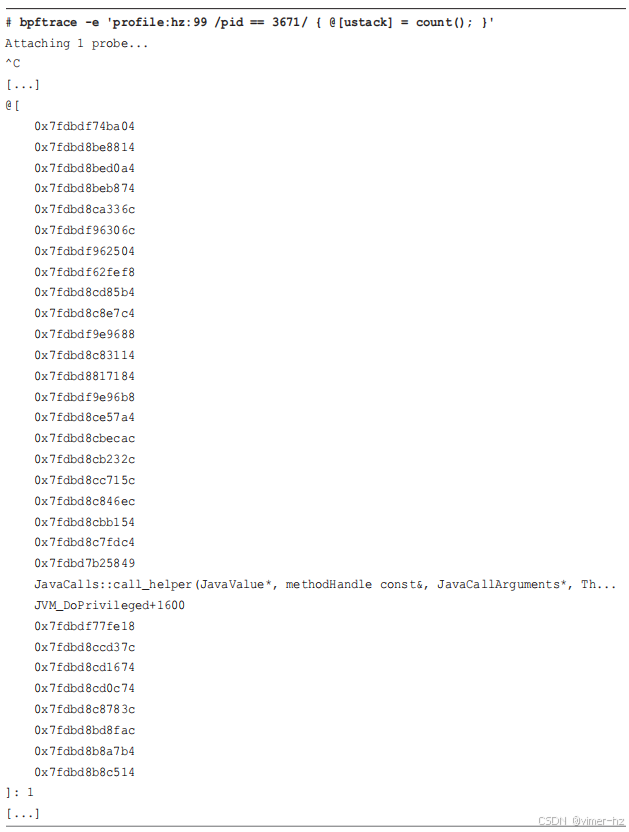
默认情况下,Java 不会使用帧指针寄存器,因此这种堆栈遍历方法不起作用。例如,使用 `bpftrace` 来对 Java 进程进行定时堆栈采样:


这个输出包含了损坏的堆栈,表现为只有一两个十六进制地址。Java 编译器使用了帧指针寄存器来处理局部变量,这是一个编译器优化。这使得 Java 程序在寄存器有限的处理器上稍微更快,但代价是破坏了调试器和跟踪器使用的堆栈遍历方法。尝试遍历堆栈跟踪通常在第一个地址之后失败。上述输出包括了这样的失败情况,同时也包含了一个完全 C++ 的有效堆栈:因为代码路径没有进入任何 Java 方法,所以帧指针保持完整。
**PreserveFramePointer**
自 Java 8 更新 60 以来,JVM 提供了 `-XX:+PreserveFramePointer` 选项来启用帧指针,这修复了基于帧指针的堆栈跟踪。现在,使用相同的 `bpftrace` 一行命令,但需要在运行 Java 时启用此选项(这涉及在启动脚本 `/usr/games/freecol` 的 `run_java` 行中添加 `-XX:+PreserveFramePointer` 选项):
**堆栈和符号**
如第 12.3.4 节所述,可以使用 `perf-map-agent` 软件创建一个补充的符号文件,并通过 `jmaps` 自动化此过程。在 `END` 子句中采取此步骤后:
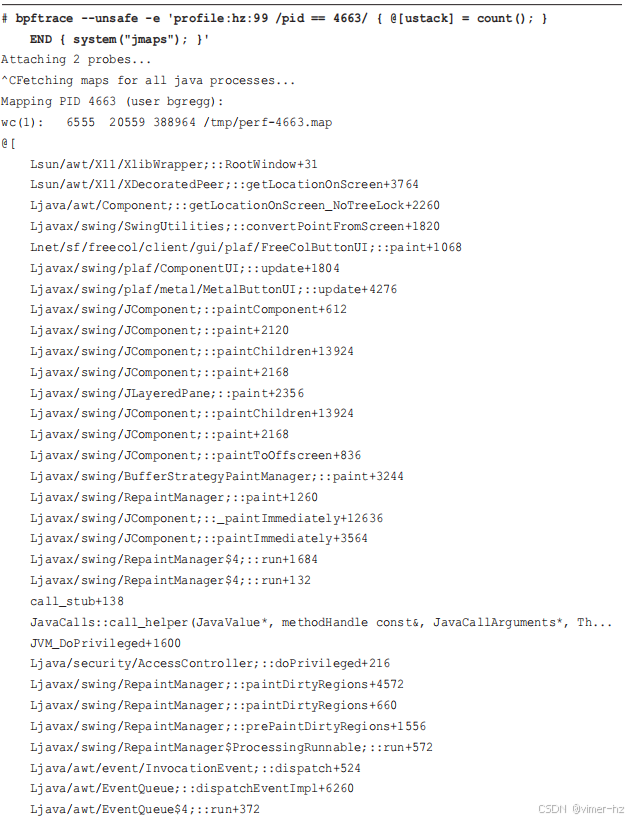
堆栈现已完整,并已完全翻译。这个堆栈看起来是在绘制用户界面中的按钮(`FreeColButtonUI::paint()`)。
**库堆栈**
最后一个示例,这次是跟踪 `read(2)` 系统调用的堆栈跟踪:
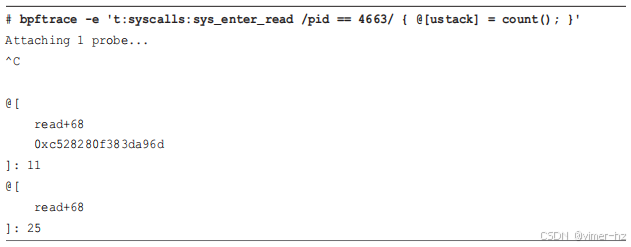
这些堆栈仍然存在问题,即使 Java 正在使用 `-XX:+PreserveFramePointer` 选项运行。问题在于这个系统调用进入了 libc 库的 `read()` 函数,而该库并没有使用帧指针进行编译。解决方法是重新编译该库,或者在 BPF 工具支持时使用不同的堆栈跟踪工具(例如,DWARF 或 LBR)。
修复堆栈跟踪可能需要很多工作,但这是值得的:它使得包括 CPU 火焰图和来自任何事件的堆栈跟踪上下文的性能分析成为可能。
12.3.6 Java USDT Probes
USDT 探针(在第 2 章中介绍)具有提供稳定事件插装接口的优点。JVM 中有多个事件的 USDT 探针,包括:
- 虚拟机生命周期
- 线程生命周期
- 类加载
- 垃圾回收
- 方法编译
- 监视器
- 应用程序跟踪
- 方法调用
- 对象分配
- 监视器事件
这些探针仅在 JDK 使用 `--enable-dtrace` 选项编译时可用,而不幸的是,这一选项在 Linux 发行版的 JDK 中尚未广泛启用。要使用这些 USDT 探针,你需要从源代码编译 JDK 并使用 `--enable-dtrace` 选项,或请求包维护者启用此选项。
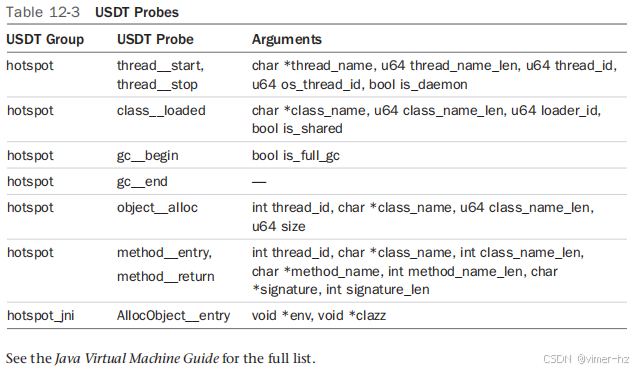
探针的详细信息记录在《Java 虚拟机指南》的“HotSpot VM 中的 DTrace 探针”部分,描述了每个探针的目的及其参数。表 12-3 列出了一些选定的探针。
Java USDT 实现
以下展示了如何将 USDT 探针插入 JDK 的示例代码,以 `hotspot:gc__begin` 探针为例。对于大多数人来说,了解这些细节并不必要;这些细节仅用于提供探针如何工作的洞察。
探针在 `src/hotspot/os/posix/dtrace/hotspot.d` 文件中定义,这是 USDT 探针的定义文件:
```c
provider hotspot {
[...]
probe gc__begin(uintptr_t);
```
从这个定义可以看出,探针将被称为 `hotspot:gc__begin`。在构建时,该文件会被编译成 `hotspot.h` 头文件,其中包含 `HOTSPOT_GC_BEGIN` 宏:
```c
#define HOTSPOT_GC_BEGIN(arg1) \
DTRACE_PROBE1 (hotspot, gc__begin, arg1)
```
这个宏随后被插入到 JVM 代码中需要的位置。它被放置在 `notify_gc_begin()` 函数中,以便在执行探针时可以调用该函数。来自 `src/hotspot/share/gc/shared/gcVMOperations.cpp`:

这个函数恰好具有一个 DTrace 错误的解决方法宏,该宏在 `dtrace.hpp` 头文件中声明,注释为“// 在 Solaris 10 修复 DTrace 尾调用错误 6672627 之前的解决方法”。
如果 JDK 是在没有 `--enable-dtrace` 选项的情况下构建的,则会使用 `dtrace_disabled.hpp` 头文件来代替,该文件对这些宏返回空值。
此外,还使用了一个 `HOTSPOT_GC_BEGIN_ENABLED` 宏来处理此探针:当探针处于跟踪器的实时仪器化下时,该宏返回 `true`。代码使用这个宏来判断是否需要计算昂贵的探针参数,如果探针被启用,则计算这些参数;如果没有人当前使用该探针,则可以跳过这些参数的计算。
**列出 Java USDT 探针**
BCC 的 `tplist(8)` 工具可以用于从文件或正在运行的进程中列出 USDT 探针。在 JVM 上,它列出了超过 500 个探针。以下是部分输出,已被截断以展示一些有趣的探针,同时 libjvm.so 的完整路径被省略("..."):
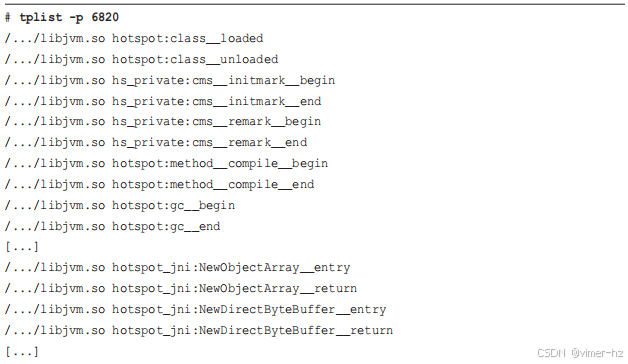
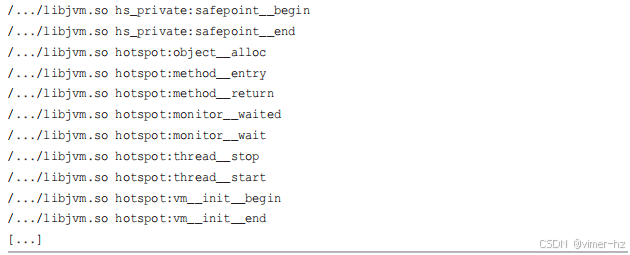
探针被分为 `hotspot` 和 `hotspot_jni` 两个库。这些输出包括了与类加载、垃圾收集、安全点、对象分配、方法、线程等相关的探针。使用双下划线的目的是创建探针名称,使 DTrace 可以通过单个破折号来引用这些探针,避免了在代码中使用减号的问题。
以下是一个示例,该示例运行了 `tplist(8)` 工具在一个进程上;它也可以在 `libjvm.so` 上运行。类似地,`readelf(1)` 也可以用来查看 ELF 二进制文件注释部分中的 USDT 探针(使用 `-n` 选项):
使用 Java USDT 探针
使用 Java USDT 探针可以在 BCC 和 bpftrace 中进行。它们的角色和参数在 Java 虚拟机指南中有详细记录。例如,使用 BCC 的 `trace(8)` 工具对 `gc-begin` 探针进行插桩,首个参数是布尔值,显示这是否是一次完整的垃圾收集(1)还是部分垃圾收集(0)。
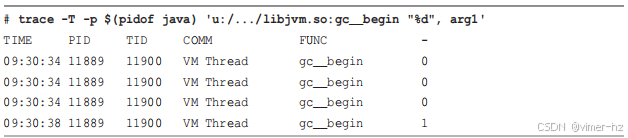
这会显示在 9:30:34 发生的部分 GC 和在 9:30:38 发生的完整 GC。注意,JVM 指南将此参数记为 `args[0]`,但 `trace(8)` 从 1 开始编号,因此它是 `arg1`。
以下是一个带有字符串参数的示例:`method__compile__begin` 探针的第一个、第三个和第五个参数分别是编译器名称、类名称和方法名称。使用 `trace(8)` 可以显示方法名称。
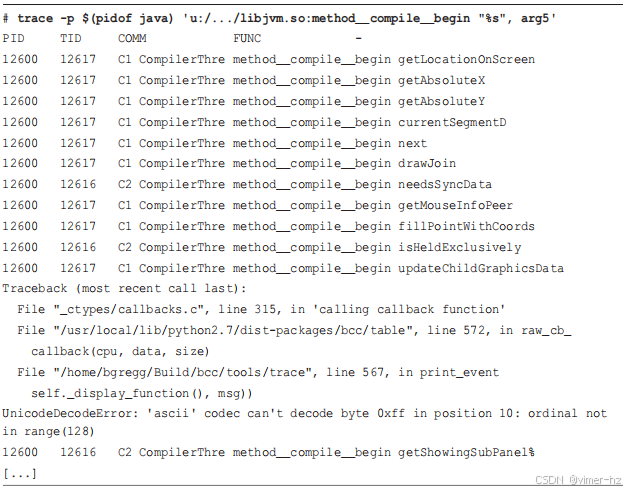
前 11 行显示了方法名称作为最后一列,之后出现了关于解码字节为 ASCII 的 Python 错误。问题在于 Java 虚拟机指南中对这些探针的解释:字符串没有 NULL 终止符,长度作为额外参数提供。为避免此类错误,你的 BPF 程序需要使用探针中的字符串长度。
切换到 bpftrace,可以使用 `str()` 内置函数来处理长度参数。
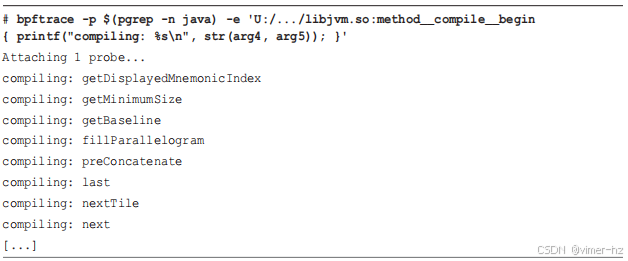
输出中没有更多错误,现在字符串以正确的长度打印。任何使用这些探针的 BCC 或 bpftrace 程序都需要以这种方式使用长度参数。
作为另一个示例,下面的频率统计会计算所有以 "method" 开头的 USDT 探针的调用次数:

在跟踪过程中,`method_compile__begin` 和 `method__compile__end` 探针触发了 2056 次。然而,`method__entry` 和 `method__return` 探针没有被跟踪。原因是它们属于扩展 USDT 探针集,这部分内容将在接下来的章节中讨论。
Extended Java USDT Probes
一些 JVM USDT 探针默认未使用,如方法入口和返回、对象分配及 Java 监控探针。由于这些是高频事件,它们的启用会产生较高的性能开销,可能超过 10%。如果启用这些探针,它们会使 Java 运行速度大幅下降,可能降低至 10 倍或更多。
为了避免用户为未使用的探针支付不必要的性能代价,这些探针默认不可用,除非 Java 以 `-XX:+ExtendedDTraceProbes` 选项运行。下面的示例展示了启用了 ExtendedDTraceProbes 的 Java 游戏 freecol,以及如前所述的以 "method" 开头的 USDT 探针的频率计数。
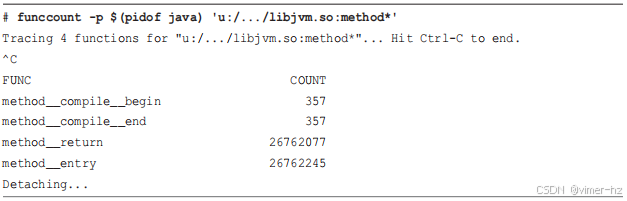
在跟踪过程中,`method__entry` 和 `method__return` 探针被调用了 2600 万次。游戏也遭遇了极端的延迟,任何输入的处理时间约为三秒钟。作为对比,freecol 游戏从启动到显示启动画面的时间默认为 2 秒,而在启用这些方法探针后,时间增加到 22 秒:这是超过 10 倍的减慢。
这些高频探针在实验室环境中用于排查软件问题可能更有用,而在生产环境中分析工作负载时则不太适用。接下来的章节将展示用于 Java 可观察性的不同 BPF 工具,前提是我已经介绍了必要的背景知识:libjvm、Java 符号、Java 堆栈跟踪以及 Java USDT 探针。
12.3.7 profile
在第六章中介绍了 BCC profile(8) 工具。虽然有许多 Java 的分析工具,BCC profile(8) 的优势在于其高效性,能够在内核上下文中频次计数堆栈,并且提供完整的视图,显示用户模式和内核模式的 CPU 消耗者。通过 profile(8),可以查看在本地库(例如 libc)、libjvm、Java 方法以及内核中花费的时间。
**Java 先决条件**
为了让 profile(8) 能够看到完整的堆栈,Java 必须以 `-XX:+PreserveFramePointer` 启动,并且需要使用 perf-map-agent 创建一个补充的符号文件,profile(8) 将使用这个文件(见第 12.3.4 节)。为了翻译 libjvm.so 中的帧,需要符号表。这些要求在之前的章节中已有讨论。
**CPU Flame Graph**
下面是使用 profile(8) 生成混合模式 CPU flame graph 的一个示例。这个 Java 程序 freecol 以 `-XX:+PreserveFramePointer` 启动,并且为其 libjvm 函数提供了 ELF 符号表。在运行 profile(8) 工具之前,先运行了 jmaps 实用程序,以最小化符号的更改。该工具以默认速率(99 赫兹)进行分析,使用内核注释符号名称(-a),以 flame graph 的折叠格式(-f),针对 PID 16914(-p),分析时间为 10 秒:

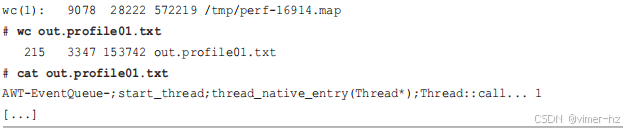
`wc(1)` 工具被 jmaps 用来显示符号文件的大小,该文件有 9078 行,因此包含 9078 个符号。我还使用 `wc(1)` 来显示 profile 文件的大小。profile(8) 工具在折叠模式下的输出每行代表一个堆栈,由分号分隔的帧和堆栈出现次数构成。`wc(1)` 报告了 profile 输出中有 215 行,所以收集到了 215 个独特的堆栈跟踪。
这个 profile 输出可以使用我开源的 FlameGraph 软件 [37] 和以下命令转换为 flame graph:
```
flamegraph.pl --color=java --hash < out.profile01.txt > out.profile02.svg
```
`--color=java` 选项使用不同色调的调色板来区分代码类型:Java 为绿色,C++ 为黄色,用户级本地代码为红色,内核级本地代码为橙色。`--hash` 选项基于函数名使用一致的颜色,而不是随机饱和度水平。
生成的 flame graph SVG 文件可以在网页浏览器中打开。图 12-2 显示了一个截图。

鼠标悬停在每个帧上会显示额外的详细信息,例如该帧在 profile 中的存在百分比。这些数据显示,55% 的 CPU 时间花费在 C2 编译器上,表现为 C++ 帧中间的大型宽塔(垂直矩形列)。只有 29% 的时间花费在 Java 的 freecol 游戏上,这些时间显示为包含 Java 帧的塔。
通过点击左侧的 Java 塔,可以对 Java 帧进行缩放,如图 12-3 所示。
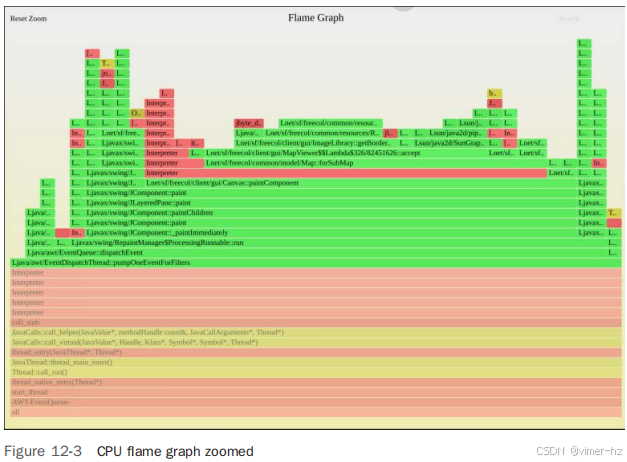
在分析 Java freecol 游戏及其方法的详细信息时,您会发现大部分 CPU 时间集中在 `paint` 方法中。通过查看 flame graph 的顶边,您可以准确地看到 CPU 周期的消耗情况。
如果您有兴趣提高 freecol 的性能,这个 CPU flame graph 已经提供了两个初步的目标:
1. **减少 C2 编译器的 CPU 消耗**:您可以检查 JVM 的调优选项,看看有哪些设置可以使 C2 编译器消耗更少的 CPU 时间。
2. **优化 `paint` 方法**:可以详细检查 `paint` 方法及其实现,利用 freecol 的源代码寻找更高效的技术和改进方法。
对于较长时间的 profile(例如,超过两分钟),在符号表转储和堆栈跟踪收集之间的时间间隔可能很长,这可能导致 C2 编译器在此期间移动了一些方法,从而使符号表不再准确。这可能会表现为一些毫无意义的代码路径,因为某些帧被错误地转换。更常见的问题是内联,这可能导致意外的代码路径。
**内联**
由于这是可视化正在 CPU 上运行的堆栈跟踪,它显示的是内联后的 Java 方法。JVM 的内联可以非常激进,可能将每三帧中的两帧进行内联。这可能会使浏览 flame graph 有些混乱,因为方法似乎直接调用了源代码中并不存在的其他方法。
针对内联的问题,有一个解决方案:`perf-map-agent` 软件支持转储包含所有内联符号的符号表。`jmaps` 可以使用 `-u:` 选项来利用这一功能。

符号的数量大幅增加,从之前看到的 9078 个增加到超过 75,000 个。(我再次运行了 `jmaps`,使用 `-u` 选项,但数量仍然在 9000 左右。)
图 12-4 显示了使用未内联帧信息生成的 flame graph。
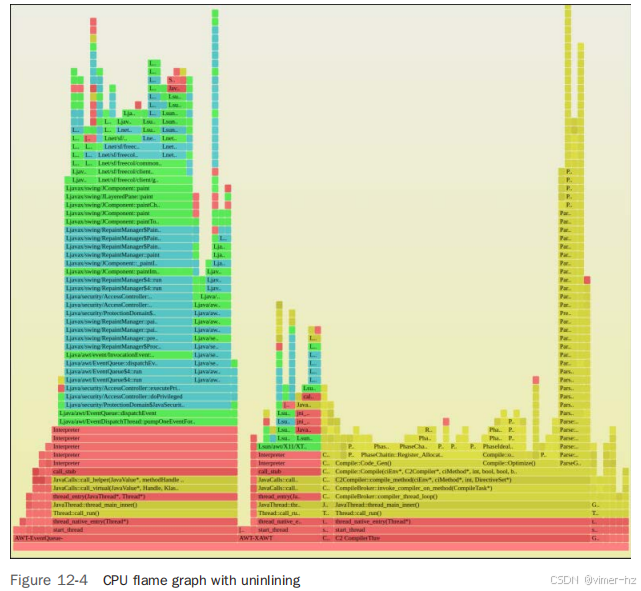
在 FreeCol 堆栈中,塔的高度现在显著增加,因为它包含了未内联的帧(呈青绿色)。包含内联帧会减慢 `jmaps` 步骤,因为它必须转储更多的符号,同时生成 flame graph 时需要解析和包含这些符号。在实际操作中,这有时是必要的。通常,未内联帧的 flame graph 足以解决问题,因为它仍然展示了整体代码流,但要记住某些方法可能不可见。
**bpftrace**
`profile(8)` 功能也可以在 `bpftrace` 中实现,这有一个优势:`jmaps` 工具可以在 `END` 子句中使用 `system()` 函数运行。例如,以下单行命令在之前的部分中展示过:
```bash
bpftrace --unsafe -e 'profile:hz:99 /pid == 4663/ { @[ustack] = count(); } END { system("jmaps"); }'
```
这会以 99 赫兹的频率采样 PID 4663 的用户级堆栈跟踪,跨所有 PID 正在运行的 CPU。通过将映射调整为 `@[kstack, ustack, comm]`,可以包括内核堆栈和进程名称。
12.3.8 offcputime
BCC 的 `offcputime(8)` 工具在第六章中介绍过。它在 CPU 阻塞事件(调度器上下文切换)发生时收集堆栈,并按堆栈跟踪汇总被阻塞的时间。要使 `offcputime(8)` 与 Java 配合使用,请参见第 12.3.7 节。
例如,使用 `offcputime(8)` 监控 Java FreeCol 游戏:
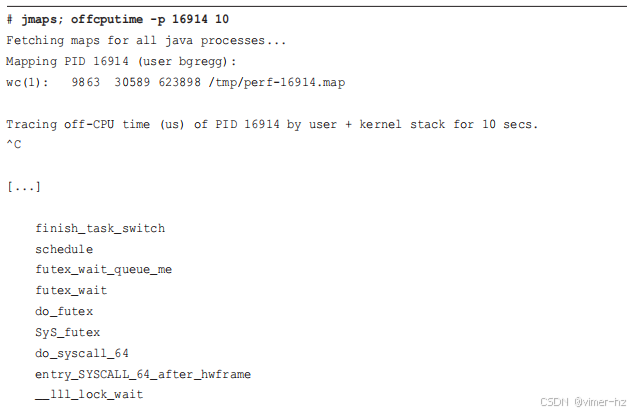
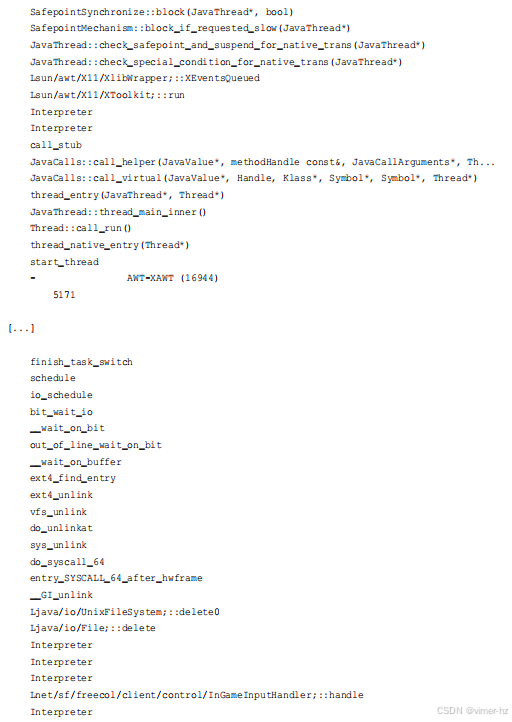
第一个堆栈显示 Java 在一个 safepoint 上总共阻塞了 5.1 毫秒(5717 微秒),这是通过内核中的 futex 锁处理的。这些时间是总计的,因此这 5.1 毫秒可能包含多个阻塞事件。
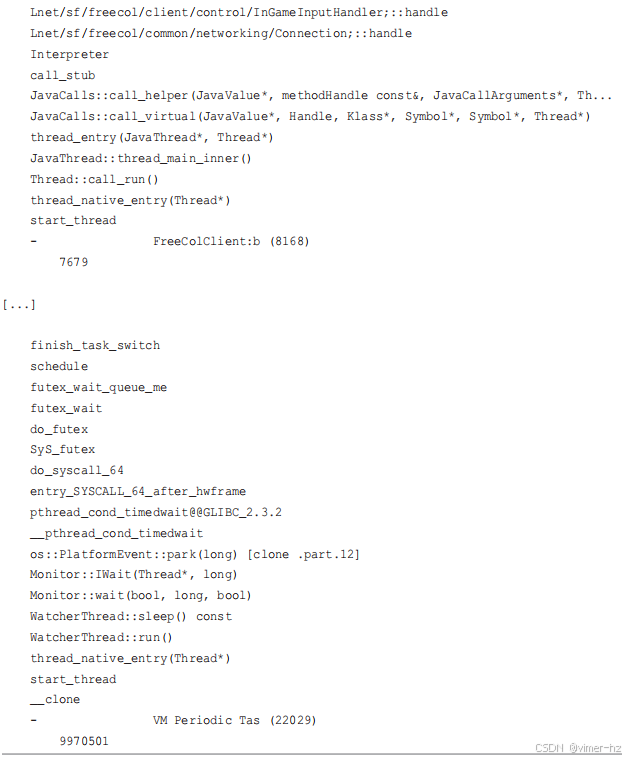
最后一个堆栈显示 Java 在 `pthread_cond_timedwait()` 中阻塞了几乎相同的 10 秒钟的时间:这是一个名为 "VM Periodic Tas"(被截断以去掉 "k")的 WatcherThread 等待工作。对于一些使用大量线程等待工作的应用程序类型,`offcputime(8)` 的输出可能会被这些等待堆栈主导,你需要跳过这些堆栈以找到重要的堆栈:应用程序请求期间的等待事件。
第二个堆栈让我感到惊讶:它显示 Java 在 `unlink(2)` 系统调用上被阻塞,用于删除文件,这最终导致了磁盘 I/O 阻塞(如 `io_schedule()` 等)。FreeCol 在游戏过程中删除了什么文件?一个 `bpftrace` 单行命令显示了删除的文件路径:

FreeCol 正在删除自动保存的游戏。
libpthread 堆栈
由于这可能是一个常见问题,以下是 libpthread 默认安装情况下最终堆栈的样子:

堆栈在 `pthread_cond_timedwait()` 处结束。当前许多 Linux 发行版附带的默认 libpthread 已使用 `-fomit-frame-pointer` 编译,这是一种破坏基于帧指针的堆栈遍历的编译优化。我之前的例子使用了我自己编译的 libpthread 版本,并使用了 `-fno-omit-frame-pointer`。有关更多信息,请参见第 2 章第 2.4 节。
离线 CPU 时间火焰图
`offcputime(8)` 的输出长达数百页。为了更快地浏览,可以使用它来生成离线 CPU 时间火焰图。以下是使用 FlameGraph 软件的一个示例:[37]。


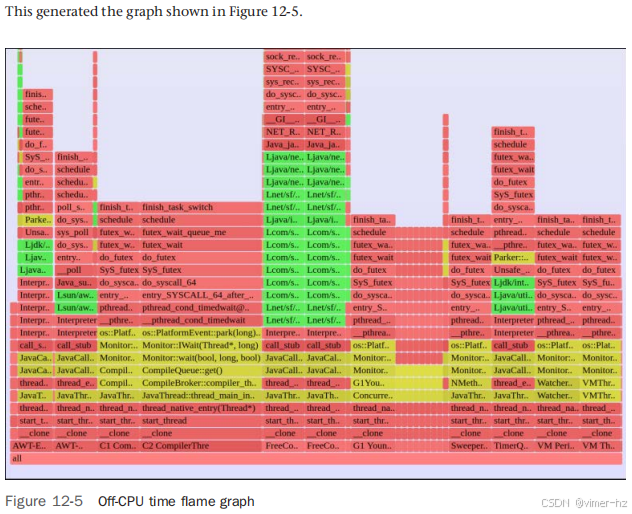
这个火焰图的顶部已经被截断。每个帧的宽度与阻塞的离线 CPU 时间相关。由于 `offcputime(8)` 显示了总阻塞时间的堆栈跟踪,使用 `flamegraph.pl` 的 `--countname=us` 选项来匹配,这会更改鼠标悬停时显示的信息。背景颜色也改为蓝色,以便视觉上提醒这是显示阻塞堆栈的图。(CPU 火焰图使用黄色背景。)
这个火焰图主要显示等待事件的线程。由于线程名称作为堆栈中的第一个帧被包含,它将具有相同名称的线程分组在一起形成塔。这个火焰图中的每个塔显示了等待的线程。
但我对等待事件的线程不感兴趣:我对在应用程序请求期间等待的线程感兴趣。这个应用程序是 FreeCol,使用火焰图搜索功能查找“freecol”将这些帧高亮显示为品红色(见图 12-6)。
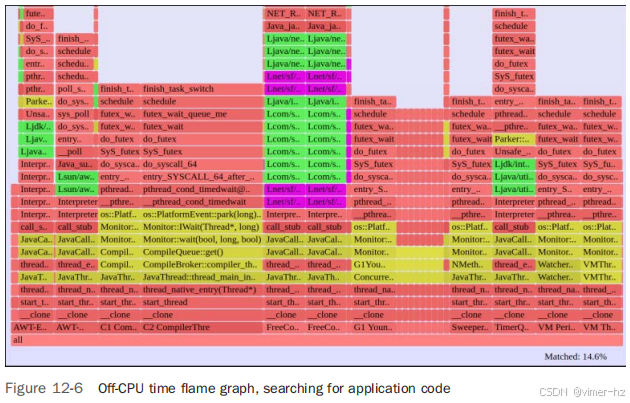
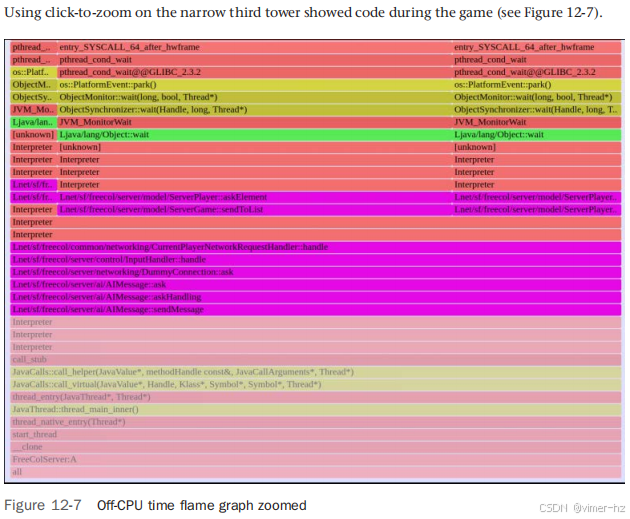
图 12-7 显示了 FreeCol 中的阻塞路径,提供了开始优化的目标。其中许多帧仍显示为“Interpreter”,因为 JVM 还没有执行该方法足够次数以达到 CompileThreshold。
有时,由于其他等待线程,应用程序代码路径可能非常狭窄,以至于在火焰图中被省略。解决这个问题的一种方法是使用 `grep(1)` 命令行工具只包含感兴趣的堆栈。例如,匹配包含应用程序名称 "freecol" 的堆栈:
```
# grep freecol out.offcpu01.txt | flamegraph.pl ... > out.offcpu01.svg
```
这就是折叠文件格式的一个好处:在生成火焰图之前,可以根据需要轻松地进行操作。
12.3.9 stackcount
BCC stackcount(8) 工具(在第 4 章中介绍)可以收集任何事件的堆栈,显示导致事件的 libjvm 和 Java 方法代码路径。有关 stackcount(8) 如何与 Java 一起使用,请参见第 12.3.7 节。
例如,使用 stackcount(8) 显示用户级页面错误,这是主内存增长的一种衡量指标:
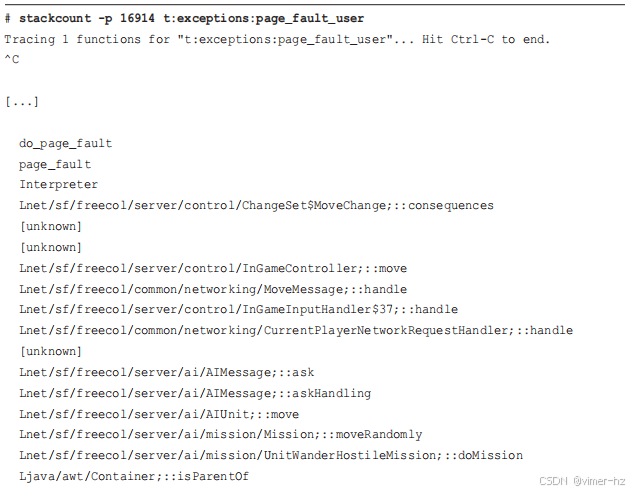
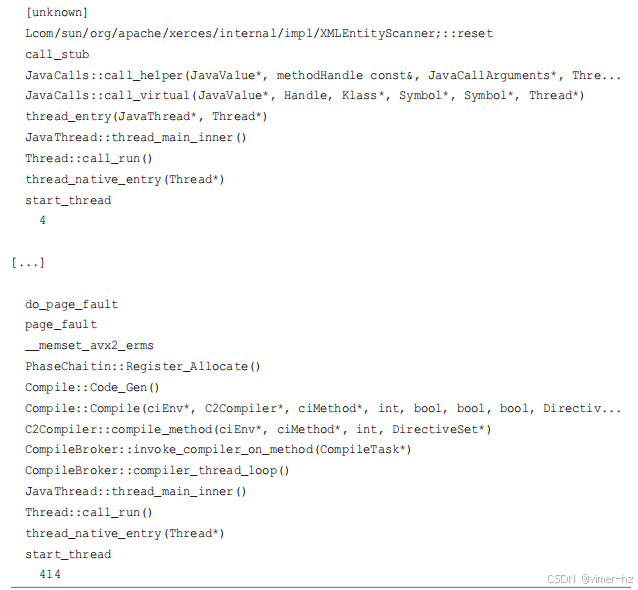
尽管显示了许多堆栈,但这里只包含了两个。第一个显示了通过 FreeCol AI 代码的页面错误;第二个来自 JVM C2 编译器生成的代码。
页面错误火焰图可以从堆栈计数输出生成,以帮助浏览。例如,使用 FlameGraph 软件:[37]。
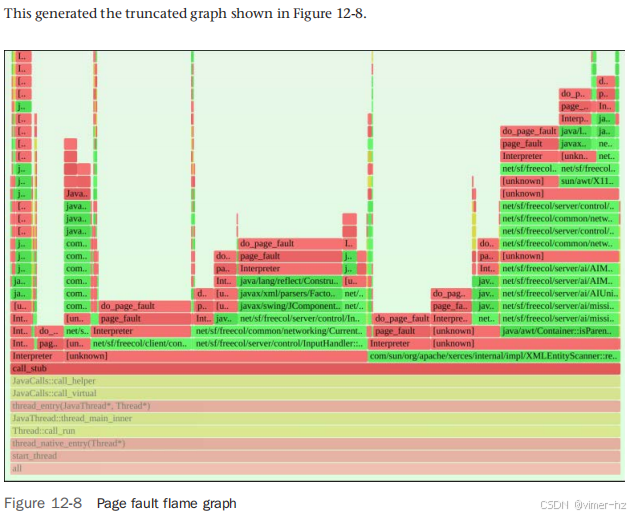
绿色背景色被用作视觉提示,表示这是一个与内存相关的火焰图。在这个截图中,我已缩放以检查 FreeCol 代码路径。这提供了一个应用程序内存增长的视图,每条路径可以通过其宽度进行量化,并从火焰图中进行研究。
bpftrace
stackcount(8) 的功能可以通过 bpftrace 一行命令实现,例如:
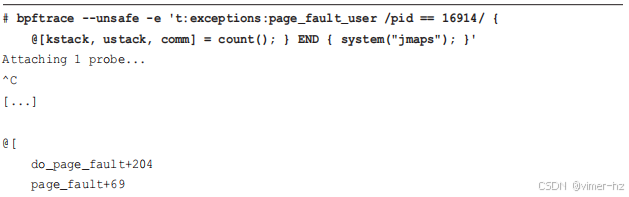
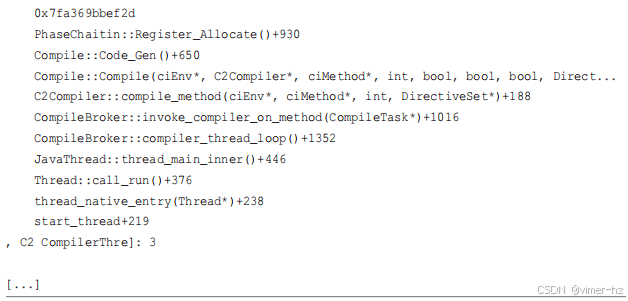
Java 方法符号的 jmaps 执行已经移至 END 子句中,因此它会在堆栈被打印之前立即运行。
12.3.10 javastat
javastat(8) 是一个 BCC 工具,提供高层次的 Java 和 JVM 统计信息。它会像 top(1) 一样刷新屏幕,除非使用了 -C 选项。例如,运行 javastat(8) 来查看 Java FreeCol 游戏的统计信息:

列显示了:
- **PID**:进程 ID。
- **CMDLINE**:进程命令行。这个示例中截断了自定义 JDK 构建的路径。
- **METHOD/s**:每秒方法调用次数。
- **GC/s**:每秒垃圾回收事件次数。
- **OBJNEW/s**:每秒新对象创建次数。
- **CLOAD/s**:每秒类加载次数。
- **EXC/s**:每秒异常次数。
- **THR/s**:每秒创建线程次数。
这通过使用 Java USDT 探针实现。除非使用 -XX:+ExtendedDTraceProbes 选项来激活这些探针,否则 METHOD/s 和 OBJNEW/s 列将为零,但启用这些探针会带来较高的开销。如前所述,启用和仪器化这些探针的应用程序可能会运行得慢 10 倍。
命令行用法:
```
javastat [options] [interval [count]]
```
选项包括:
- **-C**:不清除屏幕
javastat(8) 实际上是 BCC 的工具/lib 目录中的 ustat(8) 工具的一个包装器,处理多种语言。
12.3.11 javathreads


这显示了线程的创建和执行情况,以及一些在跟踪期间短暂存在并结束的线程(“<=”)。
该工具使用了 Java USDT 探针。由于线程创建的速率较低,因此该工具的开销应该可以忽略不计。源代码:
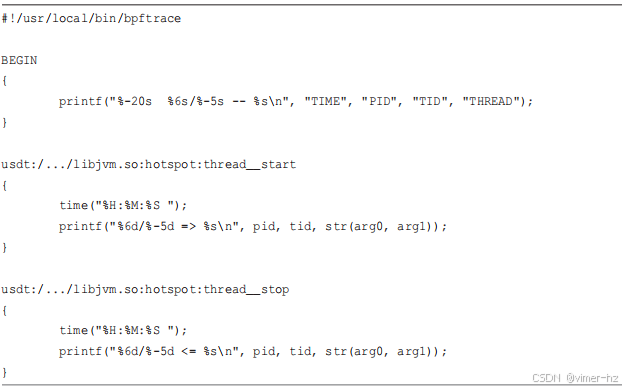
源代码中库的路径已被截断(“...”),但需要用你自己的 libjvm.so 库路径替换。在未来,bpftrace 也应支持指定库名称而无需路径,因此可以简单地写成“libjvm.so”。
12.3.12 javacalls

在跟踪期间,最频繁的方法是 `java/lang/String.code()`,该方法被调用了 1,268,791 次。
这通过使用 Java USDT 探针与 `-XX:+ExtendedDTraceProbes` 实现,这会带来高性能开销。如前所述,启用和仪器化后,应用程序的运行速度可能会变慢 10 倍。
### BCC
**命令行用法:**
```
javacalls [options] pid [interval]
```
**选项包括:**
- **-L**: 显示方法延迟而不是调用次数
- **-m**: 以毫秒为单位报告方法延迟
`javacalls(8)` 实际上是 BCC 工具/lib 目录中的 `ucalls(8)` 工具的一个包装器,用于处理多种语言。
### bpftrace
这是 bpftrace 版本的源代码:

映射的关键是两个字符串:类名和方法名。与 BCC 版本一样,此工具仅在启用 `-XX:+ExtendedDTraceProbes` 的情况下工作,并且预期会有高性能开销。还需要注意,libjvm.so 的完整路径已被截断,需要替换为你自己的 libjvm.so 路径。
12.3.13 javaflow

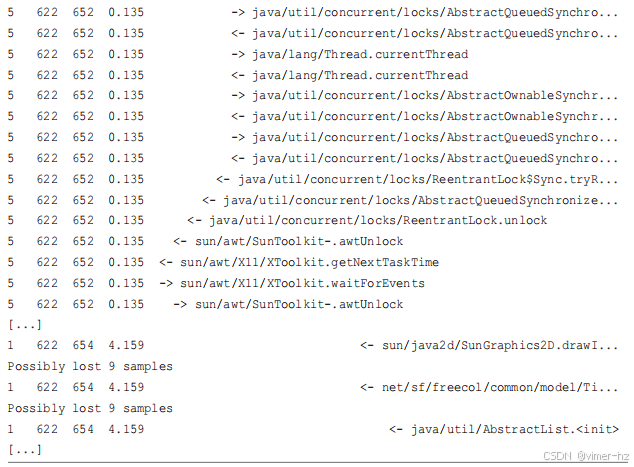
这显示了代码的流程:哪个方法调用了哪个其他方法,依此类推。每个子方法调用会增加 `METHOD` 列的缩进。
这通过使用 Java USDT 探针与 `-XX:+ExtendedDTraceProbes` 实现,具有高性能开销。如前所述,启用和仪器化后,应用程序的运行速度可能会变慢 10 倍。此示例还显示了“可能丢失了 9 个样本”消息:BPF 工具无法跟上事件,作为安全措施,允许丢失事件而不是阻塞应用程序,同时通知用户发生了这种情况。
**命令行用法:**
```
javaflow [options] pid
```
**选项包括:**
- **-M METHOD**: 仅跟踪调用具有此前缀的方法
`javaflow(8)` 实际上是 BCC 工具/lib 目录中的 `uflow(8)` 工具的一个包装器,用于处理多种语言。
12.3.14 javagc

这显示了 GC 事件发生的时间,作为相对于 `javagc(8)` 开始运行时的偏移量(`START` 列,以秒为单位),以及 GC 事件的持续时间(`TIME` 列,以微秒为单位)。
这通过使用标准的 Java USDT 探针实现。
**命令行用法:**
```
javagc [options] pid
```
**选项包括:**
- **-m**: 以毫秒为单位报告时间
`javagc(8)` 实际上是 BCC 工具/lib 目录中的 `ugc(8)` 工具的一个包装器,用于处理多种语言。
12.3.15 javaobjnew
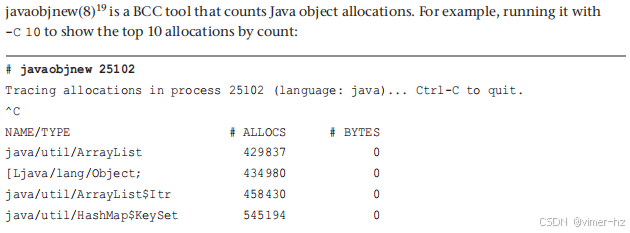
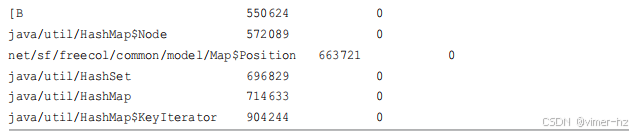
在跟踪过程中,最常见的新对象是 `java/util/HashMap$KeyIterator`,它被创建了 904,244 次。由于该语言类型不支持 `BYTES` 列,因此该列的值为零。
这通过使用 Java USDT 探针与 `-XX:+ExtendedDTraceProbes` 实现,具有高性能开销。如前所述,启用和仪器化后,应用程序的运行速度可能会变慢 10 倍。
**命令行用法:**
```
javaobjnew [options] pid [interval]
```
**选项包括:**
- **-C TOP_COUNT**: 按计数显示此数量的对象
- **-S TOP_SIZE**: 按大小显示此数量的对象
`javaobjnew(8)` 实际上是 BCC 工具/lib 目录中的 `uobjnew(8)` 工具的一个包装器,用于处理多种语言(其中一些语言支持 `BYTES` 列)。
12.3.16 Java One-Liners
这些部分展示了 BCC 和 bpftrace 的一行命令。尽可能地,用 BCC 和 bpftrace 实现相同的命令。
**BCC**
- 统计以 "jni_Call" 开头的 JNI 事件:
```bash
funccount '/.../libjvm.so:jni_Call*'
```
- 统计 Java 方法事件:
```bash
funccount -p $(pidof java) 'u:/.../libjvm.so:method*'
```
- 以 49 赫兹频率分析 Java 堆栈跟踪和线程名称:
```bash
profile -p $(pidof java) -UF 49
```
**bpftrace**
- 统计以 "jni_Call" 开头的 JNI 事件:
```bash
bpftrace -e 'u:/.../libjvm.so:jni_Call* { @[probe] = count(); }'
```
- 统计 Java 方法事件:
```bash
bpftrace -e 'usdt:/.../libjvm.so:method* { @[probe] = count(); }'
```
- 以 49 赫兹频率分析 Java 堆栈跟踪和线程名称:
```bash
bpftrace -e 'profile:hz:49 /execname == "java"/ { @[ustack, comm] = count(); }'
```
- 跟踪方法编译:
```bash
bpftrace -p $(pgrep -n java) -e 'U:/.../libjvm.so:method__compile__begin { printf("compiling: %s\n", str(arg4, arg5)); }'
```
- 跟踪类加载:
```bash
bpftrace -p $(pgrep -n java) -e 'U:/.../libjvm.so:class__loaded { printf("loaded: %s\n", str(arg0, arg1)); }'
```
- 统计对象分配(需要 ExtendedDTraceProbes):
```bash
bpftrace -p $(pgrep -n java) -e 'U:/.../libjvm.so:object__alloc { @[str(arg1, arg2)] = count(); }'
```
12.4 Bash Shell
最后的语言示例是解释型语言:bash shell。解释型语言通常比编译型语言慢得多,因为它们通过运行自己的函数来执行目标程序的每一步。这使得它们不常作为性能分析的目标,因为通常会选择其他语言来处理性能敏感的工作负载。虽然可以进行 BPF 跟踪,但这可能更多是为了排查程序错误,而不是寻找性能改进。
每种解释型语言的跟踪方法不同,这反映了运行它们的软件的内部结构。本节将展示我如何处理未知的解释型语言,并首次确定如何跟踪它们:这是你可以用来跟踪其他语言的方法。
本章早些时候已经跟踪了 bash 的 readline() 函数,但我尚未深入跟踪 bash。在本章中,我将确定如何跟踪 bash 函数和内建调用,并开发一些工具来自动化这一过程。请参见表 12-4。

正如前面提到的,bash 的构建方式会影响符号的位置。以下是 Ubuntu 上的 bash,使用 `ldd(1)` 工具显示其动态库使用情况:
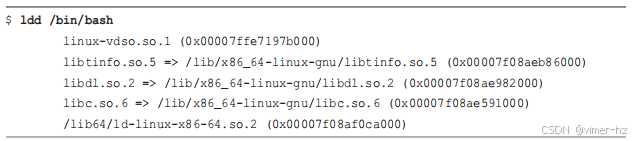
目标是跟踪 `/bin/bash` 和上述列出的共享库。举个例子,这种情况如何导致差异:在许多发行版中,bash 使用的是 `/bin/bash` 中的 `readline()` 函数,但有些发行版则链接到 `libreadline` 并从那里调用它。
**准备工作**
在准备阶段,我通过以下步骤构建了 bash 软件:

这会保留帧指针寄存器,以便我在分析过程中可以使用基于帧指针的栈遍历。此外,它还提供了一个带有本地符号表的 bash 二进制文件,而不是像 `/bin/bash` 那样已经被剥离的版本。
**示例程序**
以下是我为分析编写的示例 bash 程序,`welcome.sh`:
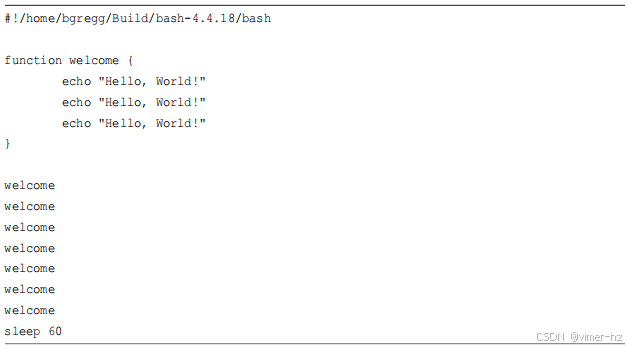
这段话以我构建的 bash 的路径开始。程序调用了七次 `"welcome"` 函数,每次函数调用又调用三次 `echo(1)`(我预计这是一个 bash 内建命令),总共进行了 21 次 `echo(1)` 调用。我选择这些数字是希望它们在跟踪时比其他活动更为突出。
12.4.1 Function Counts

在跟踪时,我运行了 `welcome.sh` 程序,该程序调用了 `welcome` 函数七次。看来我的猜测是正确的:有七次调用了 `restore_funcarray_state()` 和 `execute_function()`,而后者仅从名字来看最有前景。`execute_function()` 这个名字给了我一个想法:还有哪些调用以 `"execute_"` 开头?通过使用 `funccount(8)` 检查:

一些数字更为突出:`execute_builtin()` 被调用了 21 次,与 `echo(1)` 的调用次数相等。如果我想跟踪 `echo(1)` 和其他内建命令,我可以从跟踪 `execute_builtin()` 开始。还有 `execute_command()` 被调用了 23 次,这可能是 `echo(1)` 调用次数加上函数声明加上 `sleep(1)` 调用。这个函数听起来也是一个值得跟踪的函数,以了解 bash。
12.4.2 Function Argument Tracing (bashfunc.bt)
现在跟踪 `execute_function()` 调用。我想知道哪个函数被调用,希望它能显示正在执行 `"welcome"` 函数。希望可以从某个参数中找到这一点。bash 源代码中有(`execute_cmd.c`):

浏览这些源代码表明,`var`,即第一个参数,是正在执行的函数。它的类型是 `SHELL_VAR`,即 `variables.h` 中的 `struct variable`:

`char *` 的跟踪很直接。我们可以使用 bpftrace 查看 `name` 成员。我可以选择包括这个头文件或直接在 bpftrace 中声明这个结构体。我将展示两种方法,从包含头文件开始。这是 `bashfunc.bt21`:
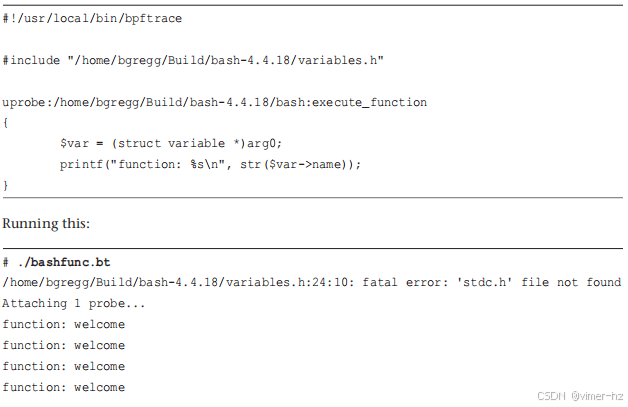

太好了!现在我可以跟踪 bash 函数调用了。它还打印了关于另一个缺失头文件的警告。我将展示第二种方法,即直接声明结构体。实际上,由于我只需要第一个成员,我将只声明那个成员,并称之为“部分”结构体。
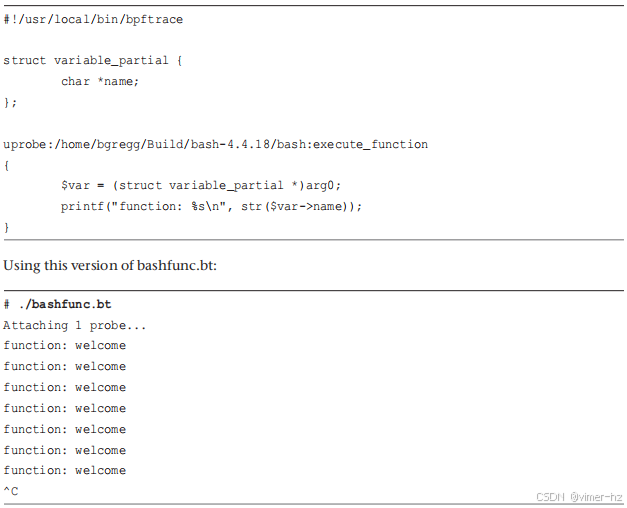
这行得通,没有错误,也不需要 bash 源代码。请注意,`uprobes` 是一个不稳定的接口,因此如果 bash 更改了其函数名称和参数,这个程序可能会停止工作。
12.4.3 Function Latency (bashfunclat.bt)
既然我可以跟踪函数调用了,让我们来看看函数延迟:即函数的持续时间。首先,我修改了 `welcome.sh`,使得函数变成了:

这提供了一个已知的函数调用延迟:0.3 秒。现在,我将使用 BCC 的 `funclatency(8)` 检查 `execute_function()` 是否等待 shell 函数完成,通过测量其延迟来确认。

它的延迟在 256 到 511 毫秒的范围内,这与我们已知的延迟相符。这表明我可以简单地测量 `execute_function()` 的延迟来确定 shell 函数的延迟。
接下来,将其转化为工具,使得 shell 函数的延迟可以按 shell 函数名称以直方图的形式打印出来,`bashfunclat.bt` 文件如下:

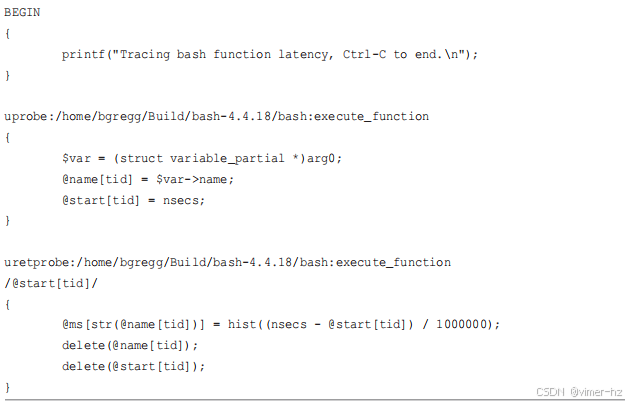
这段代码在 `uprobe` 上保存了一个函数名称的指针和时间戳。在 `uretprobe` 上,它获取函数名称和起始时间戳,以便创建直方图。
输出:

12.4.4 /bin/bash
到目前为止,跟踪 bash 的过程非常简单,这让我开始担心这是否代表了在跟踪解释器时通常遇到的复杂调试冒险。然而,我无需再找其他例子,因为默认的 `/bin/bash` 就足以提供这种冒险。这些早期的工具已对我自己构建的 bash 进行了插桩,该版本包括了本地符号表和帧指针。我对这些工具和 `welcome.sh` 程序进行了修改,以使用 `/bin/bash` 替代,并发现我编写的 BPF 工具不再有效。

`execute_function()` 是一个局部符号,这些局部符号已经从 `/bin/bash` 中剥离,以减小文件大小。
幸运的是,我仍然有线索:`funccount(8)` 的输出显示 `restore_funcarray_state()` 被调用了七次,这与我们已知的工作负载相符。为了检查它是否与函数调用有关,我将使用来自 BCC 的 `stackcount(8)` 来显示其堆栈跟踪。

堆栈信息损坏了:我本想包括这部分内容以展示 `/bin/bash` 默认的堆栈情况。这也是我编译自己版本的 bash 并包含帧指针的原因之一。现在切换到这个版本以调查这个函数:
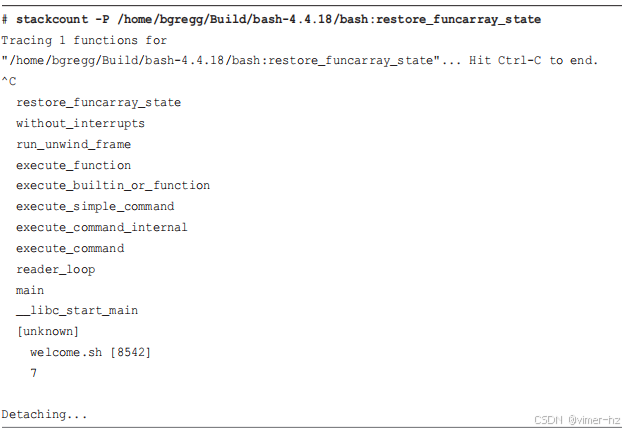
这表明 `restore_funcarray_state()` 是 `execute_function()` 的子函数调用,因此它确实与 shell 函数调用有关。这个函数位于 `execute_cmd.c` 文件中。


这似乎用于在运行函数时创建本地上下文。我猜测 `funcname_a` 或 `funcname_v` 可能包含我所需的函数名,因此我声明了结构体并以类似于我早期的 `bashfunc.bt` 的方式打印字符串以寻找它。但我无法找到函数名。
接下来的步骤有很多,考虑到我使用的是不稳定的接口(uprobes),可能没有绝对正确的方法(正确的方法是 USDT)。以下是一些可能的下一步:
- `funccount(8)` 还显示了一些其他有趣的函数:`find_function()`、`make_funcname_visible()` 和 `find_function_def()`,它们的调用次数超过了我们已知的函数。也许函数名在它们的参数或返回值中,我可以将其缓存以便在 `restore_funcarray_state()` 中查找。
- `stackcount(8)` 显示了更高级别的函数:这些符号是否仍然存在于 `/bin/bash` 中,它们是否提供了另一种跟踪函数的路径?
下面是第二种方法的一个例子,通过检查 `/bin/bash` 中可见的 "execute" 函数来查看。

源代码显示 `execute_command()` 执行了许多操作,包括函数,这些操作可以通过第一个参数中的类型编号来识别。这是一个前进的路径:过滤出仅函数调用,并探索其他参数以找到函数名。
我发现第一种方法立即奏效了:`find_function()` 的参数中包含了函数名,我可以缓存这些名称以便后续查找。以下是更新后的 `bashfunc.bt`:

12.4.5 /bin/bash USDT
为了使跟踪 `bash` 时不受 `bash` 内部变化的影响,可以向代码中添加 USDT 探针。例如,假设 USDT 探针的格式如下:
```
bash:execute__function__entry(char *name, char **args, char *file, int linenum)
bash:execute__function__return(char *name, int retval, char *file, int linenum)
```
这样,打印函数名、显示参数、返回值、延迟、源文件和行号都将变得非常简单。
作为对 shell 进行仪器化的一个例子,USDT 探针被添加到 Solaris 系统的 Bourne shell 中。以下是探针定义的示例:

12.4.6 bash One-Liners
这些部分展示了用于 `bash` shell 分析的 BCC 和 bpftrace 一行命令示例。
**BCC:**
- 计数执行类型(需要符号):
```bash
funccount '/bin/bash:execute_*'
```
- 跟踪交互式命令输入:
```bash
trace 'r:/bin/bash:readline "%s", retval'
```
**bpftrace:**
- 计数执行类型(需要符号):
```bash
bpftrace -e 'uprobe:/bin/bash:execute_* { @[probe] = count(); }'
```
- 跟踪交互式命令输入:
```bash
bpftrace -e 'ur:/bin/bash:readline { printf("read: %s\n", str(retval)); }'
```
12.5 Other Languages
要对其他编程语言和运行时进行仪器化,首先需要确定它们的实现方式:它们是编译成二进制文件的、JIT 编译的、解释执行的,还是这些方式的组合。研究 C(编译型)、Java(JIT 编译型)和 bash shell(解释型)的相关章节,可以帮助你理解方法和面临的挑战。
在本书网站上,我将链接到关于使用 BPF 对其他语言进行仪器化的文章。以下是我之前使用 BPF 跟踪的一些语言的提示:JavaScript(Node.js)、C++ 和 GoLang。
12.5.1 JavaScript (Node.js)
BPF 跟踪类似于 Java。Node.js 当前使用的运行时是 Google 为 Chrome 浏览器开发的 V8 引擎。V8 可以解释执行 Java 函数,也可以将它们 JIT 编译为原生执行。这个运行时还负责内存管理,并有一个垃圾回收例程。以下是关于 Node.js USDT 探针、堆栈遍历、符号和函数跟踪的总结。
**USDT 探针**
Node.js 具有内置的 USDT 探针,并且可以使用 `node-usdt` 库向 JavaScript 代码中添加动态 USDT 探针。目前,Linux 发行版并不默认启用 USDT 探针:要使用它们,必须从源代码重新编译 Node.js,并使用 `--with-dtrace` 选项。以下是示例步骤:
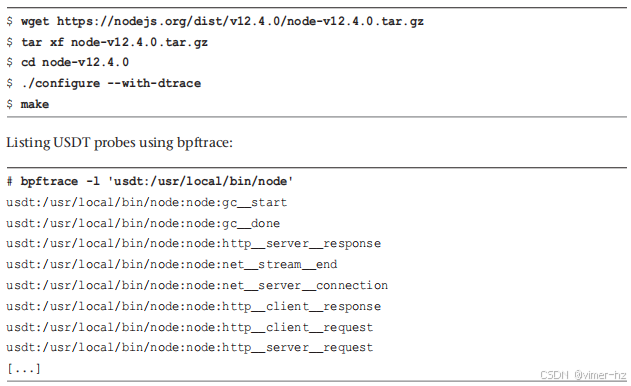
这些展示了用于垃圾回收、HTTP 请求和网络事件的 USDT 探针。有关 Node.js USDT 的更多信息,请参见我的博客文章“Linux bcc/BPF Node.js USDT Tracing”。
**堆栈遍历**
堆栈遍历应正常工作(基于帧指针),尽管将 JIT 编译的 JavaScript 函数转换为符号需要额外的步骤(下面解释)。
**符号**
与 Java 一样,需要在 /tmp 中的补充符号文件来将 JIT 编译的函数地址转换为函数名。如果使用 Node.js v10.x 或更高版本,有两种方法可以创建这些符号文件:
1. 使用 v8 标志 `--perf_basic_prof` 或 `--perf_basic_prof_only_functions`。这些标志会创建持续更新的符号日志,而不是像 Java 那样生成符号状态的快照。由于这些滚动日志在进程运行时无法禁用,随着时间推移,它们可能会导致非常大的映射文件(G字节),其中大部分是过时的符号。
2. 使用 `linux-perf` 模块,它结合了标志的工作方式和 Java 的 `perf-map-agent` 的工作方式:它会捕获堆上的所有函数并写入映射文件,然后在编译新函数时继续写入文件。可以随时开始捕获新函数。推荐使用这种方法。
使用这两种方法时,我需要对补充的符号文件进行后处理,以删除过时的条目。另一个推荐的标志是 `--interpreted-frames-native-stack`(也适用于 Node.js v10.x 及以上版本)。使用此标志时,Linux perf 和 BPF 工具将能够将解释执行的 JavaScript 函数翻译为其实际名称(而不是在堆栈上显示“Interpreter”帧)。
需要外部 Node.js 符号的常见用例是 CPU 性能分析和 CPU 火焰图 [144]。这些可以使用 `perf(1)` 或 BPF 工具生成。
**函数跟踪**
目前没有用于跟踪 JavaScript 函数的 USDT 探针,由于 V8 的架构,添加这些探针将很具挑战性。即使有人添加了探针,正如我与 Java 讨论过的那样,开销可能会很大:在使用过程中使应用程序变慢 10 倍。JavaScript 函数在用户级堆栈跟踪中可见,可以在诸如定时采样、磁盘 I/O、TCP 事件和上下文切换等内核事件上收集。这提供了许多对 Node.js 性能的洞察,包括函数上下文,而没有直接跟踪函数的惩罚。
12.5.2 C++
C++ 的追踪方法与 C 类似,可以使用 uprobes 来追踪函数入口、函数返回,以及基于帧指针的堆栈(前提是编译器保留了帧指针)。不过有几点不同之处:
- 符号名称是 C++ 签名的形式。与 ClassLoader::initialize() 不同,这个符号可能会被追踪为 _ZN11ClassLoader10initializeEv。BCC 和 bpftrace 工具在打印符号时会使用解码功能。
- 函数参数可能不符合处理器 ABI 对对象和 self 对象的支持要求。
函数调用计数、测量函数延迟以及显示堆栈跟踪应该都是直接的。尽可能使用通配符匹配函数名称(例如,uprobe:/path:*ClassLoader*initialize*)可能会有所帮助。
检查参数则需要更多的工作。有时它们只是通过一个偏移量来适应 self 对象作为第一个参数。字符串通常不是原生的 C 字符串,而是 C++ 对象,不能直接解引用。对象需要在 BPF 程序中声明为结构体,以便 BPF 可以解引用其成员。
这所有工作可能会变得更简单,特别是引入了 BTF(在第二章中介绍),它可能提供参数和对象成员的位置。
12.5.3 Golang
Golang 编译为二进制文件,对这些文件进行追踪类似于追踪 C 二进制文件,但在函数调用约定、goroutines 和动态堆栈管理方面存在一些重要差异。由于后者,当前在 Golang 上使用 uretprobes 是不安全的,因为它们可能会导致目标程序崩溃。编译器的不同也会影响这些问题:默认情况下,Go gc 编译器生成的是静态链接的二进制文件,而 gccgo 编译器生成的是动态链接的二进制文件。这些主题将在后续部分讨论。
请注意,还有其他调试和追踪 Go 程序的方法,例如 gdb 的 Go 运行时支持、go 执行跟踪器 [145] 和 GODEBUG 结合 gctrace 和 schedtrace。
**堆栈遍历和符号**
Go gc 和 gccgo 默认都遵循帧指针(Go 从 1.7 版本开始)并在生成的二进制文件中包含符号。这意味着可以始终收集包含 Go 函数的堆栈跟踪,无论是来自用户级还是内核级事件,基于时间采样的性能分析也会立即生效。
**函数入口追踪**
可以使用 uprobes 追踪函数的入口。例如,使用 bpftrace 计数以 "fmt" 开头的函数调用,在名为 "hello" 的 "Hello, World!" Golang 程序中,这个程序是使用 Go gc 编译的:
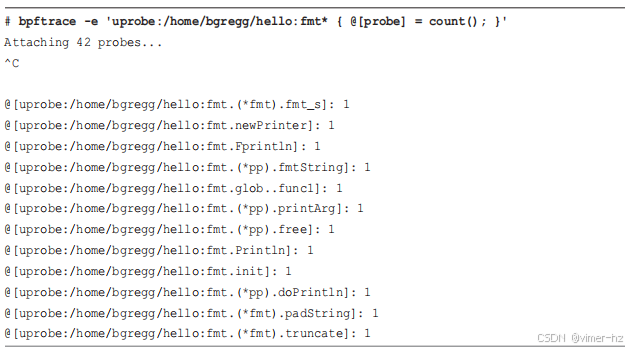
在跟踪过程中,我运行了一次 hello 程序。输出显示了多个 fmt 函数被调用过一次,包括 fmt.Println(),我怀疑它在打印 "Hello, World!"。现在,我要统计 gccgo 二进制文件中的相同函数。在这种情况下,这些函数位于 libgo 库中,因此必须跟踪该位置。
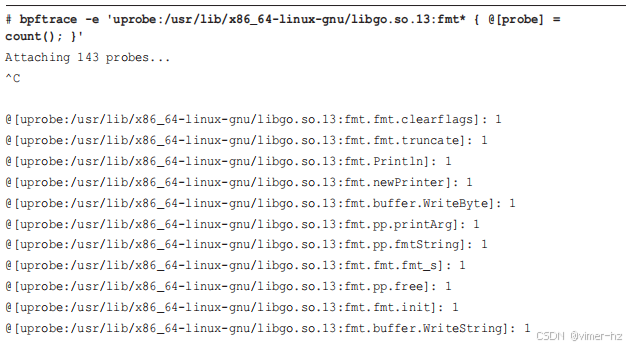

函数的命名约定略有不同。输出中包括 fmt.Println(),如前所见。这些函数也可以使用 BCC 工具 `funccount(8)` 进行计数。针对 Go gc 版本和 gccgo 版本的命令如下:
对于 Go gc 版本:
```bash
funccount 'go:fmt.*'
`
对于 gccgo 版本:
```bash
funccount '/home/bgregg/hello:fmt.*'
```
### 函数入口参数
Go 的 gc 编译器和 gccgo 使用不同的函数调用约定:gccgo 使用标准的 AMD64 ABI,而 Go 的 gc 编译器使用 Plan 9 的栈传递方法。这意味着获取函数参数的方式不同:在 gccgo 中,通常的方法(例如,通过 bpftrace 的 arg0...argN)会有效,但在 Go gc 中则不行:需要使用自定义代码从栈中获取(参见 [146][147])。
例如,考虑 Golang 教程中的 `add(x int, y int)` 函数,它的参数是 42 和 13。要在 gccgo 二进制文件中对其参数进行插桩:

这次需要从栈的偏移量读取参数,通过 `reg("sp")` 访问。未来版本的 bpftrace 可能会支持这些作为别名,例如 `sarg0`、`sarg1`,即“栈参数”的缩写。请注意,我需要使用 `go build -gcflags '-N -l' ...` 编译,以确保 `add()` 函数没有被编译器内联。
### 函数返回
不幸的是,当前实现的 `uretprobe` 跟踪不安全。Go 编译器可以随时修改栈,而内核已经在栈上添加了 `uretprobe` 跳板处理程序。这可能导致内存损坏:一旦 `uretprobe` 被停用,内核会将这些字节恢复正常,但这些字节可能现在包含其他 Golang 程序数据,并且会被内核破坏。这可能导致 Golang 崩溃(如果运气好)或继续运行时数据损坏(如果运气不好)。
Gianluca Borello 研究了一种解决方案,即在函数的返回位置使用 `uprobes` 而不是 `uretprobes`。这涉及到反汇编函数以找到返回点,然后在这些点上放置 `uretprobe`。
另一个问题是 goroutines:它们在运行时可以在不同的操作系统线程之间调度,因此使用基于线程 ID 的时间戳(例如,使用 bpftrace:`@start[tid] = nsecs`)来测量函数延迟的方法不再可靠。
### USDT
Salp 库通过 libstapsdt 提供动态 USDT 探针。这允许在 Go 代码中放置静态探针点。
12.6 Summary
无论你感兴趣的编程语言是编译型、JIT 编译型还是解释型,通常都有方法可以使用 BPF 进行分析。在这一章中,我讨论了这三种类型,并展示了如何跟踪每种类型的示例:C、Java 和 Bash shell。通过跟踪,你可以检查它们的函数或方法调用,查看其参数和返回值,测量函数或方法的延迟,并显示其他事件的栈跟踪。还包括了对 JavaScript、C++ 和 Golang 等其他语言的提示。


















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









