







字符串匹配
“字符串A是否为字符串B的子串?如果是,出现在B的什么位置?”这个问题就是字符串匹配问题。字符串A称为模式串,字符串B称为主串。
那么,如何查找模式串在主串中的位置呢?
暴力匹配
暴力匹配,顾名思义,是一种简单粗暴的匹配方法。从主串的第一个字符开始与模式串的第一个字符比较,如果相同则模式串往后移动一个位置和主串的下一个位置再比较,如果不同,则主串移动到下一个字符,模式串移动到第一个字符,开始重新比较,以此类推。
这种方法很简单,但效率很低,假设主串的长度为m,模式串的长度为n,最差的情况是主串移动m-n+1次才能匹配到,时间复杂度为O(mn),直接上代码:
/**
* 暴力匹配
* @param t 主串
* @param p 模式串
* @return
*/
public static int bruteForce(String t, String p) {
int index = -1;
int pLength = p.length();
int tLength = t.length();
// 模式串的长度当然要小于等于主串长度
if (pLength <= tLength) {
int j = 0;
for (int i = 0; i < pLength; i++) {
// 模式串和主串字符不匹配则主串下标后移一位,模式串重置第一位(下标为0)
if (p.charAt(i) != t.charAt(j + i)) {
j ++;
i = -1;
} else {
// 模式串最后一个字符匹配上,记录下标,退出循环
if (i == pLength - 1) {
index = j;
break;
}
}
// 模式串长度大于主串剩余长度
if (pLength > tLength - j) {
break;
}
}
}
return index;
}
KMP算法
KMP算法由D.E.Knuth,J.H.Morris和V.R.Pratt三位大神在1977年提出,它的核心算法是利用匹配失败后的信息,减少模式串与主串的匹配次数,以达到快速匹配的目的。
最近在网上看了一些讲解KMP算法的文章,基本都思路不够清晰,还有写公式的,看得一头雾水,甚至怀疑自己是不是太笨了,最后只能不看电脑,自己拿着笔在纸上写写划划、仔细推敲,最终才想明白。其实,如果理解了KMP算法的核心思想,那就不会觉得难。下面就跟着我,顺着我的思路,假设是我们自己,应该怎么实现字符串快速匹配。
假设有如下图所示两个字符串,第一个字符A相同,第二个开始不同:
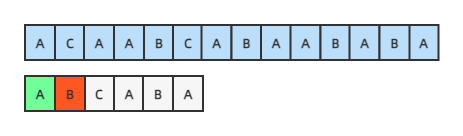
按暴力匹配的方法,此时应该从主串的第二个字符C开始重新匹配,但我们观察发现,主串后面的几个字符里根本就没有模式串的前两个字符AB,直到第四个开始才有AB这两个字符,我们移动模式串,把主串和模式串的两个字符AB对齐,AB这两个字符已经相同,不用比较,我们应该从AB的下一个字符开始对比,这样才比较高效:
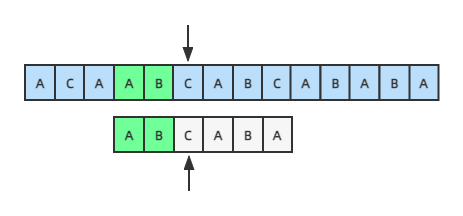
这样就引出了KMP算法的一个核心思路:如果某个位置匹配失败,应该把模式串移动到哪个位置继续匹配才最高效。假设匹配到如下位置,匹配失败:
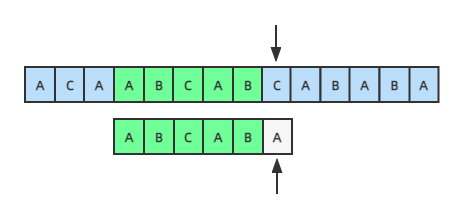
前面已经匹配成功的字符串为ABCAB(绿色的部分),现在应该计算把模式串移动到哪个位置,仔细想想看,我们移动模式串的位置,为了让模式串中的前n个字符和已经匹配完成的这几个字符的后面n个字符对齐,其实就是绿色的这部分自己和自己对比计算。
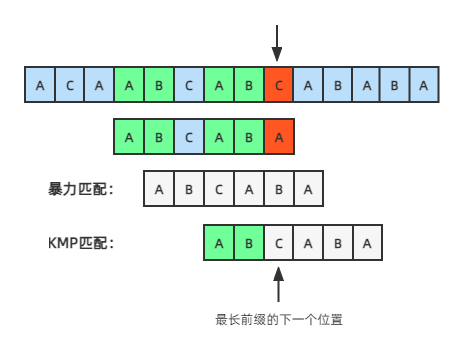
最长前缀
一个字符串的前n个字符和后n个字符,分别是它的前缀和后缀,如果它的前缀和后缀相同,那不就可以对齐了吗?并且我们要找长度最长的那个前后缀才能实现效率最大化,注意:一定是前缀和后缀相同且长度最长且非字符串本身,后面简称为最长前缀。
字符串ABCAB的前缀集合为:{A,AB,ABC,ABCA},后缀集合为:{B,AB,CAB,BCAB}。它的最长前缀为AB,长度为2,往后移动2个位置,让前后缀AB对齐后,我们应该从下一个位置(即下标为2)开始匹配。
KMP的核心思想是:某个位置匹配失败时,移动到这个位置之前的字符串的最长前缀的下一个字符继续匹配。
next数组
接下来的问题就是如何计算这个最长前缀的长度。这部分是比较难懂的部分,网上的文章基本都不讲原理,直接上代码,看得人一头雾水,但代码上机一跑,发现没问题,知其然不知其所以然,更是郁闷。
一个字符串的最长前缀怎么找呢?我们当然可以分别从前往后和从后往前每次累加一个长度截取字符串,列出所有前缀和后缀,然后对比,找出最长前缀,但这个方法不够聪明,如果字符串特别长,那这个计算量也是挺大的,违背了KMP算法的初衷,我们有更好的方法。
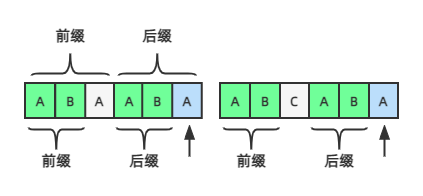
先看上图左边部分,箭头所指蓝色位置之前的字符串的最长前缀是AB,长度是2,我们对比这个最长前缀的下一个字符A和蓝色位置A相同,那么整个字符串的前后缀就变成了ABA,长度为2+1=3,发现规律了吗?仔细想想看:蓝色的A之前是最长后缀,白色的A之前是最长前缀,而这个最长前后缀是相同的,都是AB,那么如果第三个字符也相同,这三个字符连起来不是也相同吗?长度就是2+1=3!
也就是说,如果要计算到某个位置字符串的最长前缀长度,我们只需要将这个字符和它之前字符串的最长前缀的下一个字符对比,如果相同,则它的最长前缀长度就是前面字符串的最长前缀长度+1。
如果不相同呢?看上图右边部分,蓝色的A不等于最长前缀的下一个字符C,我们应该往前回溯,字符C前面的字符串AB的最长前缀长度是0(即后面代码里的k=next[k]),我们就用这个前缀的下一个字符,即第1个字符A和当前字符比较,如果相同,则整个字符串的最长前缀长度为0+1,如果不同,则继续往前回溯,直到第一个字符。也就是,不断往前回溯,用前面字符串的最长前缀的下一个字符和当前字符对比。
到这里,已经知道怎么计算字符串的最长前后缀的长度了,那总不能每次都重新计算吧?!我们需要用一个数组把计算好的值保存起来,这个数组就是next数组。
注意:next数组保存的不是最长前缀的长度,而是对应的下标,也就是长度-1,如果长度是0,则保存-1。
next数组保存的是模式串各个位置的字符匹配失败时应该往前回溯的位置,其值等于到该位置字符串的最长前缀的长度-1,应该从它的下一个位置(即这个值+1)开始匹配。
next数组讲完了,那KMP的算法你也应该明白了,从主串的第一个字符开始和模式串的当前子串的最长前缀下一个字符比较,相同则对比下一个,不同则一直往前回溯。这部分看代码就看明白了。
下面上代码:
public class KMP {
public static void main(String[] args) {
String t = "ACAABCABCABABA";
String p = "ABCABA";
int[] next = getNext(p);
for (int i = 0; i < next.length; i++) {
System.out.print(next[i] + ",");
}
System.out.println();
System.out.println(getKMP(t, p));
}
public static int getKMP(String t, String p) {
int index = -1;
int pLength = p.length();
int tLength = t.length();
// 模式串的长度当然要小于等于主串长度
if (pLength <= tLength) {
int[] next = getNext(p);
int k = -1;
for (int i = 0; i < tLength; i++) {
// 当前字符和最长前缀下一个字符不同,则往前回溯
while (k > -1 && t.charAt(i) != p.charAt(k + 1)) {
// 已经比较了位置k+1的字符不同,往前回溯的话应该往k位置,k位置的最长前缀的位置k=next[k]
k = next[k];
}
// System.out.print(t.charAt(i) + " " + p.charAt(k + 1));
if (t.charAt(i) == p.charAt(k + 1)) {
// 这个k+1,其实就是模式串的下一个字符下标
k = k + 1;
// System.out.print(" " + k + "\n");
if (k == pLength - 1) {
index = i - pLength + 1;
break;
}
}
}
}
return index;
}
public static int[] getNext(String p) {
int[] next = new int[p.length()];
next[0] = -1;
int k = -1;
for (int i = 1; i < p.length(); i++) {
// 当前字符和最长前缀下一个字符不同,则往前回溯
while (k > -1 && p.charAt(i) != p.charAt(k + 1)) {
// 已经比较了位置k+1的字符不同,往前回溯的话应该往k位置,k位置的最长前缀的位置k=next[k]
k = next[k];
}
// 当前字符和当前字符前面字符串的最长前缀的下一个字符相同,则k+1
if (p.charAt(i) == p.charAt(k + 1)) {
k = k + 1;
}
next[i] = k;
}
return next;
}
}
我断断续续琢磨了好几天,终于自己搞懂了,花了一天时间,边码字边整理思路、作图,尽可能详细的把我的思路写下来,如果看完我这篇文章你还是不懂,那就仔细多看几遍,或者像我一样自己在纸上划划,理理思路,要是还不懂,那就放弃吧!
毕竟:世上无难事,只要肯放弃!
















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









