






看图说话怎么玩

1、首先你需要一些有标题的数据集比如coco的image caption。Flickr8k数据集也不错。
2、基础模型框架
可以参考这个作者写的代码(初级):https://github.com/anuragmishracse/caption_generator

该作者使用的数据集vocab_size字典库的大小为8256. 模型的输入X的其中一部分是(224,224,3)的图像经过Vgg16(include top)后得到4096的张量,另外一部分是该图长度为40的caption。模型最后输出一个word(one-hot表示)。
该做法的几个细节:
在训练样本制作的过程中,input_seq 取值为该图像对应caption的任意长度的前k个word(不够40长度的补0)。输出只有一个预测值,即target_seq = word
我个人不太喜欢这样的做法,我的做法如下:
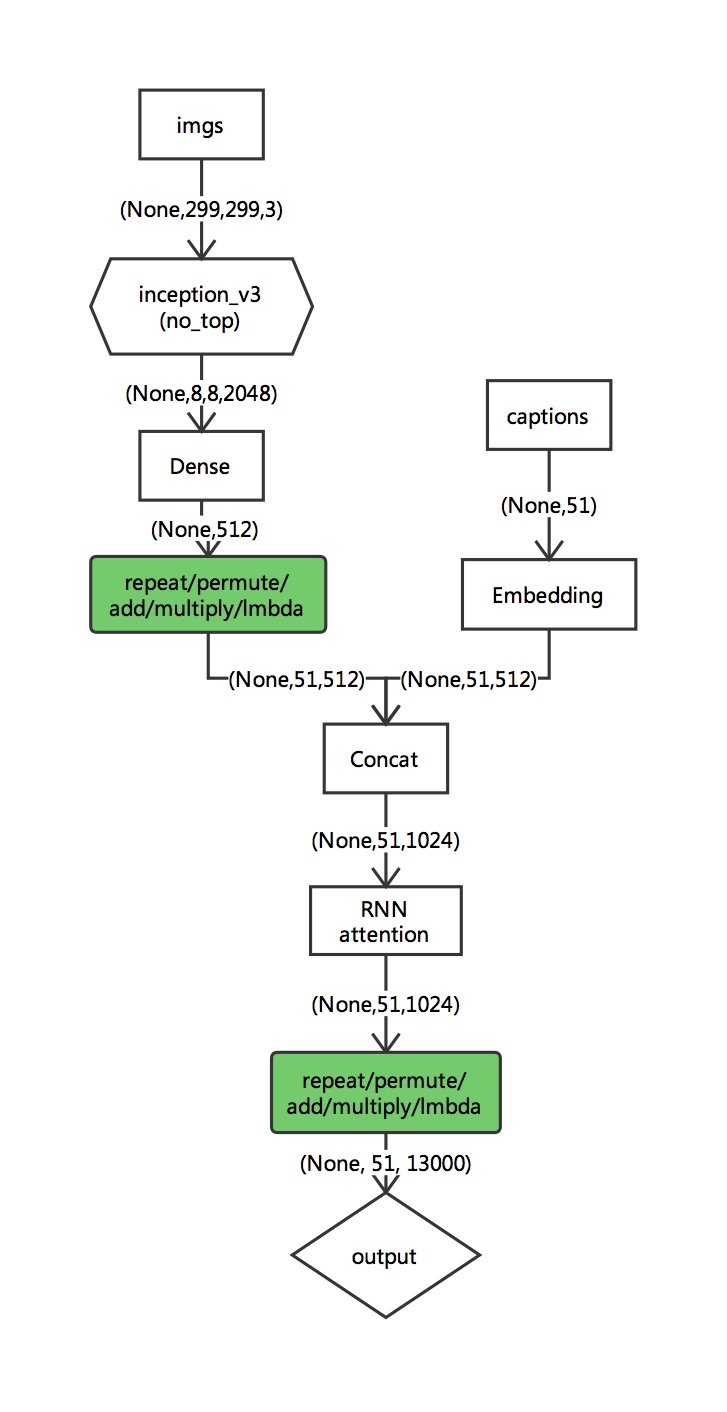
在我的模型中caption的长度直接拉长到了51维(上面提到的模型是40维)图像部分基模型使用inception_V3. 最后的输出部分的shape为(None,51,13000)。具体训练样本制作的过程如下:
例如:caption = {a person on a skateboard and bike at a skate park.}
input_seq = {<BOS> a person on a skateboard and bike at a skate park. } #长度不够51补0
target_seq = {a person on a skateboard and bike at a skate park. <BOS> } #长度不够51补0
训练样本即为:X = [ img(299,299,3), input_seq ] Y = [ target_seq ]
这是训练部分。 但对于测试部分X没有input_seq怎么办?
设X[0] = [img(299,299,3), "<BOS>"] 由X[0] 得到模型的预测结果P[0].
X[1] = [img(299,299,3), "<BOS> P[0][0]"], 由X[1] 得到模型的预测结果P[1].
X[2] = [img(299,299,3), "<BOS> P[0][0] P[1][1]"], 由X[2] 得到模型的预测结果P[2].
当P[k+1][k+1]==<EOS>时停止对该img的预测。{P[0][0],P[1][1],...,P[k][k]}即为所求。















 8302
8302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









