






深度神经网络在多个领域的成功促使人们对如何有效地部署这些模型以用于实际应用进行了大量思考和努力。然而,尽管基于树的模型(包括随机森林和梯度增强模型)在表格数据分析中 continued dominance 非常重要,而且对于解释性非常重要的用例非常重要,但加速部署基于树的模型(包括随机森林和梯度增强模型)的努力却没有受到太多关注。
随着 DoorDash 和 CapitalOne 等组织转向基于树的模型来分析大量关键任务数据,提供工具以帮助部署此类模型变得简单、高效和高效变得越来越重要。
NVIDIA Triton 推理服务器 提供在 CPU 和 GPU 上部署深度学习模型的完整解决方案,支持多种框架和模型执行后端,包括 PyTorch 、 TensorFlow 、 ONNX 、 TensorRT 等。从 21.06.1 版开始,为了补充 NVIDIA Triton 推理服务器现有的深度学习功能,新的 林推理库( FIL )后端 提供了对树模型的支持,例如 XGBoost 、 LightGBM 、 Scikit-Learn RandomForest , RAPIDS 卡米尔森林 ,以及 Treelite 支持的任何其他型号。
基于 RAPIDS 森林推理库 (NVIDIA ),NVIDIA Triton 推理服务器 FIL 后端允许用户利用 NVIDIA Triton 推理服务器的相同特性,以达到 deep learning 模型的最优吞吐量/延迟,以在相同的系统上部署基于树的模型。
在本文中,我们将简要介绍NVIDIA Triton 推理服务器本身,然后深入介绍如何使用 FIL 后端部署 XGBOOST 模型的示例。使用 NVIDIA GPU ,我们将看到,我们不必总是在部署更精确的模型或保持延迟可控之间做出选择。
在示例笔记本中,通过利用 FIL 后端的 GPU 加速推理,在一台配备八台 V100 GPU 的 NVIDIA DGX-1 服务器上,我们将能够部署比 CPU 更复杂的欺诈检测模型,同时将 p99 延迟保持在 2ms 以下, still 每秒提供超过 400K 的推断( 630MB / s ),或者比 CPU 上的吞吐量高 20 倍。
NVIDIA Triton 推理服务器
NVIDIA Triton 推理服务器为 machine learning 模型的实时服务提供了完整的开源解决方案。 NVIDIA Triton 推理服务器旨在使性能模型部署过程尽可能简单,它为在实际应用中尝试部署 ML 算法时遇到的许多最常见问题提供了解决方案,包括:
- 多框架 支持 : 支持所有最常见的深度学习框架和序列化格式,包括 PyTorch 、 TensorFlow 、 ONNX 、 TensorRT 、 OpenVINO 等。随着 FIL 后端的引入, NVIDIA Triton 推理服务器还提供对 XGBoost 、 LightGBM 、 Scikit Learn / cuML RandomForest 和任何框架中的 Treelite 序列化模型的支持。
- Dynamic Batching : 允许用户指定一个批处理窗口,并将在该窗口中收到的任何请求整理成更大的批处理,以优化吞吐量。
- 多种查询类型 :优化多种查询类型的推理:实时、批处理、流式,还支持模型集成。
- 使用 NVIDIA 管道和集合 推理服务器部署的 管道和集合 Triton 型号可以通过复杂的管道或集成进行连接,以避免客户端和服务器之间,甚至主机和设备之间不必要的数据传输。
- CPU 模型执行 : 虽然大多数用户希望利用 GPU 执行带来的巨大性能提升,但 NVIDIA Triton 推理服务器允许您在 CPU 或 GPU 上运行模型,以满足您的特定部署需求和资源可用性。
- Dynamic Batching [VZX337 ]如果NVIDIA Triton 推理服务器不提供对部分管道的支持,或者如果需要专门的逻辑将各种模型链接在一起,则可以使用自定义 Python 或C++后端精确地添加所需的逻辑。
- Run anywhere :在扩展的云或数据中心、企业边缘,甚至在嵌入式设备上。它支持用于人工智能推理的裸机和虚拟化环境(如 VMware vSphere )。
- Kubernetes 和 AI 平台支持 :
- 作为 Docker 容器提供,并可轻松与 Kubernetes 平台集成,如 AWS EKS 、谷歌 GKE 、 Azure AKS 、阿里巴巴 ACK 、腾讯 TKE 或红帽 OpenShift 。
- 可在 Amazon SageMaker 、 Azure ML 、 Google Vertex AI 、阿里巴巴 AI 弹性算法服务平台和腾讯 TI-EMS 等托管 CloudAI 工作流平台上使用。
- Enterprise support : NVIDIA AI 企业软件套件包括对 NVIDIA Triton 推理服务器的全面支持,例如访问 NVIDIA AI 专家以获得部署和管理指导、安全修复和维护发布的优先通知、长期支持( LTS )选项和指定的支持代理。
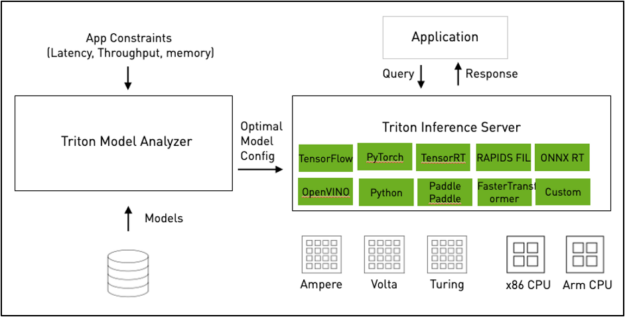
图 1:NVIDIA Triton 推理服务器架构图.
为了更好地了解如何利用 FIL 后端的这些特性来部署树模型,我们来看一个特定的用例。
示例: FIL 后端的欺诈检测
为了在 NVIDIA Triton 推理服务器中部署模型,我们需要一个配置文件,指定有关部署选项和序列化模型本身的一些细节。模型当前可以按以下任意格式序列化:
- XGBoost 二进制格式
- XGBoost JSON
- LightGBM 文本格式
- Treelite 二进制检查点文件
在下面的笔记本中,我们将介绍部署欺诈检测模型过程的每个步骤,从培训模型到编写配置文件以及优化部署参数。在此过程中,我们将演示 GPU 部署如何在保持最小延迟的同时显著提高吞吐量。此外,由于 FIL 可以轻松地扩展到非常大和复杂的模型,而不会大幅增加延迟,因此我们将看到,对于任何给定的延迟预算,在 GPU 上部署比 CPU 上更复杂和准确的模型是可能的。
正如我们在本笔记本中所看到的, NVIDIA Triton 推理服务器的 FIL 后端允许我们使用序列化的模型文件和简单的配置文件轻松地为树模型提供服务。如果没有 NVIDIA Triton 推理服务器,那些希望服务于其他框架中的 XGBoost 、 LightGBM 或随机林模型的人通常会求助于吞吐量延迟性能差且不支持多个框架的手动摇瓶服务器。 NVIDIA Triton 推理服务器的动态批处理和并发模型执行自动最大化吞吐量,模型分析器有助于选择最佳部署配置。手动选择可能需要数百种组合,并且可能会延迟模型的展开。有了 FIL 后端,我们可以为来自所有这些框架的模型提供服务,而无需定制代码和高度优化的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









