







目录
大语言模型(LLMs)的领域自适应预训练(DAPT)是构建特定领域模型的重要步骤。与现成的开放或商用模型相比,这些模型在特定领域任务中表现出更出色的功能。
最近,NVIDIA 发表了一篇关于 ChipNeMo 的论文,这是一系列面向工业芯片设计应用的基础模型。ChipNeMo 模型是通过在专有数据和公开可用的特定领域数据的语料库上对 Llama 2 系列模型进行持续预训练的结果。
本文将以 ChipNeMo 数据集为例,介绍使用 NVIDIA NeMo Curator 从各种公开来源收集训练数据集的过程。
NeMo Curator
NeMo Curator 是一个 GPU 加速的数据 curation 库,通过准备用于预训练和自定义的大规模、高质量数据集来提高生成式 AI 模型的性能。
NeMo Curator 通过扩展到多节点多 GPU (MNMG) 来缩短数据处理时间,并支持大型预训练数据集的准备。它提供了从 Common Crawl、Wikipedia 和 arXiv 等开箱即用的各种公共来源下载和整理数据的工作流程。
它还为您提供了自定义数据采集流程的灵活性,以满足它们独特的要求,并创建自定义数据集。
有关基本构建块的更多信息,请参阅“使用 NVIDIA NeMo Curator 为 LLM 训练整理自定义数据集”的教程。
ChipNeMo
ChipNeMo 的大部分训练语料库包括来自 Wikipedia、开源 GitHub 资源库以及 arXiv 出版物的数据。
图 1 显示数据 curation 管道涉及以下高级步骤:
- Acquiring data:
- 下载相关的维基百科文章,并将其转换为JSONL文件。
- 克隆相关的 GitHub 资源库,确定所有相关的源代码文件,并将其转换为 JSONL 文件。
- 从 arXiv 下载 PDF 格式的论文,并将其转换为 JSONL 文件。
- 使用现有工具统一 Unicode 表征和特殊字符。
- 定义自定义过滤器以删除过短、过长、重复或不相关的记录。
- 从数据集中编辑所有个人身份信息(PII)。
- 根据元数据整理数据,并将结果写入磁盘。
- (可选) 混合和混洗数据。
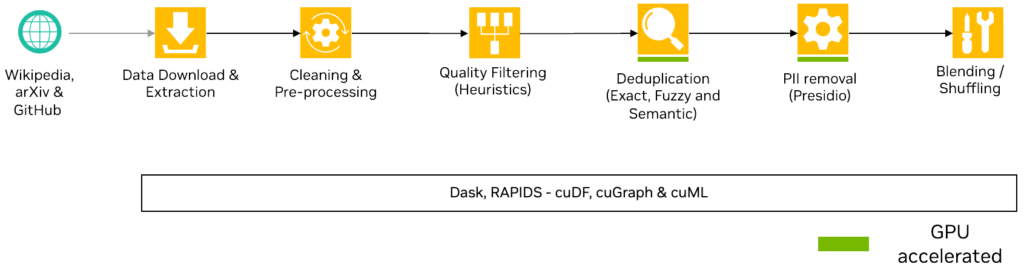
图 1. 处理数据以训练特定领域的LLMs
要访问本教程的完整代码,请参阅 NVIDIA/NeMo-Curator GitHub 资源库。
预备知识
开始之前,请按照 NeMo Curator 的 GitHub README 文件中的说明安装 NeMo Curator。
本教程还依赖于 Tesseract 库来启用 PDF 解析功能,您可以通过获取二进制文件或操作系统的包管理器来安装该功能。
之后,在终端运行以下命令以验证安装。此外,安装后续操作所需的依赖项
$ sudo apt install tesseract-ocr # For Debian-based Linux distros $ pip install nemo-curator $ python -c "import nemo_curator; print(nemo_curator);" $ pip3 install -r requirements.txt
数据采集
我们提供了 ChipNeMo 训练语料库中使用的 Wikipedia 文章、GitHub 资源库和 arXiv 出版物的列表,并演示了如何将这些数据转换为 JSONL。
转换过程因数据源而异:
- 对于维基百科文章,请解析网页以提取主要内容。
- 对于 arXiv 出版物,请将 PDF 文件解析为纯文本。
- 对于 GitHub 资源库,请识别相关的源代码文件,并忽略不相关的数据。
如前文教程所述,整理数据集的第一步是实现可下载并迭代数据集的文档构建器。
要使用 Dask 的并行性,请将文档构建器实现插入 NeMo Curator 提供的 download_and_extract 辅助程序。这辅助程序使用 Dask 工作器并行下载和解析数据,从而在处理多个数据源时显著加快该过程。
文档构建器实现
首先,实现 DocumentDownloader 类,该类获取数据集的 URL 并使用 requests 库进行下载。目前,重点关注下载和解析 GitHub 资源库的任务。您稍后也可以类似地获取 Wikipedia 和 arXiv 数据。
要高效获取 GitHub 资源库,请将其下载为 .zip 存档,而不是通过 git 命令进行克隆。此方法速度更快,并且节省了磁盘空间,因为您可以直接处理 .zip 文件。
要下载 .zip 版本的资源库,请确定该资源库的主分支的名称。在生产流水线中,最好直接查询 GitHub API,并为每个资源库找出主分支。由于 API 通常受速率限制并需要身份验证,因此我们展示了如何尝试一些不同的常见分支名称,以查看哪些分支有效:例如,尝试 “main”、”master” 或 “develop” 等。
import requests
from nemo_curator.download.doc_builder import DocumentDownloader
class GitHubDownloader(DocumentDownloader):
"""
A class for downloading repositories from GitHub.
"""
def __init__(self, github_root_dir: str):
"""
Initializes the DocBuilder object.
Args:
github_root_dir: The root directory for GitHub repositories.
"""
super().__init__()
# The path under which the repositories will be cloned.
self.clone_root_dir = os.path.join(github_root_dir, "repos")
os.makedirs(github_root_dir, exist_ok=True)
os.makedirs(self.clone_root_dir, exist_ok=True)
def download(self, url: str) -> str:
"""
Download a repository as a z
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









