







一、安装
1.1、环境
- 系统:mac
- java 版本:java -version
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
- flink 版本:1.10.0
1.2、启动
- 执行命令 ./apache-flink-1.10.0/deps/bin/start-cluster.sh
- 访问:http://127.0.0.1:8081/#/overview
二、写一个demo
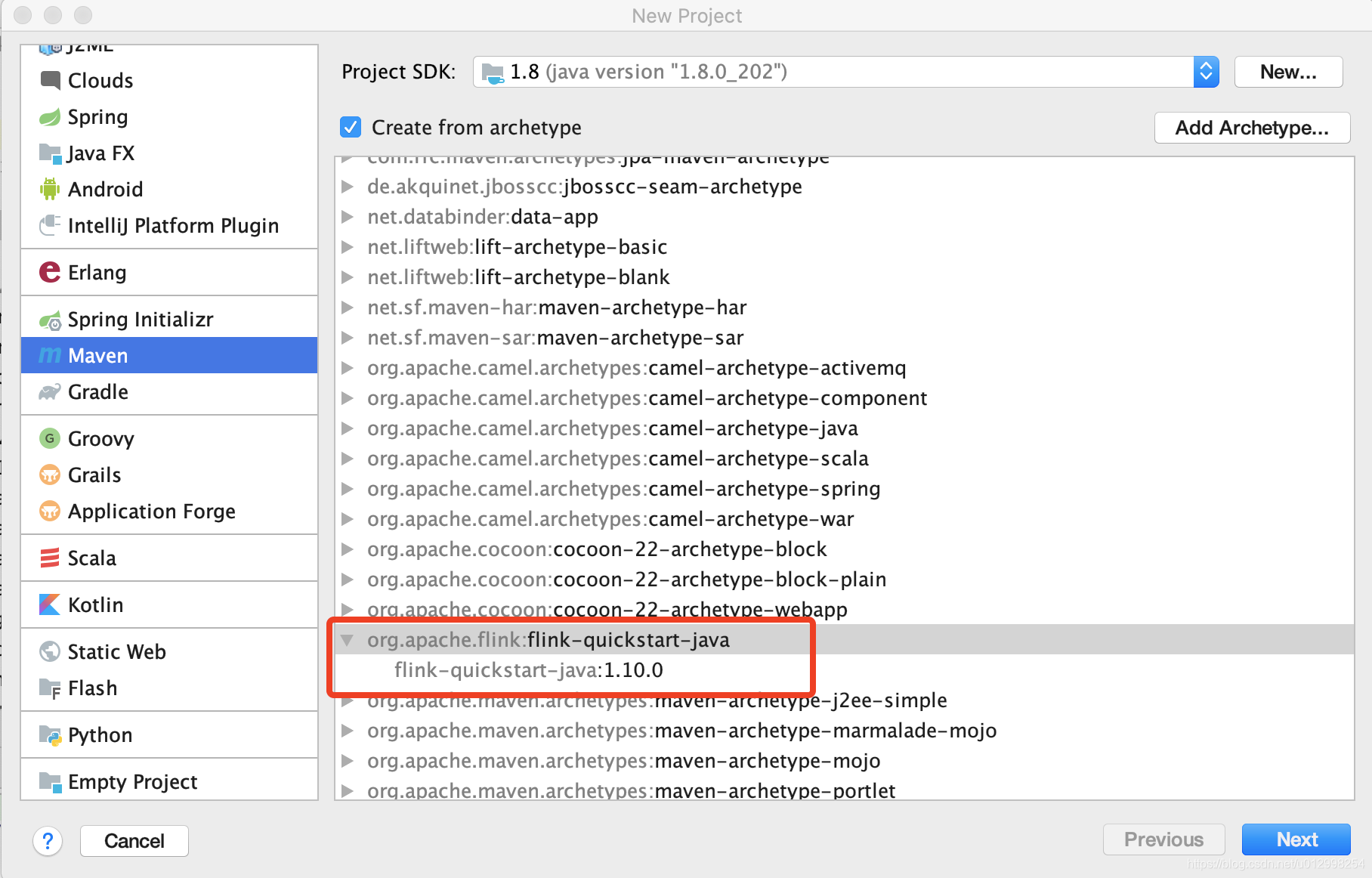
2.1 在idea上建一个工程,选择这个archetype
2.2 coding
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class WordCountExample {
public static void main(String[] args) throws Exception {
//构建环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//通过字符串构建数据集
DataSet<String> text = env.fromElements(
"this is the first example about flink");
//分割字符串、按照key进行分组、统计相同的key个数
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
//打印
wordCounts.print();
}
//分割字符串的方法
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
3. 执行
3.1 在idea上运行
出现报错
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/api/common/functions/FlatMapFunction
在pom去掉关于flink的依赖的scope,改为如下
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
在执行一次,截取一部分日志:

3.2 命令提交给Apache Flink Dashboard
1、给程序的jar,copy到./apache-flink-1.10.0/deps/examples目录下
2、然后提交执行命令
./bin/flink run -c com.learn.fink.WordCountExample ../examples/flink_example-1.0.0-SNAPSHOT.jar
3、执行结果

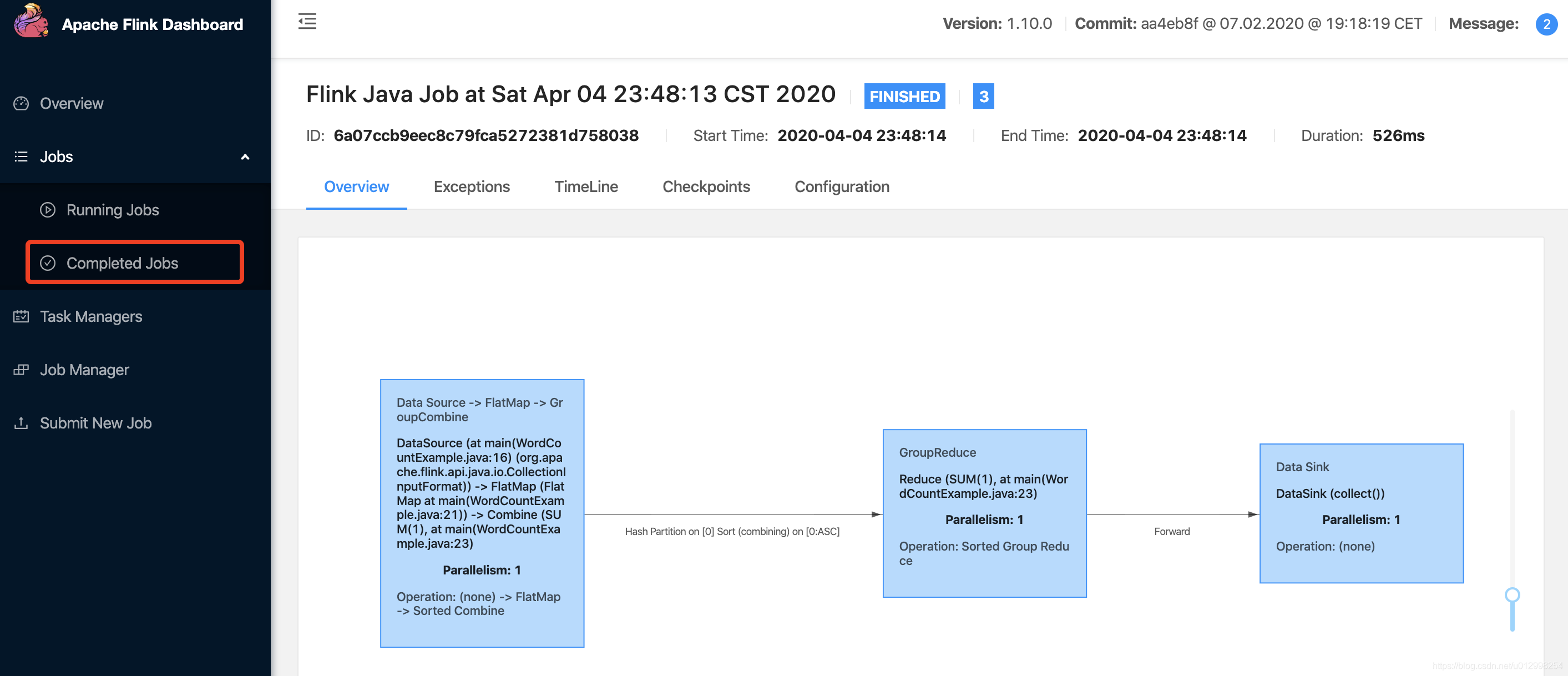
3.3 在Apache Flink Dashboard上执行
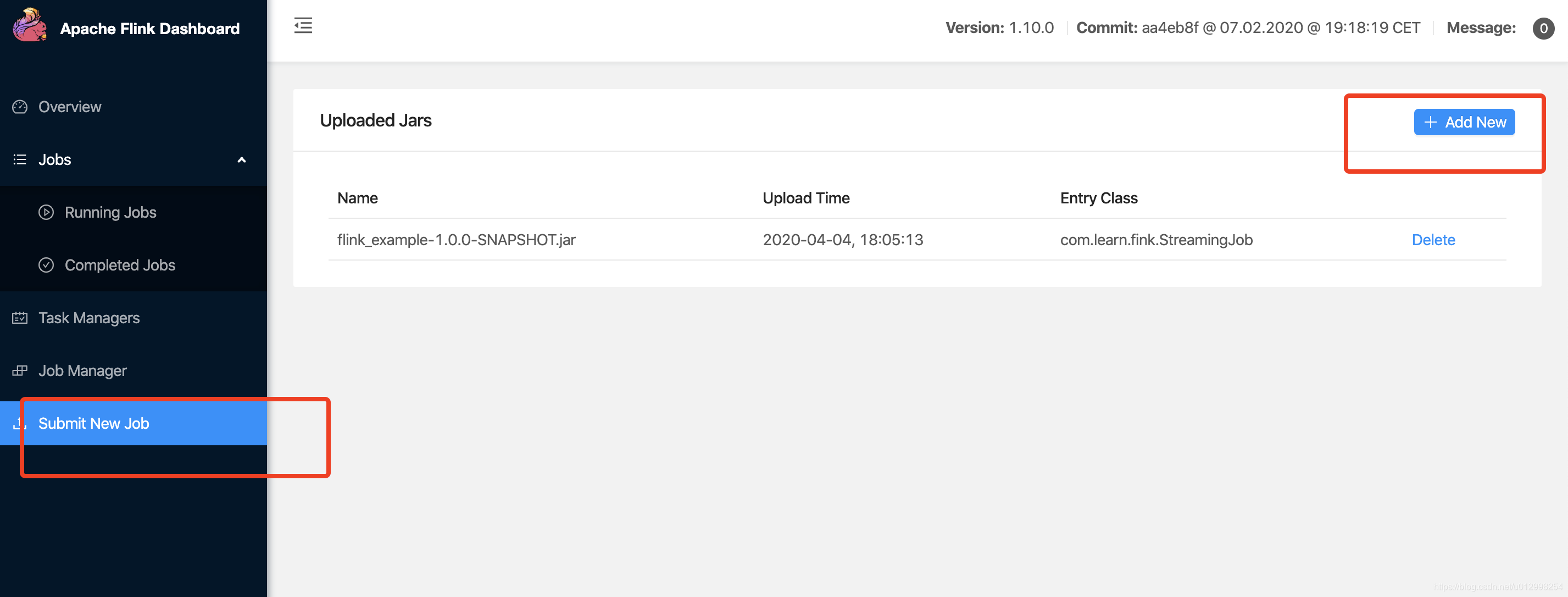
点击Add New,可以上传jar,然后点击submit
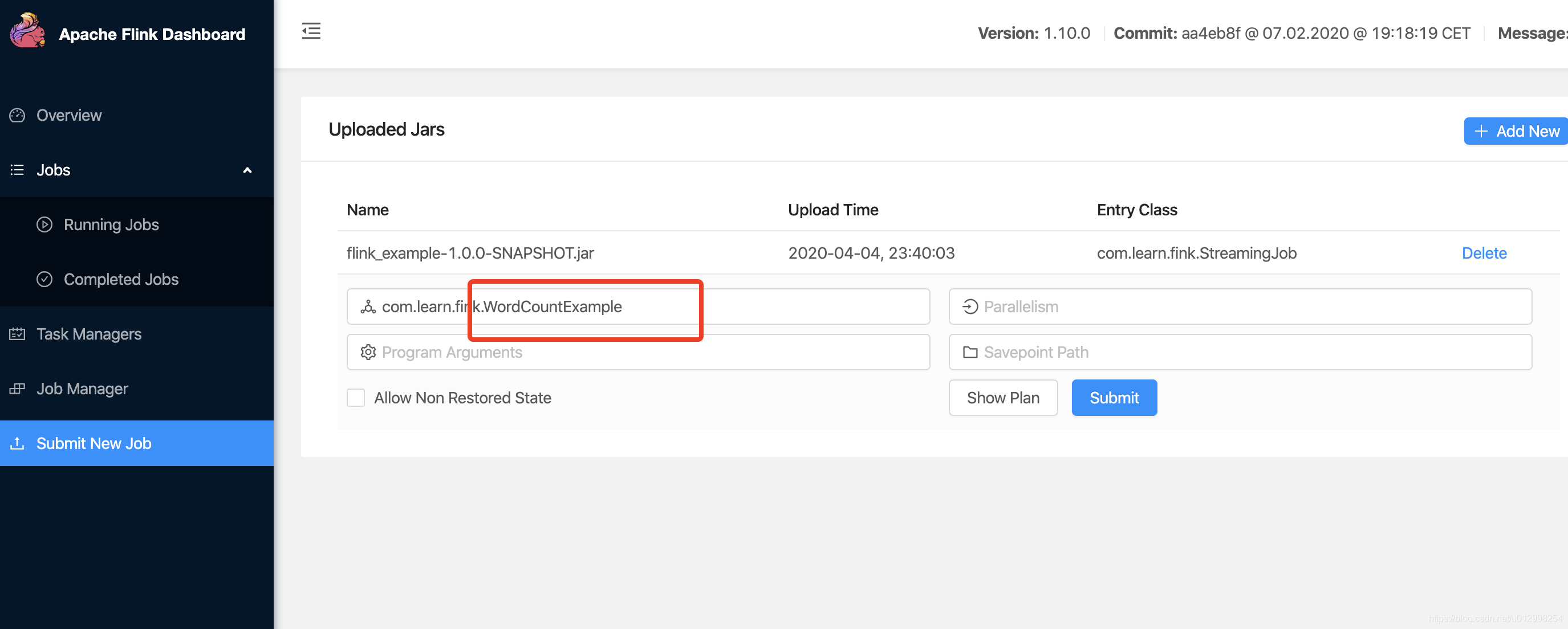
可以看到结果为














 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









